toyCarIRL
1.0.0
強化學習(RL)是試誤學習的最基本、最直觀的形式,它是大多數具有某種思考能力的生物體學習的方式。通常被稱為探索學習,這是新生兒學習邁出第一步的方式,即首先採取隨機動作,然後慢慢找出導致向前行走運動的動作。
請注意,本文假設您對強化學習框架有很好的了解,請透過這門精彩線上課程 AI_Berkeley 的第 5 週和第 6 週熟悉 RL。
現在我一直問自己的問題是,這種學習的驅動力是什麼,是什麼迫使智能體以它正在做的方式學習特定的行為。在了解更多關於 RL 的知識後,我想到了獎勵的概念,基本上,代理人試圖以這樣的方式選擇其行為,即從特定行為中獲得的獎勵最大化。現在,為了使代理人執行不同的行為,必須修改/利用獎勵結構。但假設我們只了解專家的行為,那麼我們該如何估計環境中特定行為的獎勵結構呢?嗯,這就是逆強化學習(IRL)的問題,在給定最優專家策略(實際上假設是最優)的情況下,我們希望確定潛在的獎勵結構。
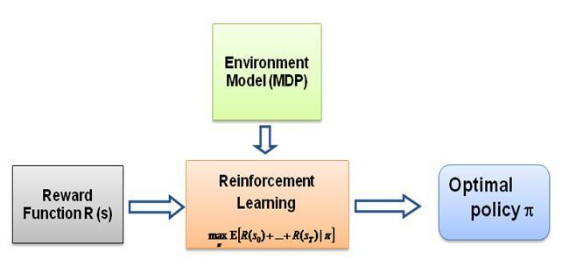
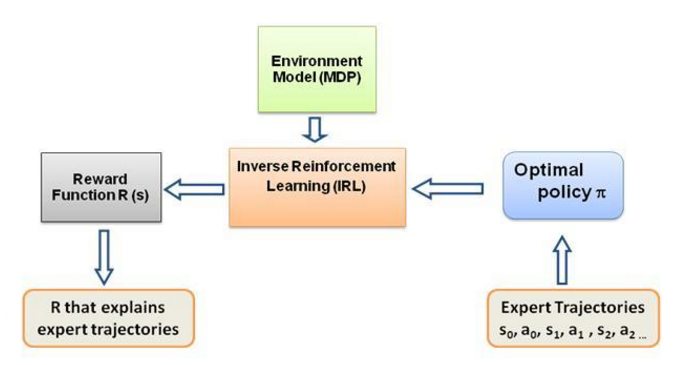
再說一次,這不是一篇關於逆向強化學習的介紹文章,而是關於如何使用/編碼逆向強化學習框架來解決您自己的問題的教程,但 IRL 是它的核心,了解它是最重要的首先。 IRL 過去已經被廣泛研究,並且已經開發了演算法,請瀏覽論文 Ng 和 Russell,2000,以及 Abbeel 和 Ng,2004 以獲取更多資訊。
這篇文章採用了 Abbeel 和 Ng,2004 年的演算法來解決 IRL 問題。
這裡的想法是在充滿障礙的 2D 世界中編寫一個簡單的代理來複製/克隆環境中的不同行為,這些行為是在人類/計算機專家手動給出的專家軌蹟的幫助下輸入的。這種從專家演示中學習的形式在科學文獻中被稱為學徒學習,其核心是逆強化學習,我們只是試圖找出這些不同行為的不同獎勵函數。
總的來說,是的,它們是同一件事,意思是從演示中學習(LfD)。兩種方法都從演示中學習,但它們學到的東西不同:
透過逆強化學習的學徒學習將嘗試推論老師的目標。換句話說,它將從觀察中學習獎勵函數,然後可以用於強化學習。如果它發現目標是用錘子敲釘子,它就會忽略老師的眨眼和抓撓,因為它們與目標無關。
模仿學習(又稱行為複製)會嘗試直接模仿老師。這可以僅透過監督學習來實現。人工智慧將嘗試複製每一個動作,甚至是不相關的動作,例如眨眼或抓撓,甚至是錯誤。你也可以在這裡使用強化學習,但前提是你要有獎勵函數。
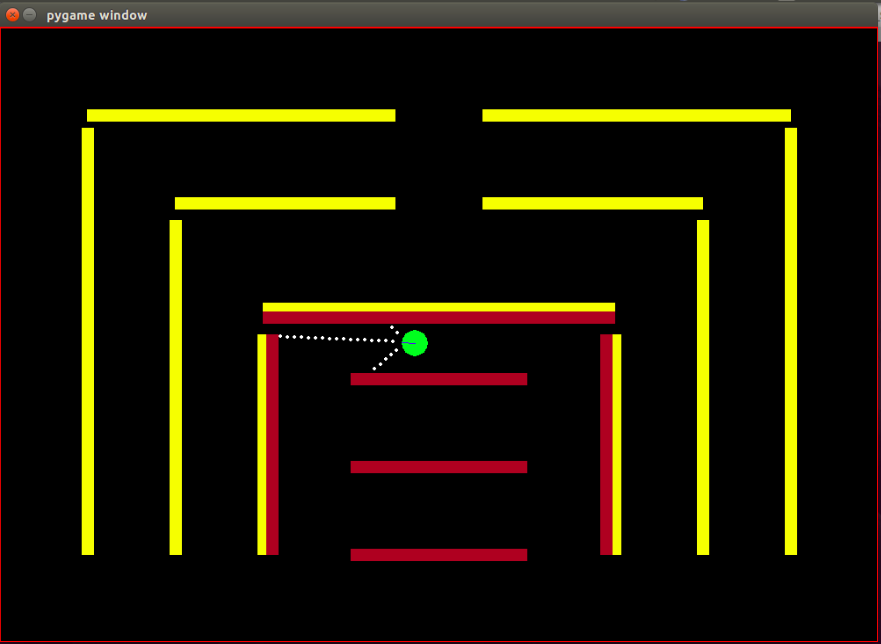
代理:代理是一個綠色小圓圈,其前進方向由藍線指示。
感測器:代理程式配備了 3 個距離感測器和顏色感測器,這是代理擁有的有關環境的唯一資訊。
狀態空間:代理人的狀態由 8 個可觀察的特徵組成 -
請注意,進行歸一化是為了確保每個可觀察的特徵值都在 [0,1] 範圍內,這是 IRL 演算法收斂的獎勵的必要條件。
獎勵:每幀後的獎勵被計算為在相應幀中觀察到的特徵值的加權線性組合。這裡第t幀的獎勵r_t是透過權重向量w與第t幀的特徵值向量的點積計算出來的,也就是狀態向量phi_t。這樣 r_t = w^T x phi_t。
可用動作:對於每個新幀,代理會自動向前邁出一步,可用動作可以將代理向左、向右轉動或不執行任何操作(即簡單的向前一步),請注意,轉動動作也包括向前運動,它不是原地旋轉。
障礙:環境由堅硬的牆壁組成,故意塗上不同的顏色。此代理具有顏色感應功能,有助於區分障礙物類型。這樣設計環境是為了方便測試IRL演算法。
