alphafold2
v0.4.32
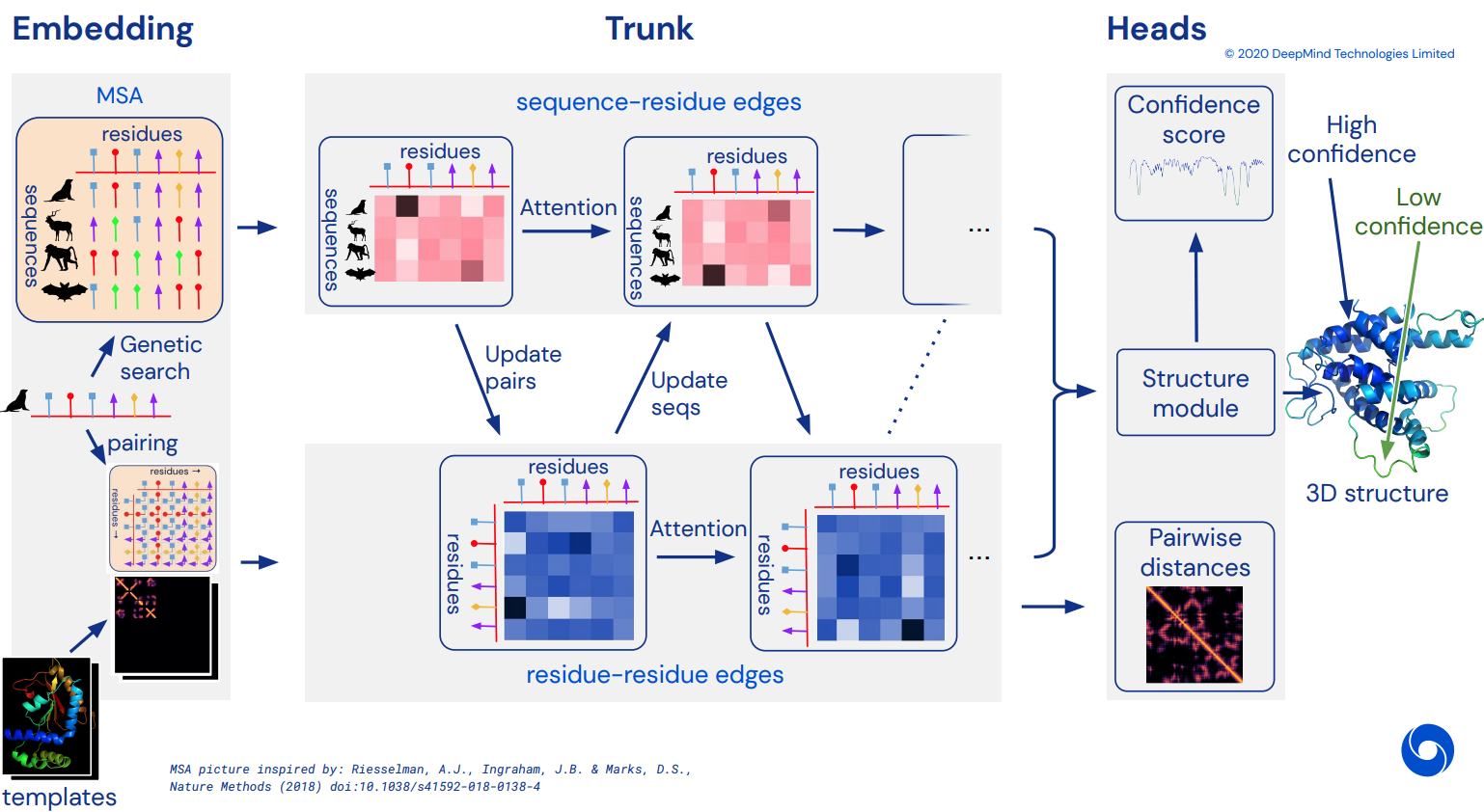
最終成為 Alphafold2 的非官方工作 Pytorch 實現,Alphafold2 是解決 CASP14 問題的令人驚嘆的注意力網絡。隨著更多架構細節的發布,將逐步實現。
一旦複製完成,我打算在電腦中折疊所有可用的氨基酸序列,並將其作為學術洪流發布,以進一步促進科學發展。如果您對複製工作感興趣,請造訪此 Discord 頻道的 #alphafold
更新:Deepmind 開源了 Jax 中的官方程式碼以及權重!該儲存庫現在將面向直接 pytorch 翻譯,並對位置編碼進行一些改進
ArxivInsights 視頻
$ pip install alphafold2-pytorchlhatsk 已報告使用與 trRosetta 相同的設定來訓練該儲存庫的修改後的主幹,並取得了有競爭力的結果
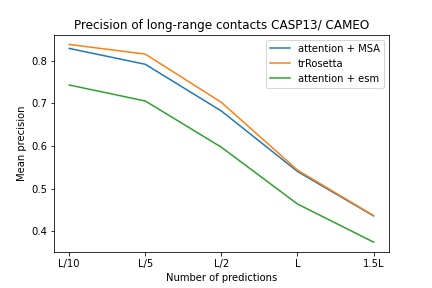
blue used the the trRosetta input (MSA -> potts -> axial attention), green used the ESM embedding (only sequence) -> tiling -> axial attention - lhatsk
預測直方圖,類似 Alphafold-1,但需要注意
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
reversible = False # set this to True for fully reversible self / cross attention for the trunk
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda () # AA length of 128
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda () # MSA doesn't have to be the same length as primary sequence
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (1, 128, 128, 37)您也可以透過在 init 上傳遞predict_angles = True來開啟角度預測。下面的範例相當於 trRosetta 但具有自我/交叉注意力。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
predict_angles = True # set this to True
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram , theta , phi , omega = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
)
# distogram - (1, 128, 128, 37),
# theta - (1, 128, 128, 25),
# phi - (1, 128, 128, 13),
# omega - (1, 128, 128, 25) Fabian 最近的論文建議將座標迭代回饋回 SE3 Transformer,共享權重,可能會起作用。我決定根據這個想法來執行,儘管它的實際運作方式仍然懸而未決。
您也可以使用 E(n)-Transformer 或 EGNN 進行結構性細化。
更新:Baker 的實驗室已經證明,從序列和 MSA 嵌入到 SE3 Transformer 的端到端架構可以最好地超越 trRosetta,並縮小與 Alphafold2 的差距。我們將使用作用於主幹嵌入的圖形轉換器來產生要傳送到等變網路的初始座標集。 (Costa 等人在 Baker 實驗室發表之前的一篇論文中從 MSA Transformer 嵌入中梳理出 3D 座標,進一步證實了這一點)
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
predict_coords = True ,
structure_module_type = 'se3' , # use SE3 Transformer - if set to False, will use E(n)-Transformer, Victor and Max Welling's new paper
structure_module_dim = 4 , # se3 transformer dimension
structure_module_depth = 1 , # depth
structure_module_heads = 1 , # heads
structure_module_dim_head = 16 , # dimension of heads
structure_module_refinement_iters = 2 , # number of equivariant coordinate refinement iterations
