LongNet
0.4.8

這是論文 LongNet: Scaling Transformers to 1,000,000,000 Tokens 的開源實現,作者為 Jiayu Ding、Shuming Ma、Li Dong、Xingxing Zhang、Shaohan Huang、Wenhui Wang、Furu Wei。 LongNet 是 Transformer 的變體,旨在將序列長度擴展到超過 10 億個標記,而不會犧牲較短序列的性能。
pip install longnet安裝 LongNet 後,您可以使用DilatedAttention類,如下所示:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformer完全準備好訓練變壓器模型,其中包含帶有層範數、SWIGLU 和平行變壓器塊的前饋的擴張變壓器塊
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
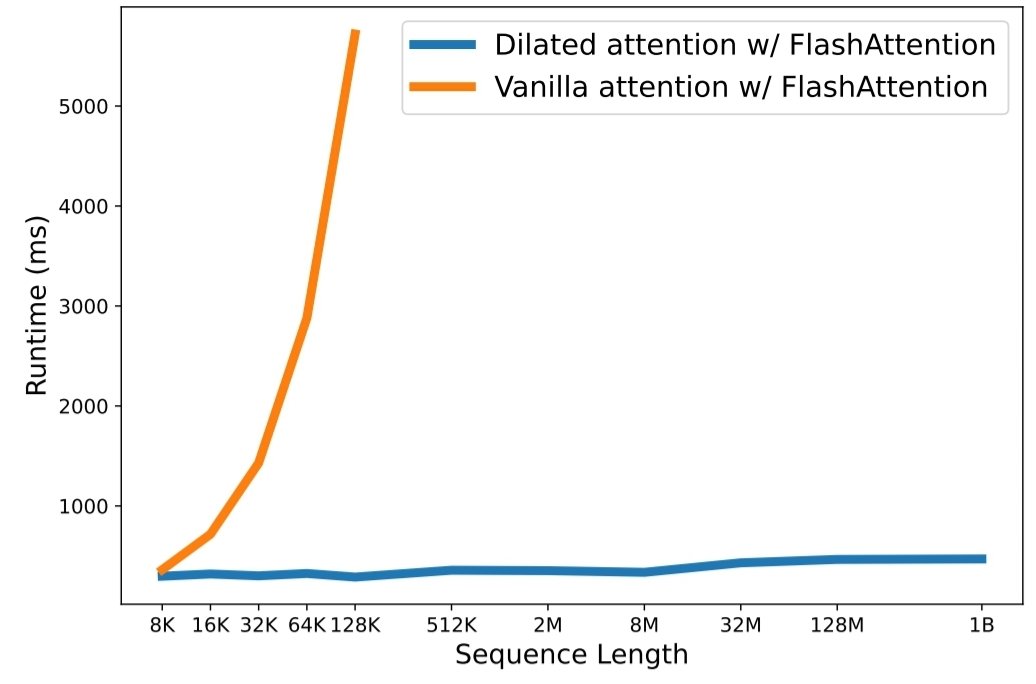
python3 train.py 縮放序列長度已成為大型語言模型時代的關鍵瓶頸。然而,現有方法要么面臨計算複雜性,要么面臨模型表達能力,導致最大序列長度受到限制。在本文中,他們介紹了 LongNet,這是一種 Transformer 變體,可以將序列長度擴展到超過 10 億個標記,而不會犧牲較短序列的性能。具體來說,他們提出了擴張注意力,隨著距離的增加,注意力範圍呈指數級擴大。
LongNet具有顯著的優勢:
實驗結果表明,LongNet 在長序列建模和通用語言任務上都有很強的表現。他們的工作為建模很長的序列開闢了新的可能性,例如,將整個語料庫甚至整個互聯網視為一個序列。
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

