RobustSAM
1.0.0
RobustSAM 的官方儲存庫:在降級影像上穩健地分割任何內容
項目頁面|紙|影片 |數據集
2024 年 8 月:您可以透過此連結參考 @jadechoghari 建立的 Hugging Face 模型卡和演示,以便更輕鬆地使用。
2024年7月:針對不同ViT主幹的訓練程式碼、資料和模型檢查點發布!
2024年6月:推理程式碼已發布!
2024 年 2 月:RobustSAM 被 CVPR 2024 接收!
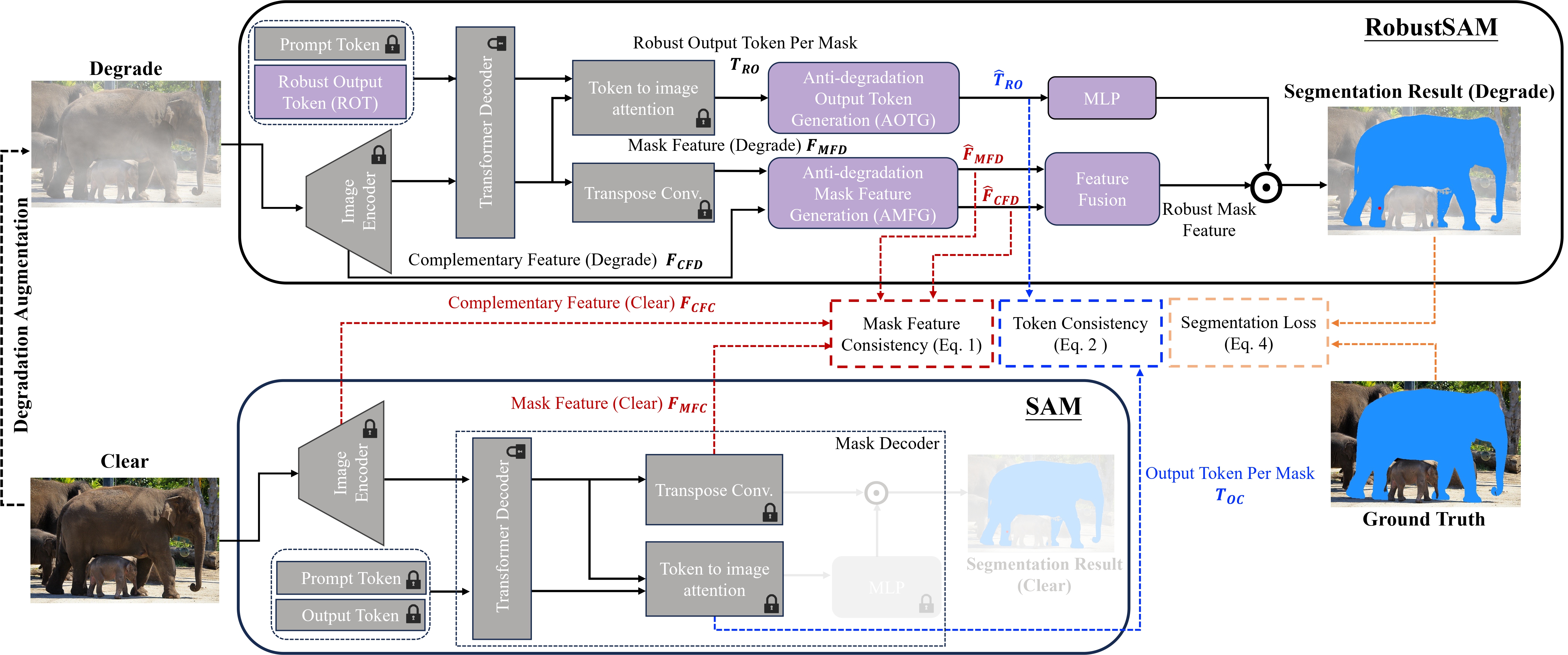
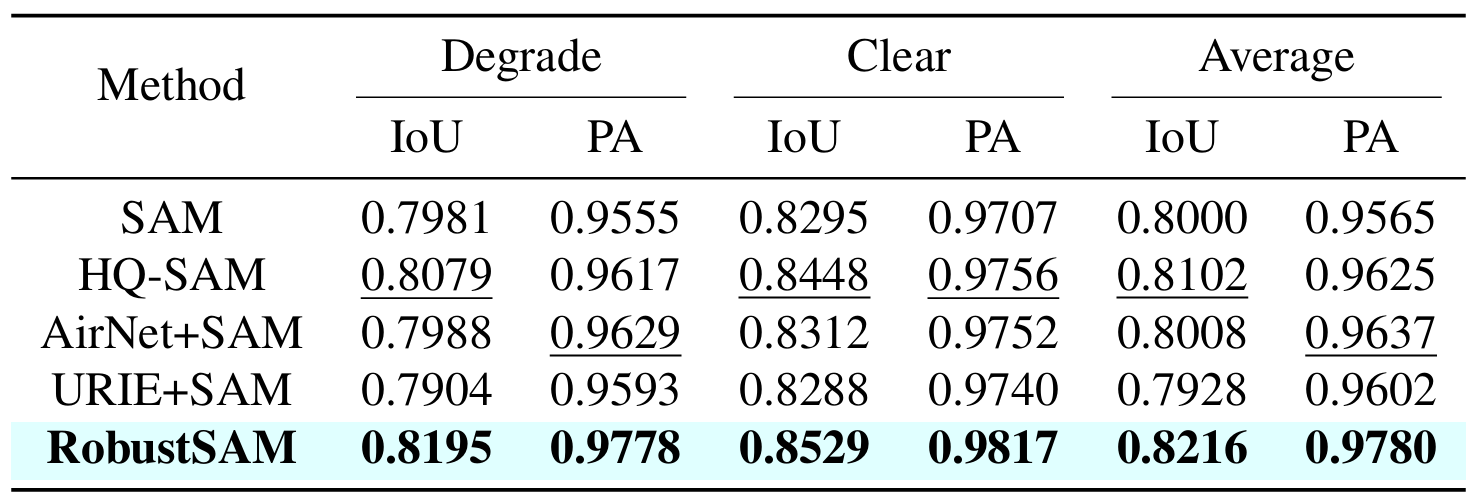
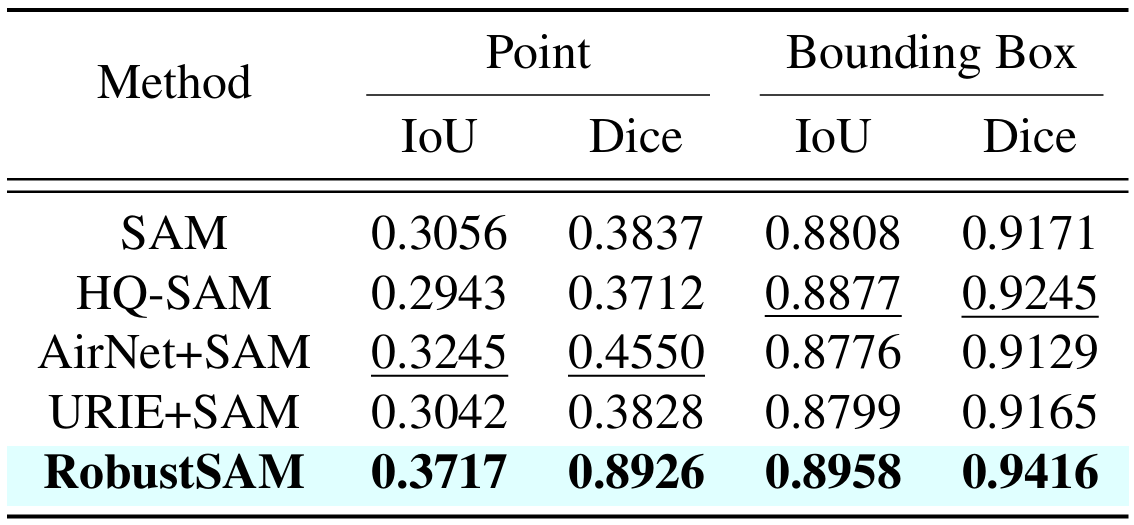
分段任意模型 (SAM) 已成為影像分割領域的一種變革性方法,因其強大的零樣本分割功能和靈活的提示系統而備受讚譽。儘管如此,其性能仍受到影像品質下降的挑戰。為了解決這個限制,我們提出了穩健分段任意模型 (RobustSAM),它增強了 SAM 在低品質影像上的效能,同時保留了其及時性和零樣本泛化能力。