structure_num_global_nodes = 1 # number of global nodes for the structure module, only works with SE3 transformer
). cuda ()
seq = torch . randint ( 0 , 21 , ( 2 , 64 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 2 , 5 , 60 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
coords = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (2, 64 * 3, 3) <-- 3 atoms per residue 基本假設是主幹在殘差級別上工作,然後構成結構模組的原子級別,無論是 SE3 Transformers、E(n)-Transformer 或 EGNN 進行細化。該庫預設使用 3 個主鏈原子(C、Ca、N),但您可以將其配置為包含您喜歡的任何其他原子,包括 Cb 和側鏈。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
predict_coords = True ,
atoms = 'backbone-with-cbeta'
). cuda ()
seq = torch . randint ( 0 , 21 , ( 2 , 64 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 2 , 5 , 60 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
coords = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (2, 64 * 4, 3) <-- 4 atoms per residue (C, Ca, N, Cb) atoms的有效選擇包括:
backbone - 3 個主鏈原子(C、Ca、N)[預設]backbone-with-cbeta - 3 個骨幹原子和 C betabackbone-with-oxygen - 3 個主鏈原子和來自羧基的氧backbone-with-cbeta-and-oxygen - 3 個具有 Cβ 和氧的主鏈原子all - 主鏈和側鏈的所有其他原子您也可以傳入形狀為 (14,) 的張量,定義您想要包含哪些原子
前任。
atoms = torch . tensor ([ 1 , 1 , 1 , 1 , 1 , 1 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 1 ])這個儲存庫為您提供了透過 Facebook AI 預先訓練的嵌入來輕鬆補充網路的方法。它包含預先訓練的 ESM、MSA Transformer 或 Protein Transformer 的包裝。
有一些先決條件。您需要確保安裝了 Nvidia 的 apex 庫,因為預先訓練的 Transformer 使用一些融合操作。
或者您可以嘗試運行下面的腳本
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./接下來,您只需使用ESMEmbedWrapper 、 MSAEmbedWrapper或ProtTranEmbedWrapper匯入並包裝您的Alphafold2實例,它將負責為您嵌入序列和多序列比對(並將其投影到您的模型)。除了添加包裝器之外,不需要進行任何更改。
import torch
from alphafold2_pytorch import Alphafold2
from alphafold2_pytorch . embeds import MSAEmbedWrapper
alphafold2 = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64
)
model = MSAEmbedWrapper (
alphafold2 = alphafold2
). cuda ()
seq = torch . randint ( 0 , 21 , ( 2 , 16 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa = torch . randint ( 0 , 21 , ( 2 , 5 , 16 )). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
)預設情況下,即使包裝器向主幹提供序列和 MSA 嵌入,它們也會與通常的令牌嵌入相加。如果您想在沒有令牌嵌入的情況下訓練 Alphafold2(僅依賴預訓練的嵌入),則需要在Alphafold2初始化時將disable_token_embed設為True 。
alphafold2 = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
disable_token_embed = True
