minimind
V1

中文| English
本開源專案旨在完全從0開始,最快僅用3小時!即可訓練出僅26.88M大小的微型語言模型MiniMind 。
MiniMind極為輕量,最小版本體積約是GPT3 的
MiniMind發布了大模型極簡結構,資料集清洗和預處理、監督預訓練(Pretrain)、有監督指令微調(SFT)、低秩自適應(LoRA) 微調,無獎勵強化學習直接偏好對齊(DPO)的全階段程式碼,也包含拓展共享混合專家(MoE) 的稀疏模型;拓展視覺多模態VLM: MiniMind-V。
這不僅是一個開源模型的實現,也是入門大語言模型(LLM)的教學。
希望此計畫能為研究者提供一個拋磚引玉的入門範例,幫助大家快速上手並對LLM領域產生更多的探索與創新。
為防止誤讀,「最快3小時」是指您需要具備>本人硬體配置的機器,具體規格的詳細資訊將在下文提供。

ModelScope線上測試| Bilibili影片鏈接
大語言模型(LLM)領域,如GPT、LLaMA、GLM 等,雖然它們效果驚艷, 但動輒10 Bilion龐大的模型參數個人設備顯存遠不夠訓練,甚至推理困難。 幾乎所有人都不會只滿足於用Lora等方案fine-tuing大模型學會一些新的指令, 這約等於在教牛頓玩21世紀的智慧型手機,然而,這遠遠脫離了學習物理本身的奧妙。 此外,賣課付費訂閱的營銷號碼漏洞百出的一知半解講解AI的教程遍地, 讓理解LLM的優質內容雪上加霜,嚴重阻礙了學習者。
因此,本計畫的目標是把上手LLM的門檻無限降低, 直接從0開始訓練一個極為輕量的語言模型。
Tip
(截至2024-9-17)MiniMind系列已完成了3個型號模型的預訓練,最小僅需26M(0.02B),即可具備流暢的對話能力!
| 模型(大小) | tokenizer長度 | 推理佔用 | release | 主觀評分(/100) |
|---|---|---|---|---|
| minimind-v1-small (26M) | 6400 | 0.5 GB | 2024.08.28 | 50' |
| minimind-v1-moe (4×26M) | 6400 | 1.0 GB | 2024.09.17 | 55' |
| minimind-v1 (108M) | 6400 | 1.0 GB | 2024.09.01 | 60' |
分析在具有Torch 2.1.2、CUDA 12.2和Flash Attention 2的2×RTX 3090 GPU上進行。
項目包含:
transformers 、 accelerate 、 trl 、 peft等流行框架。希望此開源專案可以幫助LLM初學者快速入門!
為MiniMind拓展了多模態能力之---視覺
移步孿生計畫minimind-v查看詳情!
09-27更新pretrain資料集的預處理方式,為了確保文字完整性,放棄預處理成.bin訓練的形式(輕微犧牲訓練速度)。
目前pretrain預處理後的檔案命名為:pretrain_data.csv。
刪除了一些冗餘的程式碼。
更新minimind-v1-moe模型
為了防止歧義,不再使用mistral_tokenizer分詞,全部採用自訂的minimind_tokenizer作為分詞器。
更新minimind-v1 (108M)模型,採用minimind_tokenizer,預訓練輪次3 + SFT輪次10,更充分訓練,性能更強。
專案已部署至ModelScope創空間,可在此網站上體驗:
?ModelScope線上體驗?