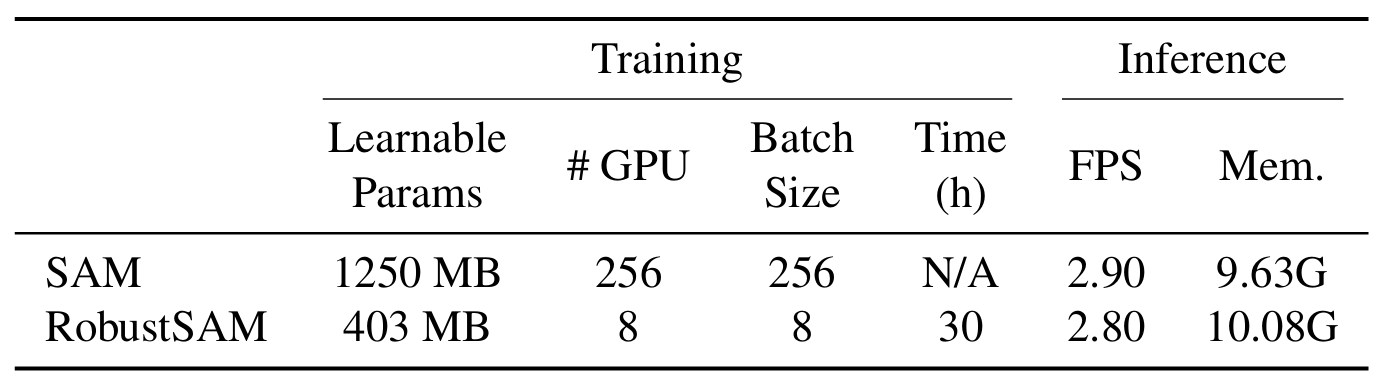
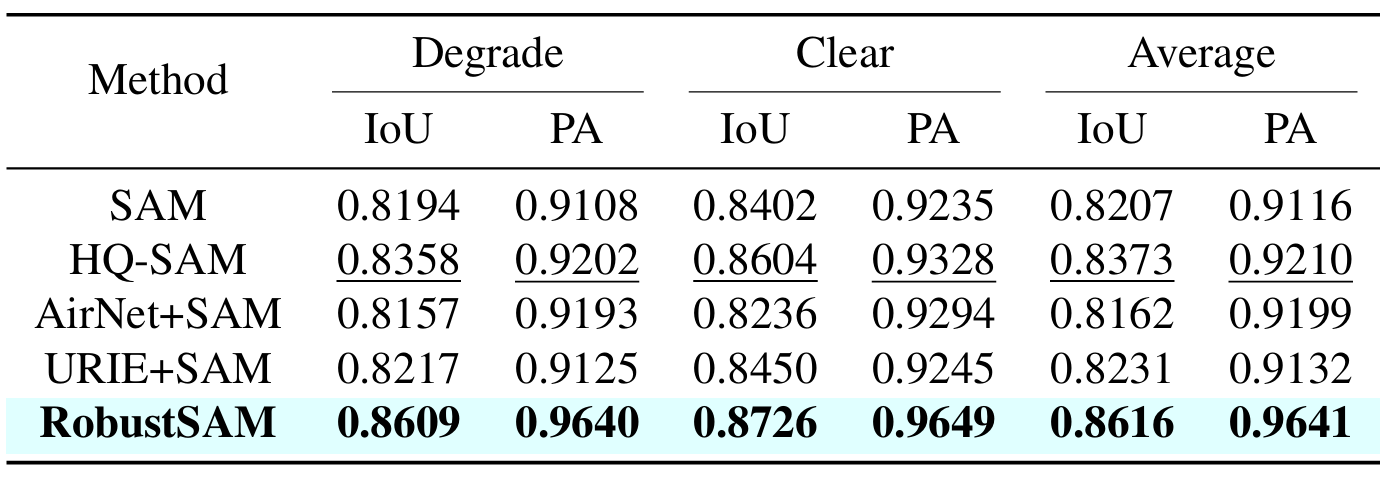
我們的方法利用預先訓練的 SAM 模型,僅具有邊際參數增量和計算需求。 RobustSAM 的附加參數可在 8 個 GPU 上在 30 小時內最佳化,這證明了其對於典型研究實驗室的可行性和實用性。我們還介紹了 Robust-Seg 資料集,這是一個具有不同退化的 688K 影像掩模對的集合,旨在最佳地訓練和評估我們的模型。跨各種分割任務和資料集的大量實驗證實了 RobustSAM 的卓越性能,尤其是在零樣本條件下,強調了其在現實世界中廣泛應用的潛力。此外,我們的方法已被證明可以有效提高基於 SAM 的下游任務(例如單一影像去霧和去模糊)的效能。
創建conda環境並啟動它。
conda create --name robustsam python=3.10 -y conda activate robustsam
克隆並進入 repo 目錄。
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
使用下面的命令檢查您的 CUDA 版本。
