L2C
1.0.0
具有深度神經網路的聚類策略。這篇部落格文章提供了一般概述。
此儲存庫提供了遷移學習方案 (L2C) 的 PyTorch 實作以及對深度聚類有用的兩個學習標準:
*由CCL更名而來
該存儲庫涵蓋以下參考文獻:
@inproceedings{Hsu19_MCL,
title = {Multi-class classification without multi-class labels},
author = {Yen-Chang Hsu, Zhaoyang Lv, Joel Schlosser, Phillip Odom, Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2019},
url = {https://openreview.net/forum?id=SJzR2iRcK7}
}
@inproceedings{Hsu18_L2C,
title = {Learning to cluster in order to transfer across domains and tasks},
author = {Yen-Chang Hsu and Zhaoyang Lv and Zsolt Kira},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2018},
url = {https://openreview.net/forum?id=ByRWCqvT-}
}
@inproceedings{Hsu16_KCL,
title = {Neural network-based clustering using pairwise constraints},
author = {Yen-Chang Hsu and Zsolt Kira},
booktitle = {ICLR workshop},
year = {2016},
url = {https://arxiv.org/abs/1511.06321}
}
此儲存庫支援 PyTorch 1.0、python 2.7、3.6 和 3.7。
pip install -r requirements.txt # A quick trial:
python demo.py # Default Dataset:MNIST, Network:LeNet, Loss:MCL
python demo.py --loss KCL
# Lookup available options:
python demo.py -h
# For more examples:
./scripts/exp_supervised_MCL_vs_KCL.sh # Learn the Similarity Prediction Network (SPN) with Omniglot_background and then transfer to the 20 alphabets in Omniglot_evaluation.
# Default loss is MCL with an unknown number of clusters (Set a large cluster number, i.e., k=100)
# It takes about half an hour to finish.
python demo_omniglot_transfer.py
# An example of using KCL and set k=gt_#cluster
python demo_omniglot_transfer.py --loss KCL --num_cluster -1
# Lookup available options:
python demo_omniglot_transfer.py -h
# Other examples:
./scripts/exp_unsupervised_transfer_Omniglot.sh| 數據集 | gt #class | KCL (k=100) | MCL (k=100) | KCL (k=gt) | MCL (k=gt) |
|---|---|---|---|---|---|
| 天使般的 | 20 | 73.2% | 82.2% | 89.0% | 91.7% |
| Atemayar_Qelisayer | 26 | 73.3% | 89.2% | 82.5% | 86.0% |
| 亞特蘭提斯 | 26 | 65.5% | 83.3% | 89.4% | 93.5% |
| 奧雷克貝什 | 26 | 88.4% | 92.8% | 91.5% | 92.4% |
| 阿維斯塔 | 26 | 79.0% | 85.8% | 85.4% | 86.1% |
| Ge_ez | 26 | 77.1% | 84.0% | 85.4% | 86.6% |
| 格拉哥裡系 | 45 | 83.9% | 85.3% | 84.9% | 87.4% |
| 古爾穆基 | 45 | 78.8% | 78.7% | 77.0% | 78.0% |
| 卡納達語 | 41 | 64.6% | 81.1% | 73.3% | 81.2% |
| 基布爾 | 26 | 91.4% | 95.1% | 94.7% | 94.3% |
| 馬拉雅拉姆語 | 47 | 73.5% | 75.0% | 72.7% | 73.0% |
| 曼尼普里 | 40 | 82.8% | 81.2% | 85.8% | 81.5% |
| 蒙 | 30 | 84.7% | 89.0% | 88.3% | 90.2% |
| 舊教堂斯拉夫西里爾文 | 45 | 89.9% | 90.7% | 88.7% | 89.8% |
| 奧裡亞語 | 46 | 56.5% | 73.4% | 63.2% | 75.3% |
| 錫爾赫蒂 | 28 | 61.8% | 68.2% | 69.8% | 80.6% |
| 敘利亞語_Serto | 23 | 72.1% | 82.0% | 85.8% | 89.8% |
| 騰瓦 | 25 | 67.7% | 76.4% | 82.5% | 85.5% |
| 藏 | 42 | 81.8% | 80.2% | 84.3% | 81.9% |
| 烏洛格 | 26 | 53.3% | 77.1% | 73.0% | 89.1% |
| - 平均的 - | 75.0% | 82.5% | 82.4% | 85.7% |
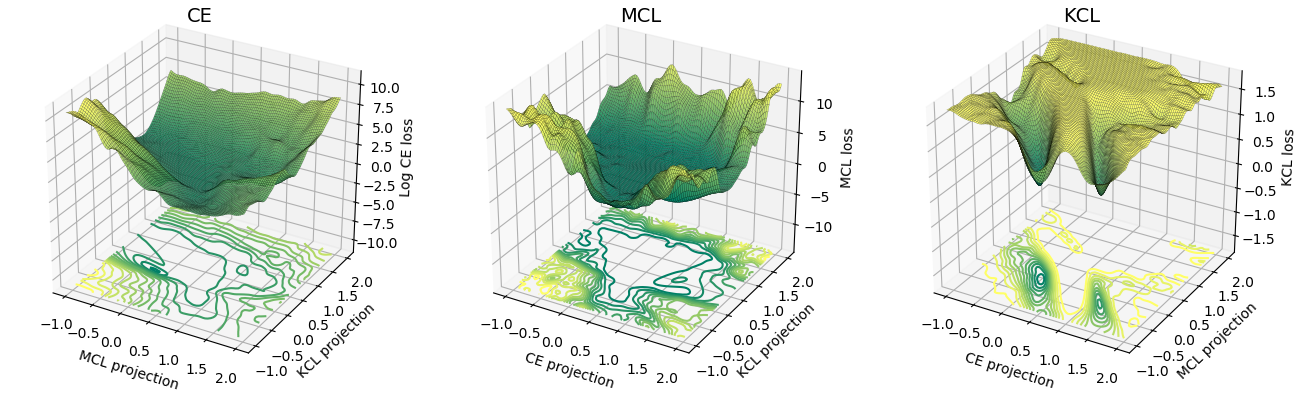
MCL 的損失表面比 KCL 更類似交叉熵(CE)。根據經驗,MCL 比 KCL 收斂得更快。詳細內容請參考 ICLR 論文。
@article{Hsu18_InsSeg,
title = {Learning to Cluster for Proposal-Free Instance Segmentation},
author = {Yen-Chang Hsu, Zheng Xu, Zsolt Kira, Jiawei Huang},
booktitle = {accepted to the International Joint Conference on Neural Networks (IJCNN)},
year = {2018},
url = {https://arxiv.org/abs/1803.06459}
}
這項工作得到了國家科學基金會和國家機器人計劃(撥款號 IIS-1426998)和 DARPA 的終身學習機器(L2M)計劃的支持,根據合作協議 HR0011-18-2-001。