)Jinbo Xu 的一篇論文表明,不需要對距離進行分類,而是可以直接預測平均值和標準差。您可以透過開啟一個標誌predict_real_value_distances來使用此功能,在這種情況下,傳回的距離預測的平均值和標準差的維度將分別為2 。
如果predict_coords也打開,則 MDS 將直接接受平均值和標準差預測,而無需從分佈圖箱中進行計算。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
predict_coords = True ,
predict_real_value_distances = True , # set this to True
structure_module_type = 'se3' ,
structure_module_dim = 4 ,
structure_module_depth = 1 ,
structure_module_heads = 1 ,
structure_module_dim_head = 16 ,
structure_module_refinement_iters = 2
). cuda ()
seq = torch . randint ( 0 , 21 , ( 2 , 64 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 2 , 5 , 60 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
coords = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (2, 64 * 3, 3) <-- 3 atoms per residue 您可以為主序列和 MSA 新增卷積塊,只需設定額外的關鍵字參數use_conv = True
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
use_conv = True # set this to True
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (1, 128, 128, 37)卷積核遵循本文的思路,將 1d 和 2d 核組合在一個類似 resnet 的區塊中。您可以完全自訂內核。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
use_conv = True , # set this to True
conv_seq_kernels = (( 9 , 1 ), ( 1 , 9 ), ( 3 , 3 )), # kernels for N x N primary sequence
conv_msa_kernels = (( 1 , 9 ), ( 3 , 3 )), # kernels for {num MSAs} x N MSAs
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (1, 128, 128, 37)您也可以使用一個額外的關鍵字參數進行循環擴張。所有層的預設膨脹均為1 。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
use_conv = True , # set this to True
dilations = ( 1 , 3 , 5 ) # cycle between dilations of 1, 3, 5
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (1, 128, 128, 37)最後,您可以使用custom_block_types關鍵字自訂您想要的任何順序,而不是遵循卷積、自註意力、每個深度重複的交叉注意力的模式
前任。首先主要進行卷積,然後是自註意力 + 交叉注意力塊的網絡
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
heads = 8 ,
dim_head = 64 ,
custom_block_types = (
* (( 'conv' ,) * 6 ),
* (( 'self' , 'cross' ) * 6 )
)
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 128 )). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 5 , 120 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask
) # (1, 128, 128, 37) 您可以使用 Microsoft Deepspeed 的 Sparse Attention 進行訓練,但您必須忍受安裝過程。這是兩步。
首先,需要安裝 Deepspeed with Sparse Attention
$ sh install_deepspeed.sh接下來,您需要安裝 pip 套件triton
$ pip install triton如果上述兩項都成功,那麼現在您可以使用稀疏注意力進行訓練!