nvidia-smi
在下面的命令中將 CUDA 版本替換為您的版本。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
安裝剩餘的依賴項
pip install -r requirements.txt
下載不同大小的預訓練 RobustSAM 檢查點並將它們放入目前目錄。
ViT-B RobustSAM 檢查點
ViT-L RobustSAM 檢查點
ViT-H RobustSAM 檢查點
將目前目錄變更為“data”目錄。
cd data
下載訓練、驗證、測試和額外的 COCO 和 LVIS 資料集。 (註:訓練、驗證和測試資料集中的影像包含來自 LVIS、MSRA10K、ThinObject-5k、NDD20、STREETS 和 FSS-1000 的影像)
bash download.sh
上一步中僅下載了清晰的圖像。使用下面的命令產生相應的降級圖像。
bash gen_data.sh
如果您想從頭開始訓練,請使用下面的命令。
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
如果您想從預先訓練的檢查點進行訓練,請使用下面的命令。
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
我們在demo_images資料夾中準備了一些圖像用於演示目的。此外,還有兩種提示方式(框提示和點提示)。
對於框提示:
python eval.py --bbox --model_size l
對於點提示:
python eval.py --model_size l
預設情況下,演示結果將儲存到demo_result/[$PROMPT_TYPE] 。
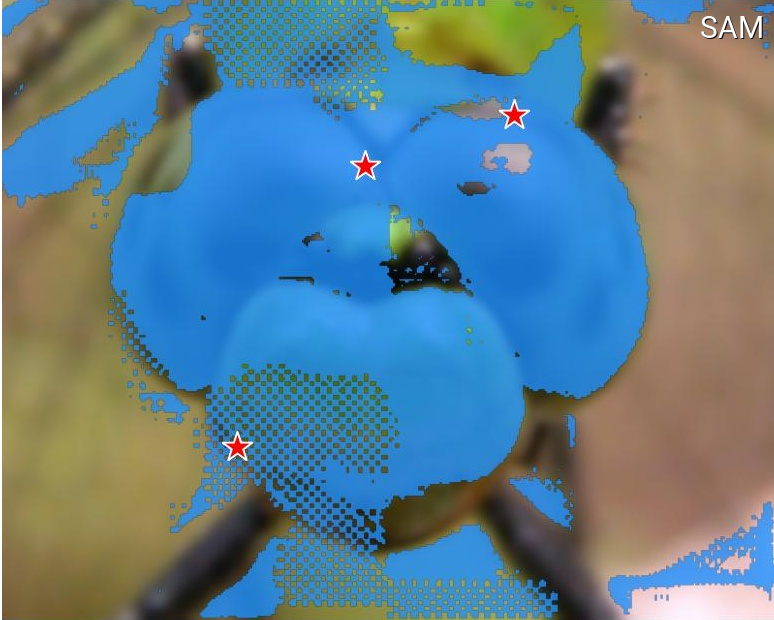 |  |
 |  |

如果您發現這項工作有用,請考慮引用我們!
@inproceedings{chen2024robustsam,title={RobustSAM:在退化圖像上魯棒地分割任何東西},作者={Chen,Wei-Ting and Vong,Yu-Jiet and Kuo,Sy-Yen and Ma,Sizhou and Wang,Jian },journal= {CVPR},年份={2024}}我們感謝我們的儲存庫所基於的 SAM 的作者。


