RoboFlamingo
1.0.0
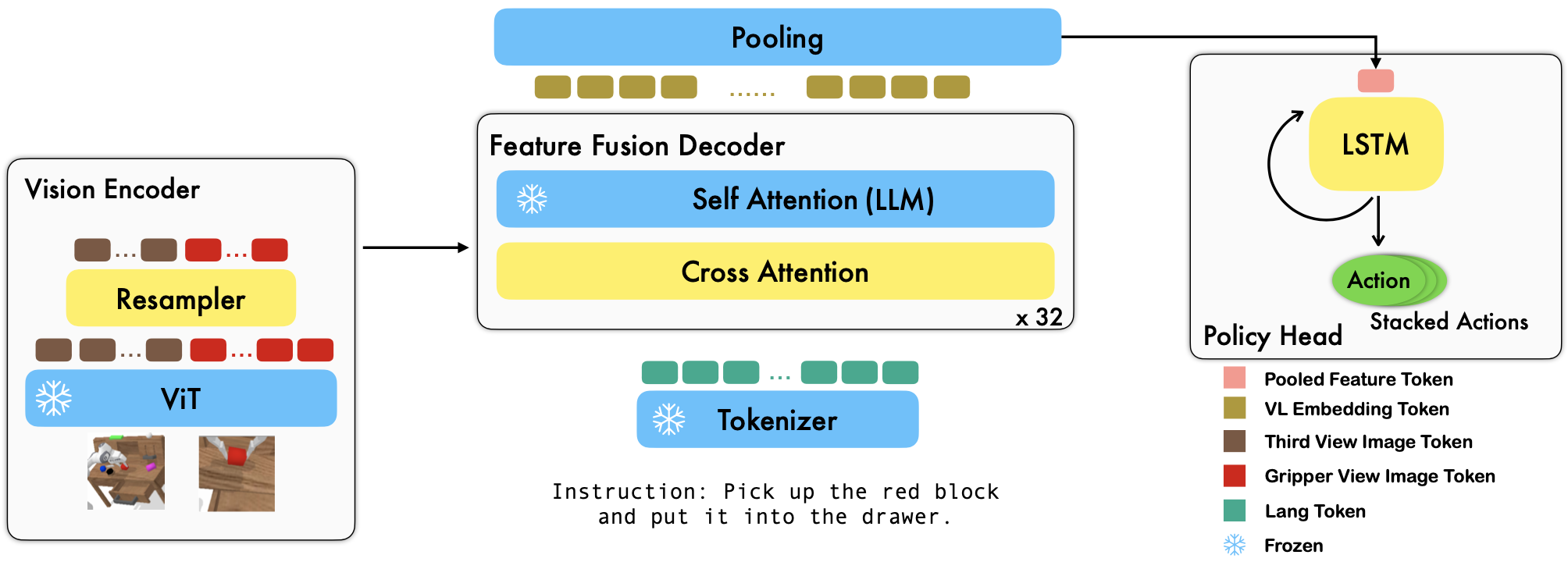
RoboFlamingo是一個基於 VLM 的預訓練機器人學習框架,透過對離線自由形式模仿資料集進行微調來學習各種語言調節的機器人技能。透過在 CALVIN 基準上大幅超越最先進的性能,我們表明 RoboFlamingo 可以成為使 VLM 適應機器人控制的有效且有競爭力的替代方案。我們廣泛的實驗結果也揭示了關於不同預訓練 VLM 在操作任務上的行為的幾個有趣的結論。 RoboFlamingo 可以在單一 GPU 伺服器上進行訓練或評估(GPU 記憶體需求取決於模型大小),我們相信 RoboFlamingo 有潛力成為一種經濟高效且易於使用的機器人操作解決方案,讓每個人都能獲得微調自己的機器人政策的能力。
這也是論文《視覺語言基礎模型作為有效機器人模仿者》的官方程式庫。
我們所有的實驗都是在具有 8 個 Nvidia A100 GPU (80G) 的單一 GPU 伺服器上進行的。
Hugging Face 上提供了預訓練模式。
我們支援 OpenCLIP 套件中的預訓練視覺編碼器,其中包括 OpenAI 的預訓練模型。我們也支援transformers套件中的預訓練語言模型,例如 MPT、RedPajama、LLaMA、OPT、GPT-Neo、GPT-J 和 Pythia 模型。
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) cross_attn_every_n_layers參數控制交叉注意力層的應用頻率,並且應該與 VLM 一致。 decoder_type參數控制解碼器的類型,目前,我們支援lstm 、 fc 、 diffusion (資料載入器有錯誤)和GPT 。
我們報告 CALVIN 基準測試的結果。
| 方法 | 訓練資料 | 測試拆分 | 1 | 2 | 3 | 4 | 5 | 平均長度 |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD(完整) | D | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| HULC | ABCD(完整) | D | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| HULC(重新訓練) | ABCD(郎) | D | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1(重新訓練) | ABCD(郎) | D | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| 我們的 | ABCD(郎) | D | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| MCIL | ABC(完整) | D | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| HULC | ABC(完整) | D | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1(重新訓練) | ABC(郎) | D | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| 我們的 | ABC(郎) | D | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| HULC | ABCD(完整) | D(豐富) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1(重新訓練) | ABCD(郎) | D(豐富) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| 我們的 | ABCD(郎) | D(豐富) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| 我們的(冷凍嵌入) | ABCD(郎) | D(豐富) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
依照 OpenFlamingo 和 CALVIN 中的說明下載必要的資料集和 VLM 預訓練模型。
下載 CALVIN 資料集,選擇一個分割:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debug下載已發布的 OpenFlamingo 模型:
| # 參數 | 語言模型 | 視覺編碼器 | Xattn 間隔* | COCO 4 瓶蘋果酒 | VQAv2 4 次精度 | 平均長度 | 重量 |
|---|---|---|---|---|---|---|---|
| 3B | 阿納斯-阿瓦達拉/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | 關聯 |
| 3B | 阿納斯-阿瓦達拉/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | 關聯 |
| 4B | 一起電腦/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | 關聯 |