遺憾的是,稀疏注意力僅支持自註意力,而不支持交叉注意力。我將引入一個不同的解決方案來提高交叉注意力的表現。
model = Alphafold2 (
dim = 256 ,
depth = 12 ,
heads = 8 ,
dim_head = 64 ,
max_seq_len = 2048 , # the maximum sequence length, this is required for sparse attention. the input cannot exceed what is set here
sparse_self_attn = ( True , False ) * 6 # interleave sparse and full attention for all 12 layers
). cuda ()我還添加了最好的線性注意力變體之一,希望減輕交叉注意力的負擔。我個人還沒有發現 Performer 工作得那麼好,但由於他們在論文中報告了一些蛋白質基準的不錯的數字,我想我應該包括它並允許其他人進行實驗。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
cross_attn_linear = True # simply set this to True to use Performer for all cross attention
). cuda ()您也可以透過傳入與深度相同長度的元組來指定您希望使用線性注意力的確切層
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 6 ,
heads = 8 ,
dim_head = 64 ,
cross_attn_linear = ( True , False ) * 3 # interleave linear and full attention
). cuda ()本文建議,如果您有定義軸的查詢或上下文(例如一張圖像),您可以透過對這些軸(高度和寬度)進行平均並將平均軸連接成一個序列來減少所需的注意力。您可以將其打開作為交叉注意的內存節省技術,特別是對於主序列。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 6 ,
heads = 8 ,
dim_head = 64 ,
cross_attn_kron_primary = True # make sure primary sequence undergoes the kronecker operator during cross attention
). cuda ()如果您的 MSA 對齊且寬度相同,您也可以在交叉關注期間使用cross_attn_kron_msa標誌將相同的運算子應用於 MSA。
托多
為了節省交叉注意力的內存,您可以按照本文中列出的方案設定鍵/值的壓縮比。 2-4 的壓縮比通常是可以接受的。
model = Alphafold2 (
dim = 256 ,
depth = 12 ,
heads = 8 ,
dim_head = 64 ,
cross_attn_compress_ratio = 3
). cuda ()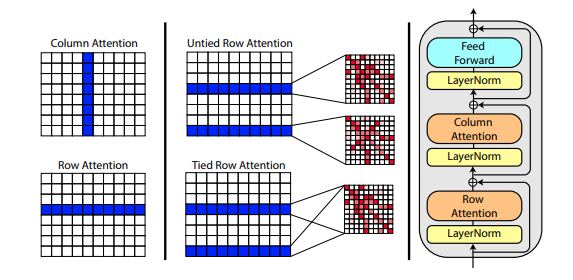
Roshan Rao 的一篇新論文提出使用軸向注意力對 MSA 進行預訓練。鑑於強勁的結果,該儲存庫將在主幹中使用相同的方案,專門用於 MSA 自註意力。
您也可以在初始化Alphafold2時將 MSA 的行注意力與msa_tie_row_attn = True設定連結起來。但是,為了使用此功能,您必須確保如果每個主序列的 MSA 數量不均勻,則對於未使用的行,MSA 遮罩已正確設定為False 。
model = Alphafold2 (
dim = 256 ,
depth = 2 ,
heads = 8 ,
dim_head = 64 ,
msa_tie_row_attn = True # just set this to true
)模板處理也主要透過軸向注意力完成,交叉注意力沿著模板維度的數量完成。這很大程度上遵循與最近的全注意力視訊分類方法相同的方案,如此處所示。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 5 ,
heads = 8 ,
dim_head = 64 ,
reversible = True ,
sparse_self_attn = False ,
max_seq_len = 256 ,
cross_attn_compress_ratio = 3
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 16 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 10 , 16 )). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
templates_seq = torch . randint ( 0 , 21 , ( 1 , 2 , 16 )). cuda ()
templates_coors = torch . randint ( 0 , 37 , ( 1 , 2 , 16 , 3 )). cuda ()
templates_mask = torch . ones_like ( templates_seq ). bool (). cuda ()
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask ,
templates_seq = templates_seq ,
templates_coors = templates_coors ,
templates_mask = templates_mask
)如果側鏈資訊也存在,以每個殘基的 C 和 C-alpha 座標之間的單位向量的形式存在,您也可以如下傳遞它。
import torch
from alphafold2_pytorch import Alphafold2
model = Alphafold2 (
dim = 256 ,
depth = 5 ,
heads = 8 ,
dim_head = 64 ,
reversible = True ,
sparse_self_attn = False ,
max_seq_len = 256 ,
cross_attn_compress_ratio = 3
). cuda ()
seq = torch . randint ( 0 , 21 , ( 1 , 16 )). cuda ()
mask = torch . ones_like ( seq ). bool (). cuda ()
msa = torch . randint ( 0 , 21 , ( 1 , 10 , 16 )). cuda ()
msa_mask = torch . ones_like ( msa ). bool (). cuda ()
templates_seq = torch . randint ( 0 , 21 , ( 1 , 2 , 16 )). cuda ()
templates_coors = torch . randn ( 1 , 2 , 16 , 3 ). cuda ()
templates_mask = torch . ones_like ( templates_seq ). bool (). cuda ()