僅是我個人的軟硬體環境配置,自行酌情更改:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMind (HuggingFace)
MiniMind (ModelScope)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.py或啟動streamlit,啟動網頁聊天介面
「注意」需要python>=3.10,安裝
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0、克隆項目程式碼
git clone https://github.com/jingyaogong/minimind.git
cd minimind1、環境安裝
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
如果不可用,請自行去torch_stable 下載whl檔案安裝。參考連結
2.如果你需要自己訓練
2.1 下載資料集下載位址放到./dataset目錄下
2.2 python data_process.py處理資料集,例如pretrain資料提前進行token-encoder、sft資料集抽離qa到csv文件
2.3 在./model/LMConfig.py中調整model的參數配置
這裡只需調整dim和n_layers和use_moe參數,分別是
(512+8)或(768+16),對應minimind-v1-small和minimind-v1
2.4 python 1-pretrain.py執行預訓練,得到pretrain_*.pth作為預訓練的輸出權重
2.5 python 3-full_sft.py執行指令微調,得到full_sft_*.pth作為指令微調的輸出權重
2.6 python 4-lora_sft.py執行lora微調(非必須)
2.7 python 5-dpo_train.py執行DPO人類偏好強化學習對齊(非必須)
3.測試模型推理效果
*.pth檔位於./out/目錄下*.pth權重文件 minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py測試預訓練模型的接龍效果python 2-eval.py測試模型的對話效果
?「Tip」預訓練和全參微調pretrain和full_sft都支援多卡加速
假設你的裝置只有1張顯示卡,使用原生python啟動訓練即可:
python 1-pretrain.py
# and
python 3-full_sft.py假設你的裝置有N (N>1) 張顯示卡:
單機N卡啟動訓練(DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.py單機N卡啟動訓練(DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.py開啟wandb記錄訓練過程(非必須)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb透過新增--use_wandb參數,可以記錄訓練過程,訓練完成後,可以在wandb網站上查看訓練過程。透過修改wandb_project和wandb_run_name參數,可以指定專案名稱和運行名稱。
? 分詞器:nlp中的Tokenizer類似於字典,將單字從自然語言透過「字典」映射到0,1,36這樣的數字,可以理解為數字就代表了單字在「字典」中的頁碼。 LLM分詞器的建構方式有兩種:一種是自己構造詞表訓練一個分詞器,程式碼可見train_tokenizer.py ;另一種是選擇開源模型訓練好的分詞器。 「字典」當然可以直接選擇用新華詞典或牛津字典,優點是token轉換壓縮率很好,但缺點是詞表太長,動輒數十萬個詞彙短語; 也可以使用自己訓練的分詞器,優點是詞表隨意控制,缺點是壓縮率不夠理想,生僻詞不容易面面俱到。 當然,「字典」的選擇很重要,LLM的輸出本質上是SoftMax到字典N個字的多分類問題,然後透過「字典」解碼到自然語言。 因為LLM體積非常小,為了避免模型頭重腳輕(詞嵌入embedding層參數佔整個LLM比太高),所以詞表長度要選擇比較小。 強大的開源模型例如01萬物、千問、chatglm、mistral、Llama3等,它們的tokenizer詞表長度如下:
| Tokenizer模型 | 詞表大小 | 來源 |
|---|---|---|
| yi tokenizer | 64,000 | 01萬物(中國) |
| qwen2 tokenizer | 151,643 | 阿里雲(中國) |
| glm tokenizer | 151,329 | 智譜AI(中國) |
| mistral tokenizer | 32,000 | Mistral AI(法國) |
| llama3 tokenizer | 128,000 | Meta(美國) |
| minimind tokenizer | 6,400 | 自訂 |
2024-09-17更新:為了防止過去的版本歧義&控制體積,minimind所有模型均使用minimind_tokenizer分詞,廢棄所有mistral_tokenizer版本。
儘管minimind_tokenizer長度很小,編解碼效率弱於qwen2、glm等中文友善分詞器。 但minimind模型選擇了自己訓練的minimind_tokenizer作為分詞器,以保持整體參數輕量,避免編碼層和計算層佔比失衡,頭重腳輕,因為minimind的詞表大小只有6400。 且minimind在實際測試中沒有出現過生僻詞彙解碼失敗的情況,效果良好。 由於自訂詞表壓縮長度到6400,使得LLM總參數量最低只有26M。
?【Pretrain資料】: Seq-Monkey通用文字資料集/ Seq-Monkey百度網盤是由多種公開來源的資料(如網頁、百科、部落格、開源程式碼、書籍等)匯總清洗而成。整理成統一的JSONL格式,並經過了嚴格的篩選和去重,確保資料的全面性、規模、可信賴性和高品質。總量大約在10B token,適合中文大語言模型的預訓練。
第2種選擇:SkyPile-150B資料集的可公開存取部分包含約2.33億個獨立網頁,每個網頁平均包含1000多個漢字。資料集包括約1500億個令牌和620GB的純文字資料。如果急的話,可以嘗試只挑選SkyPile-150B的部分jsonl下載(並在./data_process.py中對文本tokenizer生成* .csv檔),以便快速跑通預訓練流程。
下載到./dataset/目錄下
| MiniMind訓練資料集 | 下載地址 |
|---|---|
| 【tokenizer訓練集】 | HuggingFace / 百度網盤 |
| 【Pretrain數據】 | Seq-Monkey官方/ 百度網盤/ HuggingFace |
| 【SFT數據】 | 匠數大模型SFT資料集 |
| 【DPO數據】 | Huggingface |
MiniMind-Dense(和Llama3.1一樣)使用了Transformer的Decoder-Only結構,跟GPT-3的差別在於:
MiniMind-MoE模型,它的結構是基於Llama3和Deepseek-V2中的MixFFN混合專家模組。
MiniMind的整體結構一致,只是在RoPE計算、推理函數和FFN層的程式碼上做了一些小調整。 其架構如下圖(重繪版):
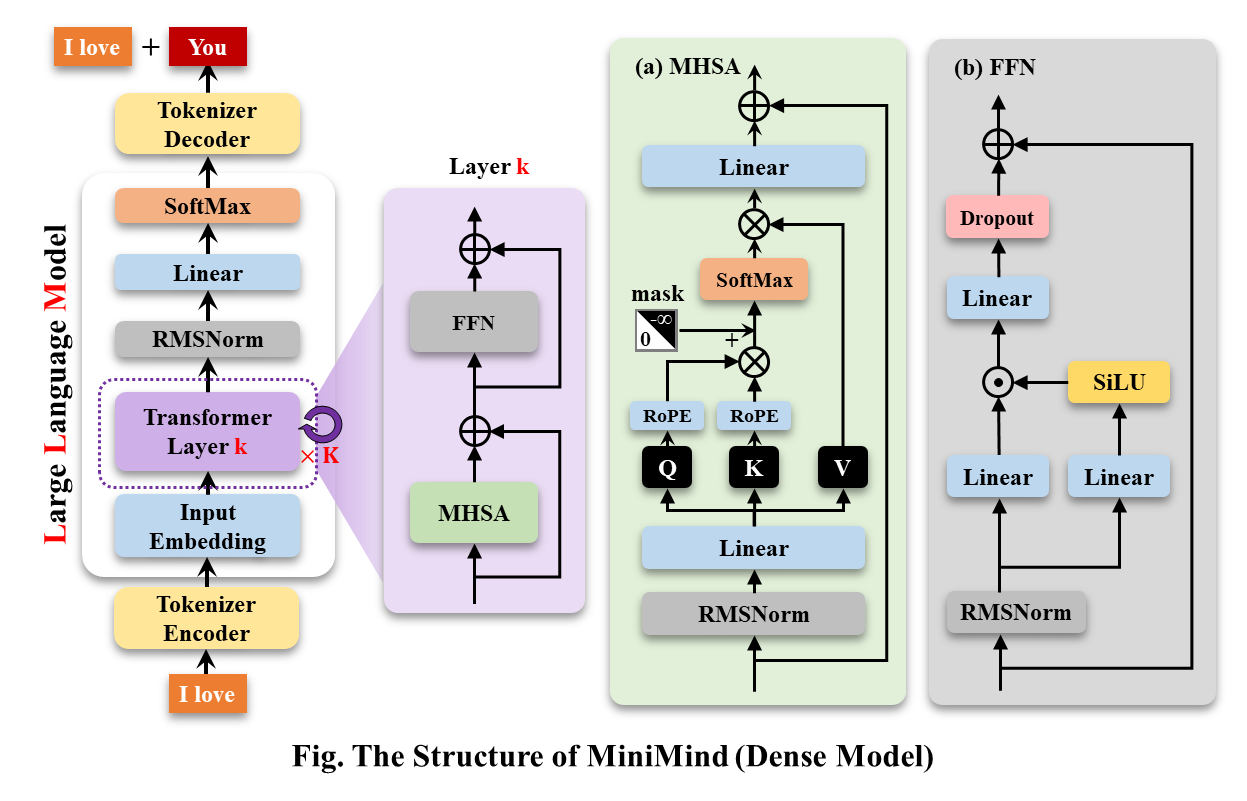
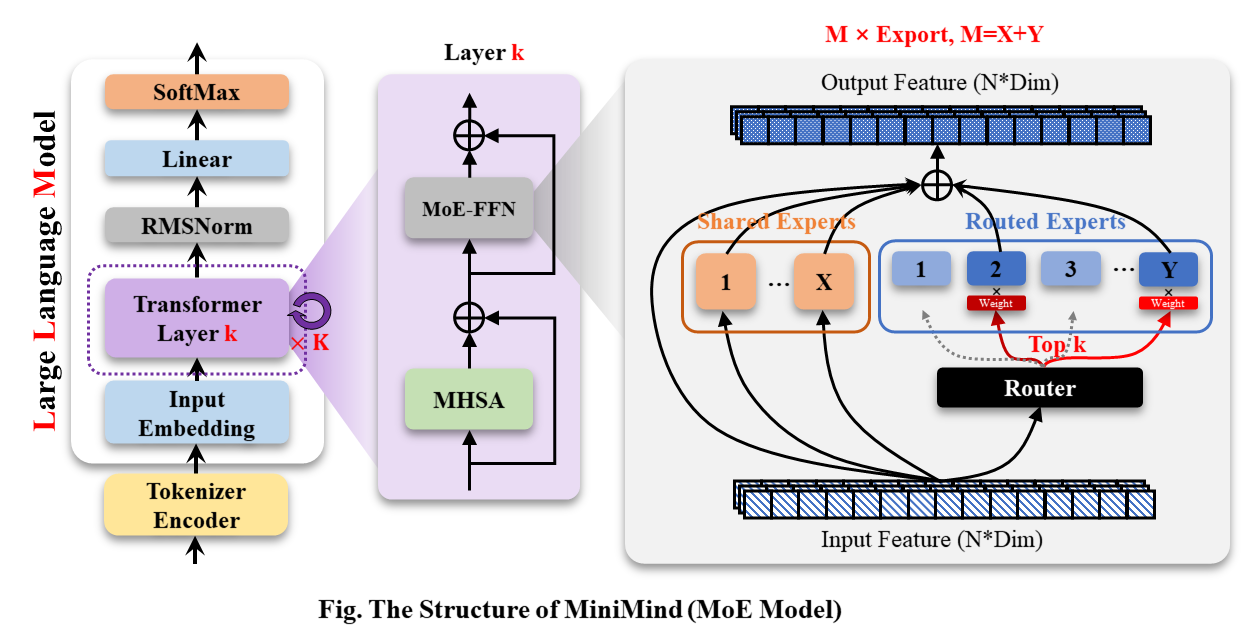
修改模型配置請參考./model/LMConfig.py。 minimind目前訓練的模型版本請見下表:
| Model Name | params | len_vocab | n_layers | d_model | kv_heads | q_heads | share+route | TopK |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
| Model Name | params | len_vocab | batch_size | pretrain_time | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | 6400 | 64 | ≈2 hour (1 epoch) | ≈2 hour (1 epoch) | ≈0.5 hour (1 epoch) |
