Always Learning
1.0.0
最近更新日期:2020/06/28
最近一周新增:
目錄:
W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n是杯子數,k是樓層數)character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system (主鍵索引、聚集索引和非聚集索引)等基礎知識點。__iter__()函數,呼叫iter()之後,變成了一個list_iterator的對象,會發現增加了__next__()方法,所有實現了__iter__和__next__兩個方法的對象,都是迭代器),迭代器是帶狀態的對象,它會記錄當前迭代所處的位置,以方便下次迭代的時候取得正確的元素, __iter__傳回迭代器自身, __next__傳回容器的下一個值。生成器:使用了yield的函數稱為生成器,呼叫了一個生成器函數,返回的是迭代器對象,生成器可以看成是迭代器。\u72產生的原因就是瀏覽器的html自解碼)<a href=javascript:alert(1)>click</a>中alert(1)處在html->url->js環境中。 1.click 採用unicode編碼e,html和url環境下都不能解碼,只有在js環境下才能解碼為字元e,所以不會彈窗
python requests庫流程簡析
python requests函式庫實作:socket->httplib->urllib->urllib3->requests。 requests.get的內部呼叫流程:requests.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib)。
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
XGBoost原理與底層實現剖析(學到了)
XGBoost :從樹的分數(目標函數:損失函數(二階展開)+正規項),樹的結構(分裂決策(預先排序))來理解。
Lightgbm 直方圖優化演算法深入理解
Lightgbm :相較於預排序而言,lgb採用了直方圖來處理節點分裂,尋找最優分割點。演算法思想:在訓練前預先把特徵值轉換成bin value,也就是對每個特徵的取值做分段函數,將所有樣本在該特徵上的值劃分到某一段(bin)中,最後把特徵取值從連續值轉換為離散值。直方圖也可以用來做差加速,計算直方圖的複雜度是基於桶的個數的。
keras文字預處理源碼分析
Keras-文字預處理: 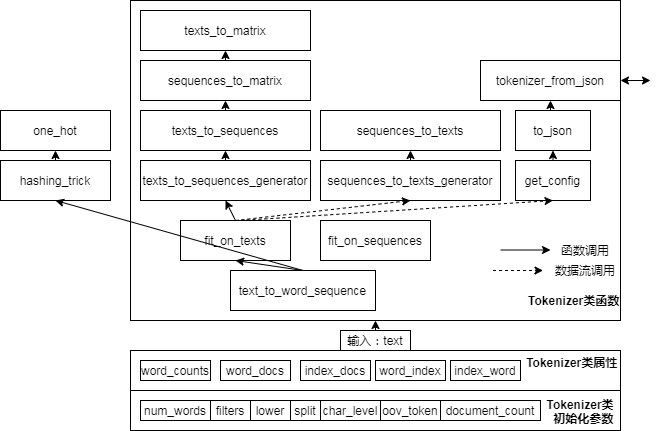
keras序列預處理源碼分析
select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b );使用select case when(条件) then 代码1 else 代码2 end繞過逗號過濾, insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end));http://[email protected]/ ;透過各種非HTTP協議0xA1-0xF7 ,低位0xA1-0xFE ,而0x5c ,不在低位範圍中,所以0x5c不是gb2312中的編碼,所以不會被吃掉 把這個思路拓寬到所有的多字節編碼,只要低位的範圍中含有0x5c的編碼,就可以進行寬字節注入。 )。防禦方案一: mysql_set_charset+mysql_real_escape_string ,考慮到連接的目前字元集。防禦方案二:將character_set_client設定為binary (二進位), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary 。當我們的mysql接受到客戶端的資料後,會認為他的編碼是character_set_client ,然後會將之將換成character_set_connection的編碼,然後進入具體表和字段後,再轉換成字段對應的編碼。然後,當查詢結果產生後,會從表格和欄位的編碼,轉換成character_set_results編碼,傳回給客戶端。所以,我們將character_set_client設定成binary ,就不存在寬位元組或多位元組的問題了,所有資料都以二進位的形式傳遞,就能有效避免寬字元注入。防禦過後呼叫iconv時也可能出現問題。使用iconv對utf-8轉gbk時,利用方式是錦' ,原因是它的utf-8編碼是0xe98ca6 ,它的gbk編碼是0xe55c ,最後變成%e5%5c%5c%27 ,兩個%5c是'前面的字元是奇數的話,勢必會吞掉'逃出限制。為什麼不能用錦'這種方式呢,根據utf-8編碼規則, (0x0000005c)不會出現在utf-8編碼中,所以會報錯。eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function ;指令執行函數: system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open .外,還有其他取得管理員路徑的方式嗎? src指定一個遠端的腳本文件,取得referer。这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用輸入單字x 作為中心單字去預測其他單字z出現在其周邊的可能性(至此我才明白為什麼說詞嵌入是神經網路訓練語言模型的副產品這句話)。用輸入單字當中心單字去預測週邊單字的方式叫skip-gram,用輸入單字當週邊單字去預測中心單字的方式叫CBOW。至關重要:如何做好我們的職涯規劃(學到了)
資料科學家(Data Scientist) 的核心技能是什麼?