| 4B | Togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | 關聯 |
| 9B | 阿納斯-阿瓦達拉/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | 關聯 |
將robot_flamingo/models/factory.py中每個預先訓練 VLM 的路徑字典(例如mpt_dict )的${lang_encoder_path}和${tokenizer_path}替換為您自己的路徑。
克隆這個倉庫
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
安裝所需的軟體包:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path}是CALVIN資料集的路徑;
${lm_path}是預先訓練的LLM的路徑;
${tokenizer_path}是VLM分詞器的路徑;
${openflamingo_checkpoint}是OpenFlamingo預訓練模型的路徑;
${log_file}是日誌檔案的路徑。
我們也提供了robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash來啟動訓練。這個bash對OpenFlamingo模型的MPT-3B-IFT版本進行了微調,其中包含訓練模型的預設超參數,並且對應於論文中的最佳結果。
python eval_ckpts.py
透過將檢查點名稱和目錄新增至eval_ckpts.py中,腳本將自動載入模型並對其進行評估。 For example, if you want to evaluate the checkpoint at path 'your-checkpoint-path', you can modify the ckpt_dir and ckpt_names variables in eval_ckpts.py, and the evaluation results would be saved as 'logs/your-checkpoint-prefix.紀錄'.
下面顯示的結果表明,協同訓練可以保留 VLM 主幹在 VL 任務上的大部分能力,同時在機器人任務上損失一些表現。
使用
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
與 CoCO、VQAV2 和 CALVIN 聯合訓練 RoboFlamingo。您應該更新robot_flamingo/data/data.py中get_coco_dataset和get_vqa_dataset中的 CoCO 和 VQA 路徑。
| 分裂 | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | 平均長度 |
|---|---|---|---|---|---|---|
| 協同訓練 | ABC->D | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| 微調 | ABC->D | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| 協同訓練 | ABCD->D | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| 微調 | ABCD->D | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| 協同訓練 | ABCD->D(豐富) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| 微調 | ABCD->D(豐富) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| 可可 | 品質保證 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | 藍二號 | BLEU-3 | BLEU-4 | 流星 | 胭脂_L | 蘋果酒 | 香料 | 加速器 | |
| 微調(3B,零樣本) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| 微調(3B、4 鏡頭) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| 協同訓練(3B,零樣本) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| 原始火烈鳥(80B,微調) | - | - | - | - | - | - | 1.381 | - | 82.0 |
該標誌是使用 MidJourney 產生的
這項工作使用以下開源專案和資料集的程式碼:
原文:https://github.com/mees/calvin 授權:MIT
原文:https://github.com/openai/CLIP 授權:MIT
原文:https://github.com/mlfoundations/open_flamingo 授權:MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