templates_sidechains = torch . randn ( 1 , 2 , 16 , 3 ). cuda () # unit vectors of difference of C and C-alpha coordinates
distogram = model (
seq ,
msa ,
mask = mask ,
msa_mask = msa_mask ,
templates_seq = templates_seq ,
templates_mask = templates_mask ,
templates_coors = templates_coors ,
templates_sidechains = templates_sidechains
)我已經準備好了 SE3 Transformer 的重新實現,正如 Fabian Fuchs 在一篇推測性部落格文章中所解釋的那樣。
此外,Victor 和 Welling 的一篇新論文使用 E(n) 等方差的不變特徵,在許多基準測試中達到了 SOTA 並優於 SE3 Transformer,同時速度更快。我採用了本文的主要思想,並將其修改為變壓器(增加了對功能和座標更新的關注)。
上述所有三個等變網路均已集成,只需設定一個超參數structure_module_type即可在儲存庫中使用以進行原子座標細化。
se3 SE3 變壓器
egnn
en E(n)-變壓器
引起讀者興趣的是,這三個框架中的每一個都已經過研究者對相關問題的驗證。
$ python setup.py test 該庫將使用 Jonathan King 在此存儲庫中的出色工作。謝謝喬納森!
我們還有 MSA 數據,全部價值約 3.5 TB,由擁有 The-Eye 專案的檔案管理員下載和託管。 (他們還託管 Eleuther AI 的數據和模型)如果您發現它們有幫助,請考慮捐贈。
$ curl -s https://the-eye.eu/eleuther_staging/globus_stuffs/tree.txthttps://xukui.cn/alphafold2.html
https://moalquraishi.wordpress.com/2020/12/08/alphafold2-casp14-it-feels-like-ones-child-has-left-home/

https://www.biorxiv.org/content/10.1101/2020.12.10.419994v1.full.pdf
https://pubmed.ncbi.nlm.nih.gov/33637700/
tFold 演示,來自騰訊 AI 實驗室
cd downloads_folder > pip install pyrosetta_wheel_filename.whlOpenMM 琥珀色
@misc { unpublished2021alphafold2 ,
title = { Alphafold2 } ,
author = { John Jumper } ,
year = { 2020 } ,
archivePrefix = { arXiv } ,
primaryClass = { q-bio.BM }
} @article { Rao2021.02.12.430858 ,
author = { Rao, Roshan and Liu, Jason and Verkuil, Robert and Meier, Joshua and Canny, John F. and Abbeel, Pieter and Sercu, Tom and Rives, Alexander } ,
title = { MSA Transformer } ,
year = { 2021 } ,
publisher = { Cold Spring Harbor Laboratory } ,
URL = { https://www.biorxiv.org/content/early/2021/02/13/2021.02.12.430858 } ,
journal = { bioRxiv }
} @article { Rives622803 ,
author = { Rives, Alexander and Goyal, Siddharth and Meier, Joshua and Guo, Demi and Ott, Myle and Zitnick, C. Lawrence and Ma, Jerry and Fergus, Rob } ,
title = { Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences } ,
year = { 2019 } ,
doi = { 10.1101/622803 } ,
publisher = { Cold Spring Harbor Laboratory } ,
journal = { bioRxiv }
} @article { Elnaggar2020.07.12.199554 ,
author = { Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and BHOWMIK, DEBSINDHU and Rost, Burkhard } ,
title = { ProtTrans: Towards Cracking the Language of Life{textquoteright}s Code Through Self-Supervised Deep Learning and High Performance Computing } ,
elocation-id = { 2020.07.12.199554 } ,
year = { 2021 } ,
doi = { 10.1101/2020.07.12.199554 } ,
publisher = { Cold Spring Harbor Laboratory } ,
URL = { https://www.biorxiv.org/content/early/2021/05/04/2020.07.12.199554 } ,
eprint = { https://www.biorxiv.org/content/early/2021/05/04/2020.07.12.199554.full.pdf } ,
journal = { bioRxiv }
} @misc { king2020sidechainnet ,
title = { SidechainNet: An All-Atom Protein Structure Dataset for Machine Learning } ,
author = { Jonathan E. King and David Ryan Koes } ,
year = { 2020 } ,
eprint = { 2010.08162 } ,
archivePrefix = { arXiv } ,
primaryClass = { q-bio.BM }
} @misc { alquraishi2019proteinnet ,
title = { ProteinNet: a standardized data set for machine learning of protein structure } ,
author = { Mohammed AlQuraishi } ,
year = { 2019 } ,
eprint = { 1902.00249 } ,
archivePrefix = { arXiv } ,
primaryClass = { q-bio.BM }
} @misc { gomez2017reversible ,