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 hour (1 epoch) | ≈5 hour (1 epoch) | ≈1 hour (1 epoch) |
| minimind-v1 | 108M | 6400 | 16 | ≈6 hour (1 epoch) | ≈4 hour (1 epoch) | ≈1 hour (1 epoch) |
預訓練(Text-to-Text) :
pretrain的學習率設定為1e-4到1e-5的動態學習率,預訓練epoch數設為5。
torchrun --nproc_per_node 2 1-pretrain.py單輪次對話有監督微調(Single dialog Fine-tuning) :
在推理時透過調整RoPE線性差值,實現長度外推到1024或2048及以上很方便。學習率設定為1e-5到1e-6的動態學習率,微調epoch數為6。
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.py多輪對話微調(Multi dialog Fine-tuning) :
學習率設定為1e-5到1e-6的動態學習率,微調epoch數為5。
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.py人類回饋強化學習(RLHF)之-直接偏好優化(Direct Preference Optimization, DPO) :
活字三元組(q,chose,reject)資料集,學習率le-5,半精度fp16,共1個epoch,耗時1h。
python 5-dpo_train.py ?關於LLM的參數配置,有一篇很有趣的論文MobileLLM做了詳細的研究和實驗。 scaling law在小模型中有自己獨特的規律。 造成Transformer參數成規模變化的參數幾乎只取決於d_model和n_layers 。
d_model ↑+ n_layers ↓->矮胖子d_model ↓+ n_layers ↑->瘦高個2020年提出Scaling Law的論文認為,訓練資料量、參數量、訓練迭代次數才是決定效能的關鍵因素,而模型架構的影響幾乎可以忽略。 然而似乎這個定律對小模型並不完全適用。 MobileLLM提出架構的深度比寬度更重要,「深而窄」的「瘦長」模型可以學習到比「寬而淺」模型更多的抽象概念。 例如當模型參數固定在125M或350M時,30~42層的「狹長」模型明顯比12層左右的「矮胖」模型有更優越的性能, 在常識推理、問答、閱讀理解等8個基準測試上都有類似的趨勢。 這其實是非常有趣的發現,因為以往為100M左右量級的小模型設計架構時,幾乎沒人嘗試過疊加超過12層。 這與MiniMind在訓練過程中,模型參數量在d_model和n_layers之間進行調整實驗觀察到的效果是一致的。 然而「深而窄」的「窄」也是有維度極限的,當d_model<512時,詞嵌入維度坍塌的劣勢非常明顯, 增加的layers並不能彌補詞嵌入在固定q_head帶來d_head不足的劣勢。 當d_model>1536時,layers的增加似乎比d_model的優先權更高,更能帶來具有「性價比」的參數->效果增益。 因此MiniMind設定small模型的d_model=512,n_layers=8來獲得的「極小體積<->更好效果」的平衡。 設定d_model=768,n_layers=16來獲得效果的更大收益,更符合小模型scaling-law的變化曲線。
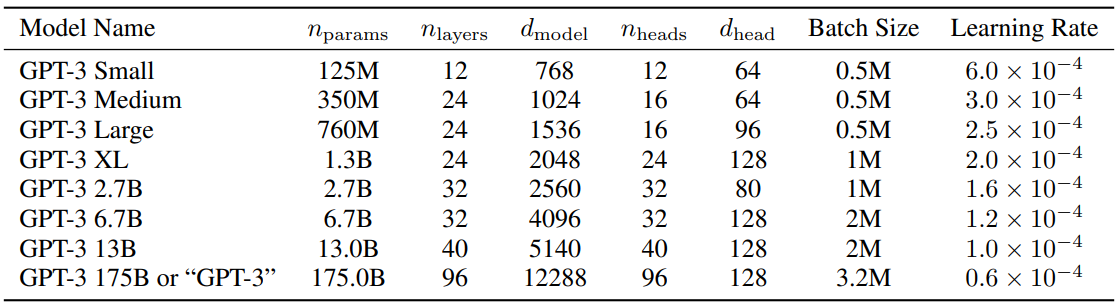
作為參考,GPT3的參數設定請參考下表:
?百度網盤
| Model Name | params | Config | pretrain_model | single_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | d_model=512 n_layers=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimind-v1-moe | 4×26M | d_model=512 n_layers=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| minimind-v1 | 108M | d_model=768 n_layers=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
