lion pytorch
0.2.3
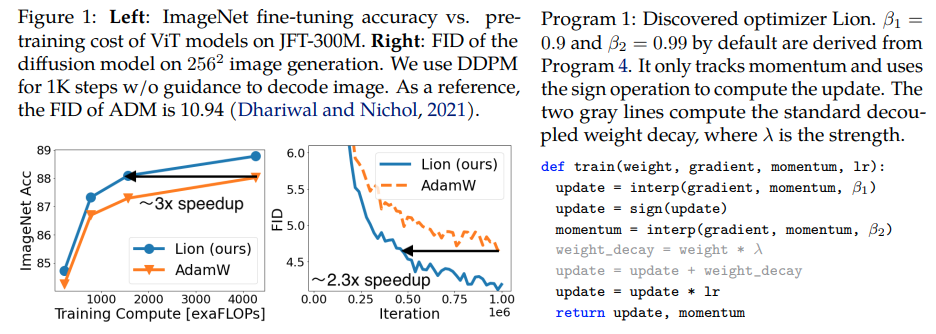
Lion,Evo L ved Sign Momentum ,Google Brain 發現的新優化器,據稱比 Pytorch 中的 Adam(w) 更好。這幾乎是這裡的直接副本,只做了一些小的修改。
它是如此簡單,如果它真的有效的話,我們不妨盡快讓每個人都可以使用它來訓練一些偉大的模型?
學習率和權重衰減:作者在第 5 節中寫道 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength.研究人員證明,與 AdamW 相比,學習率表中的初始值、峰值和最終值應以相同的比率同時變化。
學習率計畫:作者在論文中對 Lion 使用了與 AdamW 相同的學習率計畫。儘管如此,與倒數平方根方案相比,他們在使用餘弦衰減方案訓練 ViT 時觀察到了更大的增益。
β1 和 β2:作者在第 5 節中寫道 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively.作者建議,與人們在 AdamW 中將 β2 減小到 0.99 或更小並將 ε 增加到 1e-6 以提高穩定性類似,在 Lion 中使用β1=0.95, β2=0.98也有助於減輕訓練期間的不穩定。這一點得到了一位研究人員的證實。
更新:似乎適用於我本地的 enwik8 自回歸語言模型。
更新 2:實驗,如果學習率保持不變,似乎比 Adam 更糟。
更新 3:將學習率除以 3,看到比 Adam 更好的早期結果。近十年後,也許亞當已經被廢黜了。
更新 4:使用論文中 10 倍較小的學習率經驗法則會導致最差的運行。所以我想它仍然需要一些調整。
先前更新的總結:如實驗所示,Lion以小3倍的學習率擊敗了Adam。它仍然需要一些調整,因為 10 倍小的學習率會導致更糟糕的結果。
更新 5:到目前為止,如果做得正確的話,我們聽到了語言建模的所有正面結果。也聽到了重要的文字到圖像訓練的積極結果,儘管需要一些調整。負面結果似乎與論文中評估的問題和架構無關——RL、前饋網路、帶有 LSTM + 卷積的奇怪混合架構等。 。待定最佳學習率計畫是什麼,以及冷卻時間是否會影響結果。有趣的是,在開放剪輯中也有一個積極的結果,隨著模型尺寸的擴大,結果變成了消極的(但可能是可解析的)。
更新6:作者透過設定更高的初始溫度解決了開夾問題。
更新 7:僅在高批量大小(64 或以上)設定中推薦此優化器
$ pip 安裝 lion-pytorch
或者,使用 conda:
$ conda 安裝 lion-pytorch
# 玩具模型導入torchfrom torch import nnmodel = nn.Linear(10, 1)# 導入Lion 並使用參數實例化from lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2) # 向前和backsloss = model(torch.randn(10))loss.backward()# 優化器 stepopt.step()opt.zero_grad()
要使用融合核心來更新參數,首先pip install triton -U --pre ,然後
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # 將其設為 True 以使用帶有 Triton lang 的 cuda 內核 (Tillet 等人))
Stability.ai 對工作和開源尖端人工智慧研究的慷慨贊助
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {陳,向寧和梁,陳和黃,達和Real , Esteban 和Wang、Kaiyuan 和Liu、Yao 和Pham、Hieu 和Dong、Xuanyi 和Luong、Thang 和Hsieh、Cho-Jui 和Lu、Yifeng 和Le、Quoc V.},title = {優化演算法的符號發現}, publisher = {arXiv},年份 = {2023}} @article{Tillet2019TritonAI,title = {Triton: 用於平鋪神經網路計算的中間語言和編譯器},author = {Philippe Tillet and H. Kung and D. Cox},journal = {第三屆ACM SIGPLAN 國際機器研討會論文集學習與程式語言},年份 = {2019}} @misc{Schaipp2024,作者 = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {謹慎的優化器:一行代碼改進訓練},author = {Kaizhao Liang 和 Lizhang Chen 和 Bo Liu 和 Qiang Liu},year = {2024},url = {https://api . semanticscholar.org/CorpusID:274234738}} 

