imagen pytorch
2.1.0
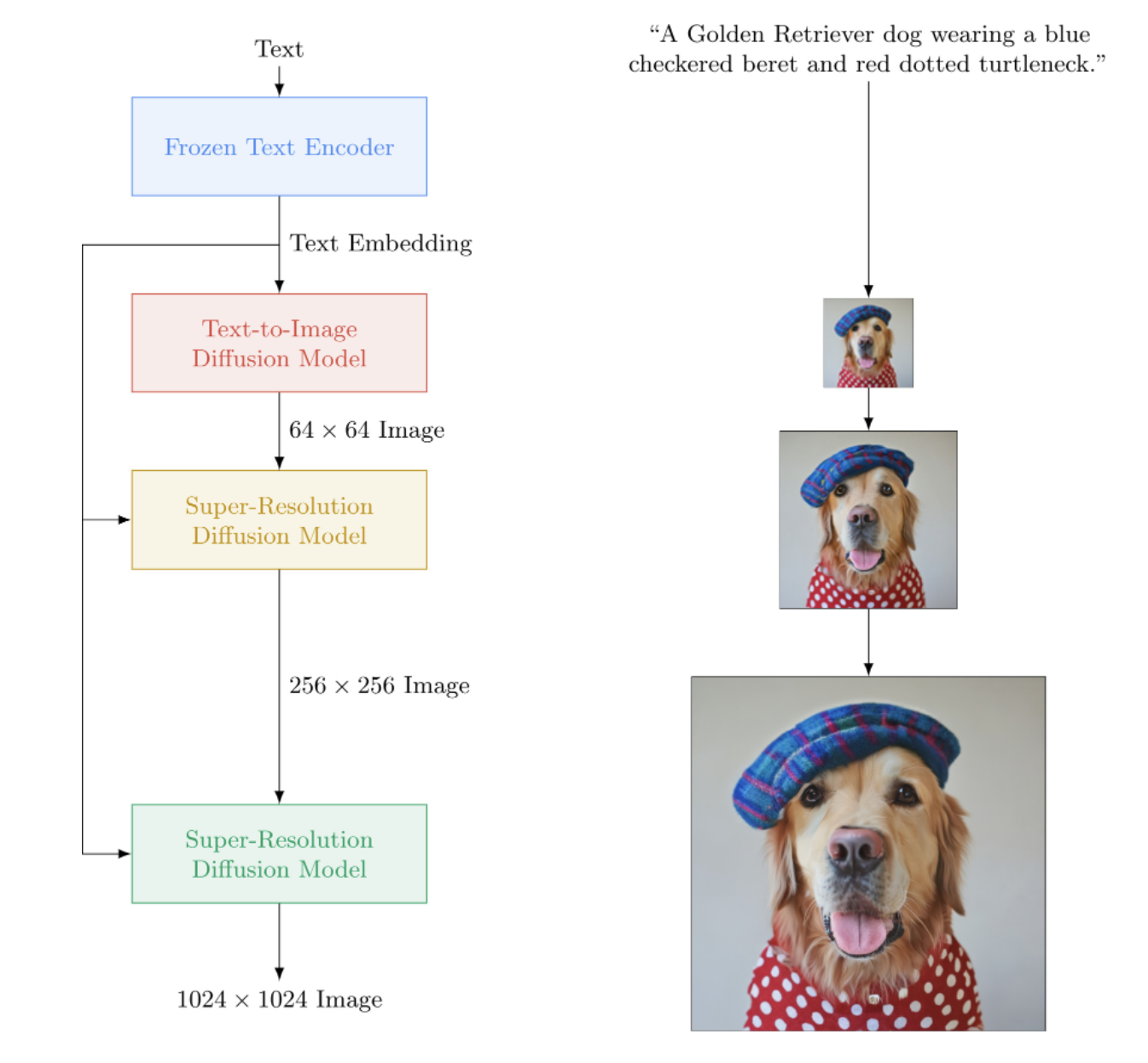
在 Pytorch 中實現 Imagen,這是谷歌的文本到圖像神經網絡,擊敗了 DALL-E2。它是用於文字到圖像合成的新 SOTA。
從架構上來說,它實際上比DALL-E2簡單得多。它由一個級聯 DDPM 組成,該 DDPM 以來自大型預訓練 T5 模型(注意力網絡)的文本嵌入為條件。它還包含用於改進分類器自由引導的動態裁剪、噪音水平調節和記憶體高效的 unet 設計。
看來 CLIP 和之前的網路都不再需要了。因此研究仍在繼續。
AI 與 Letitia 喝咖啡 |裝配人工智慧 |雅尼克·基爾徹
如果您有興趣幫助 LAION 社區進行複製,請加入
StabilityAI 以及我的其他贊助商的慷慨贊助
?擁抱他們令人驚嘆的變形金剛庫。由於它們,文字編碼器部分幾乎得到了處理
喬納森·何(Jonathan Ho)透過他的開創性論文帶來了生成人工智慧的革命
Sylvain 和 Zachary 的 Accelerate 庫,此儲存庫用於分散式訓練
Alex for einops,張量操作不可或缺的工具
Jorge Gomes 協助完成 T5 載入程式碼並提供有關正確 T5 版本的建議
Katherine Crowson,她的漂亮程式碼幫助我了解高斯擴散的連續時間版本
Marunine 和 Netruk44,用於審查程式碼、分享實驗結果並協助除錯
Marunine 為記憶體高效 u-net 中的色移問題提供了潛在的解決方案。感謝 Jacob 分享基本 unets 和記憶體高效 unets 之間的實驗比較
Marunine 發現了許多錯誤,解決了正確調整大小的問題,並分享了他的實驗配置和結果
MalumaDev 提議使用像素洗牌上採樣器來修復棋盤偽影
Valentin 指出unet中skip連結的不足,以及附錄中base-unet注意力調節的具體方法
BIGJUN 用於在推理時透過連續時間高斯擴散雜訊水平調節捕獲大錯誤
Bingbing 用於透過低解析度調節影像的取樣和歸一化順序以及雜訊來識別錯誤
Kay 貢獻了 Imagen 的一行命令訓練!