Tip
測試基於「單輪對話full_sft」和「DPO強化學習對齊」的minimind模型比較。
模型檔百度網盤,其中rl_<dim>.pth即為「DPO強化學習對齊」後的minimind模型權重。
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
Tip
以下測試於2024-09-17完成,此日期後發布的新模型,無特殊需求時將不加入測試。 測試基於單輪對話full_sft的minimind模型(無多輪微調和強化學習微調)。
[A] minimind-v1-small(0.02B)
[B] minimind-v1-moe(0.1B)
[C] minimind-v1(0.1B)
[D] baby-llama2-chinese(0.2B)
[E] chatlm-mini-chinese(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
Note
?♂️直接把上述模型的回答丟給GPT-4o,讓它幫忙打個分:
模型A :
模型B :
模型C :
模型D :
模型E :
| 模型 | C | E | B | A | D |
|---|---|---|---|---|---|
| 分數 | 75 | 70 | 65 | 60 | 50 |
minimind系列(ABC)的排序符合直覺,minimind-v1(0.1B)評分最高,常識性問題的回答基本上沒有錯誤和幻覺。
epochs僅有不到2,偷懶提前kill騰出資源給小模型,0.1B沒有得到充分訓練的情況下依然做到了最強,其實還是底大一級壓死人。E模型的回答肉眼看起來是非常不錯的,儘管存在些許幻覺瞎編的情況。但GPT-4o和Deepseek的評分都一致認為它「資訊過度冗長,且有重複內容,存在幻覺」。 其實這種評價略顯嚴格,100個字中就算有10個字是幻覺,就很容易把它歸到低分。由於E模型預訓練文字長度較長,資料集大得多,所以回答的看起來很完備。在體積近似的情況下,資料數量和品質都很重要。
?♂️個人主觀評價:E>C>B≈A>D
? GPT-4o 評價:C>E>B>A>D
Scaling Law:模型參數越大,訓練資料越多模型的效能越強。
C-Eval評測代碼見: ./eval_ceval.py , 小模型的測評通常為了避免回复格式的難以固定的特點, 而直接判斷A , B , C , D四個字母對應token預測概率,取最大的作為回答答案,與標準答案計算正確率。 minimind模型本身沒有使用較大的資料集訓練,也沒有針對回答選擇題的指令做微調,測評結果可以當個參考。
例如minimind-small的結果細項:
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data | probability_and_statistics | law | middle_school_biology | high_school_chemistry | high_school_physics | legal_professional | high_school_chinese | high_school_history | tax_accountant | modern_chinese_history | middle_school_physics | middle_school_history | basic_medicine | operating_system | logic | electrical_engineer | civil_servant | chinese_language_and_literature | college_programming | accountant | plant_protection | middle_school_chemistry | metrology_engineer | veterinary_medicine | marxism | advanced_mathematics | high_school_mathematics | business_administration | mao_zedong_thought | ideological_and_moral_cultivation | college_economics | professional_tour_guide | environmental_impact_assessment_engineer | computer_architecture | urban_and_rural_planner | college_physics | middle_school_mathematics | high_school_politics | physician | college_chemistry | high_school_biology | high_school_geography | middle_school_politics | clinical_medicine | computer_network | sports_science | art_studies | teacher_qualification | discrete_mathematics | education_science | fire_engineer | middle_school_geography |
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
| Accuracy | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| category | correct | question_count | accuracy |
|---|---|---|---|
| minimind-v1-small | 344 | 1346 | 25.56% |
| minimind-v1 | 351 | 1346 | 26.08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py可以匯出模型到transformers格式,推送到huggingface
MiniMind的huggingface集合位址: MiniMind
my_openai_api.py完成了openai_api的聊天接口,方便將自己的模型接入第三方UI 例如fastgpt、OpenWebUI等
從Huggingface下載模型權重文件
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
啟動聊天服務端
python my_openai_api.py測試服務介面
python chat_openai_api.pyAPI介面範例,相容於openai api格式
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
Tip
如果您覺得MiniMind對您有所幫助,可以在GitHub 上加一個篇幅不短水平有限難免紕漏,歡迎在Issues交流指正或提交PR改進項目您的支持就是持續改進項目的動力
Note
眾人拾柴火焰高如果您已經嘗試訓練了新的MiniMind型號,歡迎在Discussions或Issues中分享您的模型權重可以是在特定下游任務或垂直領域(例如情感識別、醫療、心理、金融、法律問答等)的MiniMind新模型版本也可以是拓展訓練後(例如探索更長文字序列、更大體積(0.1B+)或更大的資料集)的MiniMind新模型版本任何分享都視為獨一無二的,所有嘗試都具有價值,並受到鼓勵這些貢獻都會被及時發現並整理在鳴謝清單中,再次感謝所有支持!
@ipfgao : ?訓練步驟記錄
@chuanzhubin : ?程式碼逐行註釋
@WangRongsheng : ?大型資料集預處理
@pengqianhan : ?一個簡明教程
@RyanSunn : ?推理過程學習記錄
This repository is licensed under the Apache-2.0 License.