title = { The Reversible Residual Network: Backpropagation Without Storing Activations } ,
author = { Aidan N. Gomez and Mengye Ren and Raquel Urtasun and Roger B. Grosse } ,
year = { 2017 } ,
eprint = { 1707.04585 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { fuchs2021iterative ,
title = { Iterative SE(3)-Transformers } ,
author = { Fabian B. Fuchs and Edward Wagstaff and Justas Dauparas and Ingmar Posner } ,
year = { 2021 } ,
eprint = { 2102.13419 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { satorras2021en ,
title = { E(n) Equivariant Graph Neural Networks } ,
author = { Victor Garcia Satorras and Emiel Hoogeboom and Max Welling } ,
year = { 2021 } ,
eprint = { 2102.09844 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Gao_2020 ,
title = { Kronecker Attention Networks } ,
ISBN = { 9781450379984 } ,
url = { http://dx.doi.org/10.1145/3394486.3403065 } ,
DOI = { 10.1145/3394486.3403065 } ,
journal = { Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
publisher = { ACM } ,
author = { Gao, Hongyang and Wang, Zhengyang and Ji, Shuiwang } ,
year = { 2020 } ,
month = { Jul }
} @article { Si2021.05.10.443415 ,
author = { Si, Yunda and Yan, Chengfei } ,
title = { Improved protein contact prediction using dimensional hybrid residual networks and singularity enhanced loss function } ,
elocation-id = { 2021.05.10.443415 } ,
year = { 2021 } ,
doi = { 10.1101/2021.05.10.443415 } ,
publisher = { Cold Spring Harbor Laboratory } ,
URL = { https://www.biorxiv.org/content/early/2021/05/11/2021.05.10.443415 } ,
eprint = { https://www.biorxiv.org/content/early/2021/05/11/2021.05.10.443415.full.pdf } ,
journal = { bioRxiv }
} @article { Costa2021.06.02.446809 ,
author = { Costa, Allan and Ponnapati, Manvitha and Jacobson, Joseph M. and Chatterjee, Pranam } ,
title = { Distillation of MSA Embeddings to Folded Protein Structures with Graph Transformers } ,
year = { 2021 } ,
doi = { 10.1101/2021.06.02.446809 } ,
publisher = { Cold Spring Harbor Laboratory } ,
URL = { https://www.biorxiv.org/content/early/2021/06/02/2021.06.02.446809 } ,
eprint = { https://www.biorxiv.org/content/early/2021/06/02/2021.06.02.446809.full.pdf } ,
journal = { bioRxiv }
} @article { Baek2021.06.14.448402 ,
author = { Baek, Minkyung and DiMaio, Frank and Anishchenko, Ivan and Dauparas, Justas and Ovchinnikov, Sergey and Lee, Gyu Rie and Wang, Jue and Cong, Qian and Kinch, Lisa N. and Schaeffer, R. Dustin and Mill{'a}n, Claudia and Park, Hahnbeom and Adams, Carson and Glassman, Caleb R. and DeGiovanni, Andy and Pereira, Jose H. and Rodrigues, Andria V. and van Dijk, Alberdina A. and Ebrecht, Ana C. and Opperman, Diederik J. and Sagmeister, Theo and Buhlheller, Christoph and Pavkov-Keller, Tea and Rathinaswamy, Manoj K and Dalwadi, Udit and Yip, Calvin K and Burke, John E and Garcia, K. Christopher and Grishin, Nick V. and Adams, Paul D. and Read, Randy J. and Baker, David } ,
title = { Accurate prediction of protein structures and interactions using a 3-track network } ,
year = { 2021 } ,
doi = { 10.1101/2021.06.14.448402 } ,
publisher = { Cold Spring Harbor Laboratory } ,
URL = { https://www.biorxiv.org/content/early/2021/06/15/2021.06.14.448402 } ,
eprint = { https://www.biorxiv.org/content/early/2021/06/15/2021.06.14.448402.full.pdf } ,
journal = { bioRxiv }
}