Hadrien Reynaud 在醫療資料集上測試文字到視頻,分享他的結果並發現問題!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)為了更簡單的訓練,您可以直接提供文字字串,而不是預先計算文字編碼。 (儘管出於縮放目的,您肯定會想要預先計算文字嵌入+遮罩)
如果您採用此方法,文字標題的數量必須與圖像的批次大小相符。
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward ()使用ImagenTrainer包裝類,在呼叫update時將自動處理級聯 DDPM 中所有 U 網的指數移動平均值
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)您還可以訓練沒有文字的 Imagen(無條件圖像生成),如下所示
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)或僅訓練超解析度 unets
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256)您可以隨時使用儲存和load方法來save和載入訓練器以及所有相關狀態。建議您使用這些方法,而不是使用state_dict呼叫手動儲存,因為訓練器內部會進行一些裝置記憶體管理。
前任。
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 您也可以依靠ImagenTrainer自動訓練DataLoader實例。您只需製作DataLoader即可傳回images (對於無條件情況),或傳回('images', 'text_embeds')用於文字引導生成。
前任。無條件訓練
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )感謝?加速,只需兩步驟即可輕鬆進行多GPU訓練。
首先,您需要在訓練腳本所在的目錄中呼叫accelerate config (假設它名為train.py )
$ accelerate config接下來,您將使用加速 CLI,而不是像針對單 GPU 那樣呼叫python train.py
$ accelerate launch train.py就是這樣!
