pba
1.0.0
新功能:使用筆記本pba.ipynb可視化 PBA 和應用的增強!
現在支援 Python 3。
基於群體的增強(PBA)是一種快速有效地學習用於神經網路訓練的資料增強函數的演算法。 PBA 與 CIFAR 上最先進的結果相匹配,而計算量卻減少了一千倍,使研究人員和從業人員能夠使用單一工作站 GPU 有效地學習新的增強策略。
此儲存庫包含 TensorFlow 和 Python 中的「基於群體的增強:增強計劃的高效學習」(http://arxiv.org/abs/1905.05393) 工作的程式碼。它包括使用報告的增強計劃來訓練模型以及發現新的增強策略計劃。
請參閱下文,了解我們的增強策略的視覺化。

程式碼支援Python 2和3。
pip install -r requirements.txtbash datasets/cifar10.sh
bash datasets/cifar100.sh| 數據集 | 模型 | 測試誤差(%) |
|---|---|---|
| CIFAR-10 | Wide-ResNet-28-10 | 2.58 |
| 搖一搖 (26 2x32d) | 2.54 | |
| 搖一搖 (26 2x96d) | 2.03 | |
| 搖一搖 (26 2x112d) | 2.03 | |
| PyramidNet+ShakeDrop | 1.46 | |
| 簡化的 CIFAR-10 | Wide-ResNet-28-10 | 12.82 |
| 搖一搖 (26 2x96d) | 10.64 | |
| CIFAR-100 | Wide-ResNet-28-10 | 16.73 |
| 搖一搖 (26 2x96d) | 15.31 | |
| PyramidNet+ShakeDrop | 10.94 | |
| SVHN | Wide-ResNet-28-10 | 1.18 |
| 搖一搖 (26 2x96d) | 1.13 | |
| 減少SVHN | Wide-ResNet-28-10 | 7.83 |
| 搖一搖 (26 2x96d) | 6.46 |
重現結果的腳本位於scripts/table_*.sh中。所有腳本都需要一個參數,即模型名稱。可用選項是本文表 2 中每個資料集報告的選項,其中包括: wrn_28_10, ss_32, ss_96, ss_112, pyramid_net 。超參數也位於每個腳本檔案內。
例如,要在 Wide-ResNet-28-10 上重現 CIFAR-10 結果:
bash scripts/table_1_cifar10.sh wrn_28_10在 Shake-Shake (26 2x96d) 上重現簡化的 SVHN 結果:
bash scripts/table_4_svhn.sh rsvhn_ss_96一個好的起點是 Wide-ResNet-28-10 上的簡化 SVHN,它可以在 Titan XP GPU 上在 10 分鐘內完成,達到 91% 以上的測試精度。
在 1800 個 epoch 上運行較大的模型可能需要多天的訓練。例如,CIFAR-10 PyramidNet+ShakeDrop 在 Tesla V100 GPU 上大約需要 9 天。
使用檔案scripts/search.sh在 Wide-ResNet-40-2 上執行 PBA 搜尋。需要一個參數,即資料集名稱。選項是rsvhn或rcifar10 。
指定部分 GPU 大小以在相同 GPU 上啟動多個試驗。簡化的 SVHN 在 Titan XP GPU 上大約需要一個小時,簡化的 CIFAR-10 大約需要 5 小時。
CUDA_VISIBLE_DEVICES=0 bash scripts/search.sh rsvhn搜尋中使用的結果調度可以從 Ray 結果目錄中檢索,並且可以使用pba/utils.py中的parse_log()函數將日誌檔案轉換為策略調度。例如,在簡化的 CIFAR-10 上學習超過 200 個時期的策略計劃被分為機率和幅度超參數值(每個增強操作的兩個值被合併)並可視化如下:
| 隨時間變化的機率超參數 | 超參數隨時間變化的幅度 |
|---|---|
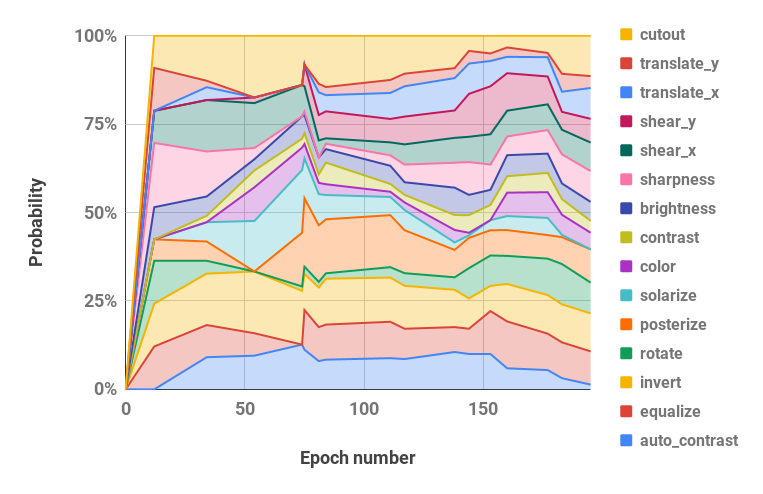 | 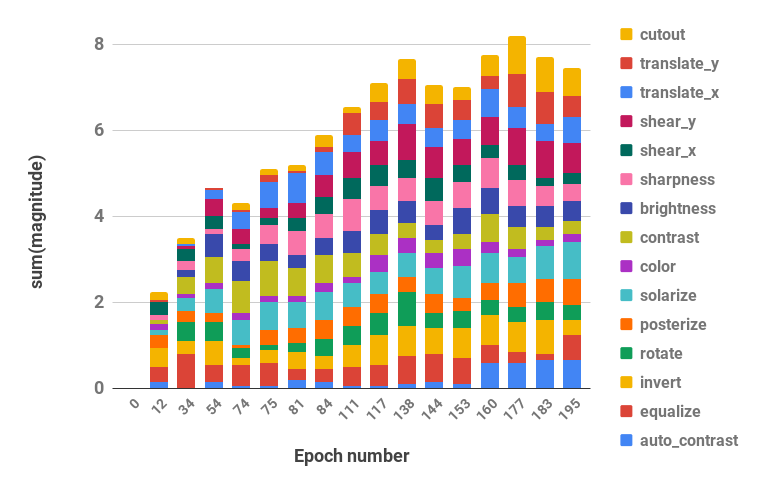 |
如果您在研究中使用 PBA,請引用:
@inproceedings{ho2019pba,
title = {Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules},
author = {Daniel Ho and
Eric Liang and
Ion Stoica and
Pieter Abbeel and
Xi Chen
},
booktitle = {ICML},
year = {2019}
}


