make a video pytorch
0.4.0
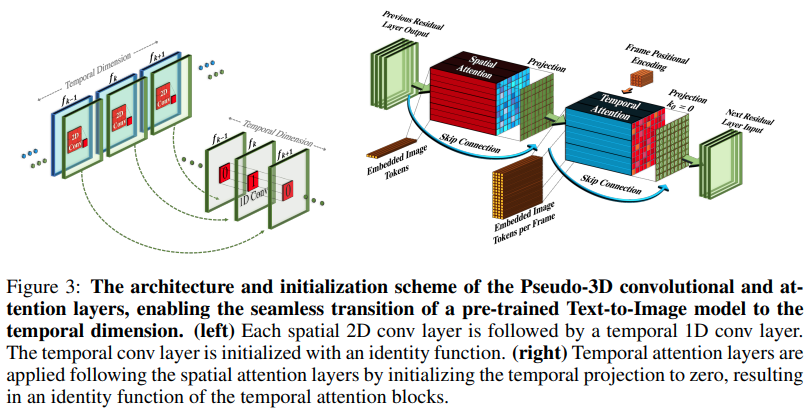
在 Pytorch 中實現 Make-A-Video,這是 Meta AI 的新 SOTA 文字到視訊產生器。它們結合了偽 3d 卷積(軸向卷積)和時間注意力,並表現出更好的時間融合。
偽 3d 卷積並不是新概念。先前已經在其他情況下對其進行過探索,例如將蛋白質接觸預測作為「維度混合殘差網絡」。
這篇論文的要點歸結為,採用 SOTA 文本到圖像模型(這裡他們使用 DALL-E2,但相同的學習點很容易適用於 Imagen),對跨時間和其他方式的注意力進行一些小的修改為了節省計算成本,正確進行幀插值,獲得出色的視訊模型。
AI 茶歇講解
Stability.ai 慷慨贊助前沿人工智慧研究
喬納森·何(Jonathan Ho)透過他的開創性論文帶來了生成人工智慧的革命
Alex 提出 einops,這是一個天才的抽象概念。沒有其他詞可以形容它。
$ pip install make-a-video-pytorch傳入視訊特徵
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)傳入影像(如果先對影像進行預訓練),時間卷積和注意力都會自動跳過。換句話說,您可以直接在 2d Unet 中使用它,然後在該階段的訓練完成後將其移植到 3d Unet。時間模組被初始化為輸出身份,正如論文所做的那樣。
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)您也可以控制這兩個模組,以便在輸入 3 維特徵時,它只進行空間訓練
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16)完整的SpaceTimeUnet與圖像或視頻訓練無關,即使傳入視頻,時間也可以忽略
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )關注最佳位置嵌入研究提供的結果
吸引註意力
添加閃光關注
確保 dalle2-pytorch 可以接受SpaceTimeUnet進行訓練
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

