memorizing transformers pytorch
0.4.1
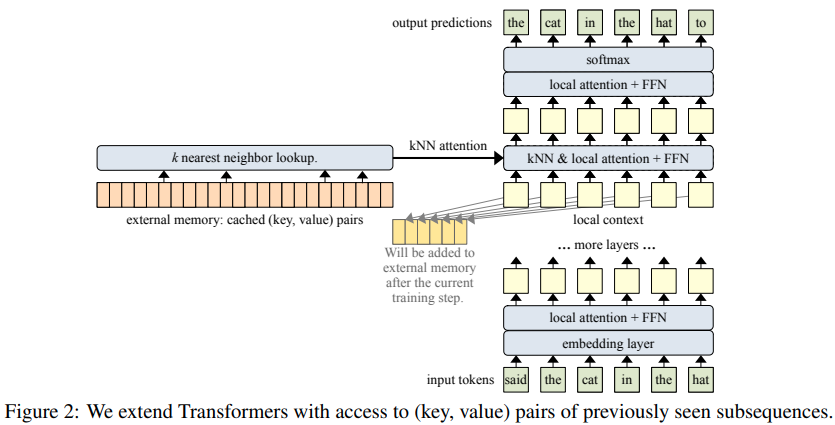
在 Pytorch 中實現記憶變壓器 (ICLR 2022),透過使用近似最近鄰的記憶索引和檢索來增強注意力網絡
這個儲存庫與論文略有不同,使用了本地和遠端注意力邏輯的混合注意力(而不是 sigmoid 閘設定)。它也對 KNN 注意力層使用餘弦相似度注意力(具有學習溫度)。
$ pip install memorizing-transformers-pytorch import torch
from memorizing_transformers_pytorch import MemorizingTransformer
model = MemorizingTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # dimension
dim_head = 64 , # dimension per attention head
depth = 8 , # number of layers
memorizing_layers = ( 4 , 5 ), # which layers to have ANN memories
max_knn_memories = 64000 , # maximum ANN memories to keep (once it hits this capacity, it will be reset for now, due to limitations in faiss' ability to remove entries)
num_retrieved_memories = 32 , # number of ANN memories to retrieve
clear_memories_on_sos_token_id = 1 , # clear passed in ANN memories automatically for batch indices which contain this specified SOS token id - otherwise, you can also manually iterate through the ANN memories and clear the indices before the next iteration
)
data = torch . randint ( 0 , 20000 , ( 2 , 1024 )) # mock data
knn_memories = model . create_knn_memories ( batch_size = 2 ) # create collection of KNN memories with the correct batch size (2 in example)
logits = model ( data , knn_memories = knn_memories ) # (1, 1024, 20000)您可以透過將forward上的add_knn_memory設定為False來使KNN記憶體只讀
前任。
logits = model ( data , knn_memories = knn_memories , add_knn_memory = False ) # knn memories will not be updated使用 Transformer-XL 記憶體(只有將被丟棄的記憶體才會加入 KNN 記憶體)
import torch
from memorizing_transformers_pytorch import MemorizingTransformer
model = MemorizingTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 8 ,
memorizing_layers = ( 4 , 5 ),
max_knn_memories = 64000 ,
num_retrieved_memories = 32 ,
clear_memories_on_sos_token_id = 1 ,
xl_memory_layers = ( 2 , 3 , 4 , 5 ), # xl memory layers - (https://arxiv.org/abs/2007.03356 shows you do not need XL memory on all layers, just the latter ones) - if a KNNAttention layer ends up using XL memories, only the XL memories that will be discarded will be added to long term memory
xl_max_memories = 512 , # number of xl memories to keep
shift_knn_memories_down = 1 , # let a layer look at the KNN memories this number of layers above
shift_xl_memories_down = 1 , # let a layer look at the XL memories this number of layers above, shown to enhance receptive field in ernie-doc paper
)
data = torch . randint ( 0 , 20000 , ( 2 , 1024 )) # mock data
xl_memories = None
with model . knn_memories_context ( batch_size = 2 ) as knn_memories :
logits1 , xl_memories = model ( data , knn_memories = knn_memories , xl_memories = xl_memories )
logits2 , xl_memories = model ( data , knn_memories = knn_memories , xl_memories = xl_memories )
logits3 , xl_memories = model ( data , knn_memories = knn_memories , xl_memories = xl_memories )
# ... and so on 此儲存庫包含 Faiss 的包裝器,可以自動儲存和檢索鍵/值
import torch
from memorizing_transformers_pytorch import KNNMemory
memory = KNNMemory (
dim = 64 , # dimension of key / values
max_memories = 64000 , # maximum number of memories to keep (will throw out the oldest memories for now if it overfills)
num_indices = 2 # this should be equivalent to batch dimension, as each batch keeps track of its own memories, expiring when it sees a new document
)
memory . add ( torch . randn ( 2 , 512 , 2 , 64 )) # (batch, seq, key | value, feature dim)
memory . add ( torch . randn ( 2 , 512 , 2 , 64 ))
memory . clear ([ 0 ]) # clear batch 0, if it saw an <sos>
memory . add ( torch . randn ( 2 , 512 , 2 , 64 ))
memory . add ( torch . randn ( 2 , 512 , 2 , 64 ))
key_values , mask = memory . search ( torch . randn ( 2 , 512 , 64 ), topk = 32 )Enwik8培訓
$ python train.py @article { wu2022memorizing ,
title = { Memorizing transformers } ,
author = { Wu, Yuhuai and Rabe, Markus N and Hutchins, DeLesley and Szegedy, Christian } ,
journal = { arXiv preprint arXiv:2203.08913 } ,
year = { 2022 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @Article { AlphaFold2021 ,
author = { Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and {v{Z}}{'i}dek, Augustin and Potapenko, Anna and Bridgland, Alex and Meyer, Clemens and Kohl, Simon A A and Ballard, Andrew J and Cowie, Andrew and Romera-Paredes, Bernardino and Nikolov, Stanislav and Jain, Rishub and Adler, Jonas and Back, Trevor and Petersen, Stig and Reiman, David and Clancy, Ellen and Zielinski, Michal and Steinegger, Martin and Pacholska, Michalina and Berghammer, Tamas and Bodenstein, Sebastian and Silver, David and Vinyals, Oriol and Senior, Andrew W and Kavukcuoglu, Koray and Kohli, Pushmeet and Hassabis, Demis } ,
journal = { Nature } ,
title = { Highly accurate protein structure prediction with {AlphaFold} } ,
year = { 2021 } ,
doi = { 10.1038/s41586-021-03819-2 } ,
note = { (Accelerated article preview) } ,
} @inproceedings { Rae2020DoTN ,
title = { Do Transformers Need Deep Long-Range Memory? } ,
author = { Jack W. Rae and Ali Razavi } ,
booktitle = { ACL } ,
year = { 2020 }
} @misc { ding2021erniedoc ,
title = { ERNIE-Doc: A Retrospective Long-Document Modeling Transformer } ,
author = { Siyu Ding and Junyuan Shang and Shuohuan Wang and Yu Sun and Hao Tian and Hua Wu and Haifeng Wang } ,
year = { 2021 } ,
eprint = { 2012.15688 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { henry2020querykey ,
title = { Query-Key Normalization for Transformers } ,
author = { Alex Henry and Prudhvi Raj Dachapally and Shubham Pawar and Yuxuan Chen } ,
year = { 2020 } ,
eprint = { 2010.04245 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}記憶是時間中的注意力——亞歷克斯·格雷夫斯