Imagen 也可以直接透過 CLI 使用。
前任。
$ imagen config或者
$ imagen config --path ./configs/config.json在配置中,您可以變更訓練器、資料集和影像配置的設定。
Imagen 設定參數可以在這裡找到
闡明的 Imagen 配置參數可以在這裡找到
Imagen Trainer 設定參數可以在這裡找到
對於資料集參數,可以使用所有資料載入器參數。
此命令可讓您訓練或恢復訓練模型
前任。
$ imagen train或者
$ imagen train --unet 2 --epoches 10您可以將以下參數傳遞給訓練命令。
--config指定用於訓練的設定檔[預設值:./imagen_config.json]--unet要訓練的unet的索引[預設值:1]--epoches訓練多少個紀元[預設值:50]請注意,在採樣時,您的檢查點應該訓練所有 unets 以獲得可用的結果。
前任。
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.png您可以將以下參數傳遞給範例命令。
--model指定用於採樣的模型文件--cond_scale解碼器中的調節尺度(分類器免費指導)--load_ema載入 EMA 版本的 unets(如果可用)為了使用具有此功能的已儲存檢查點,您必須使用設定類別ImagenConfig和ElucidatedImagenConfig化 Imagen 實例,或直接透過 CLI 建立檢查點
為了進行正確的訓練,您可能無論如何都需要設定配置驅動的訓練。
前任。
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminal事情真的應該這麼簡單
您還可以傳遞此檢查點文件,任何人都可以繼續微調自己的數據
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning 修復遵循最近的 Repaint 論文中提出的公式。只需將inpaint_images和inpaint_masks傳遞給Imagen或ElucidatedImagen上的sample函數
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512)對於視頻,同樣將您的視頻傳遞給.sample上的inpaint_videos關鍵字。所有幀的修復蒙版可以相同(batch, height, width) ,也可以不同(batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) StyleGAN 出名的 Tero Karras 撰寫了一篇新論文,其結果已得到許多獨立研究人員以及我自己的機器的證實。我決定創建Imagen的一個版本,即ElucidatedImagen ,以便可以使用新的闡明的 DDPM 進行文本引導的級聯生成。
只需匯入ElucidatedImagen ,然後像之前一樣實例化該實例。超參數與離散和連續時間高斯擴散的常用參數不同,並且可以針對級聯中的每個 unet 進行個人化。
前任。
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above 該存儲庫還將開始累積圍繞文字引導視訊合成的新研究。首先,它將採用 Jonathan Ho 在視訊擴散模型中所描述的 3dunet 架構
更新:Hadrien Reynaud 已驗證工作!
前任。
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32)您也可以先訓練文字-圖像對。 Unet3D會自動將其轉換為單幀視頻,並在沒有時間分量的情況下進行學習(透過自動設定ignore_time = True ),無論是一維卷積還是跨時間的因果注意力。
這是目前所有大型人工智慧實驗室(Brain、MetaAI、位元組跳動)所採用的方法
Imagen 使用一種稱為 Classifier Free Guidance 的演算法。採樣時,您對條件(本例為文字)套用大於1.0的比例。
研究人員 Netruk44 報告說5-10是最佳值,但任何超過10的值都需要打破。
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than average目前還不行,但可能會在一年內(甚至更早)接受培訓並開源。如果您想參與,可以加入 Laion 的人工神經網路訓練師社群(discord 連結位於上面的自述文件中)並開始合作。
更多關於為什麼你應該從今天開始訓練你自己的模型的原因!我們最不需要的就是這項技術掌握在少數菁英手中。希望這個儲存庫可以減少工作量,只需要尋找必要的運算,並使用您自己整理的資料集進行擴充。
任何事物!它獲得了麻省理工學院的許可。換句話說,您可以自由複製/貼上以進行自己的研究,並以您能想到的任何方式進行重新混合。去訓練令人驚奇的模式是為了利潤、為了科學,或只是為了滿足自己目睹神聖事物在你面前展開的個人樂趣。
超音波心動圖合成【代碼】
SOTA Hi-C接觸矩陣合成[代碼]
平面圖生成
超高解析度組織病理學玻片
合成腹腔鏡影像
設計超材料
Flavio Schneider 的音頻擴散
來自 Ryan O. 的迷你圖像 | AssemblyAI 撰寫
使用 Huggingface 轉換器進行 T5 小文字嵌入
新增動態閾值
還添加動態閾值 DALLE2 和視訊擴散儲存庫
允許設置 T5-large(也許還有小型工廠方法來容納任何擁抱面變壓器)
使用附錄中的偽代碼添加低解析度噪聲級別,並找出它們在推理時執行的掃描是什麼
從 DALLE2 移植一些訓練代碼
需要能夠為每個unet使用不同的噪音計劃(餘弦用於基礎,但線性用於SR)
只要製作一個可主配置的unet
完整的 resnet 區塊(受 biggan 啟發?但具有 groupnorm)- 完整的自我關注
完整的調節嵌入塊(並使其完全可配置,無論是注意力、電影等)
考慮使用 https://github.com/lucidrains/flamingo-pytorch 中的感知器重採樣器來取代注意力池
除了交叉注意力和電影之外,還添加註意力集中選項
為每個unet添加可選的帶有預熱的餘弦衰減時間表到訓練器
切換到連續時間步長而不是離散化時間步長,因為這似乎是他們用於所有階段的時間步長- 首先從變分ddpm 論文中找出線性噪聲調度案例https://openreview.net/forum ?id=2LdBqxc1Yv
計算出 alpha 餘弦雜訊表的 log(snr)。
抑制變壓器警告,因為僅使用 T5 編碼器
允許設定在無法使用完全注意的圖層上使用線性注意
強制 unets 在連續時間情況下使用非傅立葉條件(只需透過具有可選層範數的 MLP 傳遞日誌(snr)),因為這就是我在本地工作的
刪除了學習方差
增加連續時間的 p2 損失權重
確保級聯 ddpm 可以在沒有文字條件的情況下進行訓練,並確保連續和離散時間高斯擴散都有效
在線性注意中的 qkv 投影上使用底漆的深度卷積(或在投影之前使用標記移位) - 也使用 bayesformer 提出的新 dropout,因為它似乎與線性注意配合得很好
探索unet解碼器中的跳層激勵
加速整合
建構 CLI 工具和一行圖像生成
消除加速引起的任何問題
使用重繪紙上的重採樣器添加修復能力 https://arxiv.org/abs/2201.09865
建立一個簡單的檢查點系統,由資料夾支援
從所有上採樣塊的輸出添加跳躍連接,用於unet方格紙和一些以前的unet作品
新增 Romain @rom1504 建議的 fsspec,用於與雲端/本機檔案系統無關的檢查點持久性
使用 https://github.com/fsspec/gcsfs 測試 gcs 中的持久性
擴展到視頻生成,使用軸向時間注意力,如 Ho 的視頻 ddpm 論文中所示
允許闡明的圖像推廣到任何形狀
允許 imagen 推廣到任何形狀
添加動態位置偏差,以實現跨視訊時間的最佳長度外推類型
將視訊幀移動到範例函數,因為我們將嘗試時間外推
對空鍵/值的注意偏差應該是頭部維度的學習標量
從位元擴散紙添加自調節,已在 ddpm-pytorch 編碼
加入 imagen 影片論文的 v 參數化(https://arxiv.org/abs/2202.00512),這是唯一的新內容
整合從 make-a-video (https://makeavideo.studio/) 中學到的所有知識
建立用於訓練的 CLI 工具,從設定檔恢復訓練
允許在特定階段進行時間插值
確保時間插值適用於修復
確保可以自訂所有插值模式(一些研究人員發現三線性有更好的結果)
imagen-video :允許對先前(也可能是未來)的視訊畫面進行調整。在這種情況下不應允許忽略時間
確保自動處理調節視訊幀的時間下/上採樣,但允許選擇將其關閉
確保修復適用於視頻
確保視訊修復蒙版可以接受每個畫面的定制
添加閃光關注
重讀 cogvideo 並弄清楚如何使用幀速率調節
在unet3d中引入自註意力層的注意力專業知識
考慮引入 NUWA 的 3d 卷積注意力
考慮時間注意力區塊中的 Transformer-xl 記憶
考慮感知者方法來關注過去的時間
注意力過程中的幀丟失,以實現正則化效果並縮短訓練時間
調查 Frank Wood 的主張 https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch 並添加分層採樣技術,或讓人們了解其缺陷
提供具有挑戰性的移動 mnist(帶有乾擾對象)作為單行可訓練基線,供研究人員從文本到視頻進行分支
將文字預編碼為記憶體映射嵌入
能夠基於舊紀元樣式建立資料載入器迭代器,也可以設定洗牌等
也能夠傳入參數(而不是要求forward成為模型上的所有關鍵字參數)
從 revnets 引入 3dunet 的可逆區塊,以減輕記憶體負擔
增加僅訓練超解析度網路的能力
閱讀 dpm-solver 看看它是否適用於連續時間高斯擴散
允許使用任意絕對時間調節視訊幀(在時間注意力期間計算 RPE)
容納夢想展位微調
新增文字倒裝
在影像實例化時提取清理自我調節
確保最終的 Dreambooth 能夠與 imagen-video 配合使用
加入視訊擴散的幀率調節
確保可以同時對視訊畫面進行調節作為提示,以及對所有畫面進行一些調節影像
測試並添加一致性模型的蒸餾技術
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