機器人的起始位置(狀態)是固定的,因為根據 IRL 演算法,所有迭代的起始狀態必須相同。
請注意,強化學習演算法完全採用了 Matt Harvey 的這篇文章,只做了一些微小的修改,因此談論我所做的更改是非常有意義的,即使讀者對 RL 感到滿意,我也強烈建議瀏覽一下這篇文章是為了了解強化學習是如何發生的。
環境發生了顯著變化,智能體不僅能夠感知 3 個感測器的距離,還能感知障礙物的顏色,從而能夠區分障礙物。此外,代理的尺寸現在更小,其感測點現在更近,以獲得更高的解析度和更好的性能。現在必須將障礙物靜態化,以簡化測試IRL演算法的過程,這很可能會導致資料過度擬合,但我目前並不擔心這一點。如上所述,觀察集或代理狀態已從 3 個增加到 8 個,並且在代理狀態中包含了崩潰功能。獎勵結構完全改變,獎勵現在是這8個特徵的加權線性組合,智能體不再在碰撞障礙物時獲得-500獎勵,而是碰撞的特徵值為+1,不碰撞的特徵值為0,演算法根據專家的行為決定應該為該特徵分配什麼權重。
正如Matt 部落格所述,這裡的目的不僅僅是教導RL 代理避開障礙物,我的意思是為什麼要對獎勵結構做出任何假設,讓獎勵結構完全由專家演示中的演算法決定,看看會有什麼行為特定的獎勵設定達成!
特徵或基底函數phi_i 基本上是狀態中的可觀察值。當前問題的特徵已在上面的狀態空間部分中討論。我們將 phi(s_t) 定義為所有特徵期望 phi_i 的總和,這樣:
獎勵r_t - 在每個狀態 s_t 觀察到的這些特徵值的線性組合。
策略 pi 的特徵期望mu(pi) 是折扣特徵值 phi(s_t) 的總和。
策略的特徵期望與權重無關,它們僅依賴運行期間訪問的狀態(根據策略)以及折扣因子 gamma 0 到 1 之間的數字(例如,在我們的例子中為 0.9)。為了獲得策略的特徵期望,我們必須與代理程式一起即時執行策略並記錄存取的狀態和獲得的特徵值。
專家策略特徵期望或專家的特徵期望mu(pi_E)是根據專家行為採取的行動獲得的。我們基本上執行此策略並獲得功能期望,就像我們執行任何其他策略一樣。專家特徵期望被賦予 IRL 演算法以找到權重,使得與權重相對應的獎勵函數類似於專家試圖最大化的底層獎勵函數(以通常的 RL 語言)。
隨機策略特徵期望- 執行隨機策略並使用獲得的特徵期望初始化 IRL。
維護我們在每次迭代後獲得的策略功能期望清單。
一開始我們只有 pi^1 -> 隨機策略特徵期望。
透過凸優化找到 w^1 的第一組權重,該問題類似於 SVM 分類器,它試圖給專家特徵 expec 一個 +1 標籤。和 -1 標籤到所有其他策略功能預期。
這樣,
終止條件:
現在,一旦我們在一次最佳化迭代後獲得了權重,即一旦我們獲得了一個新的獎勵函數,我們就必須學習該獎勵函數所產生的策略。這相當於說,找到一個試圖最大化所獲得的獎勵函數的策略。為了找到這個新策略,我們必須使用這個新的獎勵函數來訓練強化學習演算法,並訓練它直到 Q 值收斂,以獲得策略的正確估計。
當我們學習到一個新的策略後,我們必須在線上測試這個策略,以獲得這個新策略對應的功能期望。然後,我們將這些新的特徵期望添加到我們的特徵期望列表中,並繼續進行,無需 IRL 演算法的下一次迭代,直到收斂。
現在讓我們嘗試掌握程式碼。請在此 git 儲存庫中找到完整的程式碼。您主要需要擔心 3 個文件 -
ManualControl.py - 透過手動移動代理來獲取專家的功能期望。運行“python3 manualControl.py”,等待 gui 加載,然後使用箭頭鍵開始移動。賦予它您希望它複製的行為(請注意,您希望它複製的行為對於給定的狀態空間應該是合理的)。一個好的技巧是假設你自己代替智能體,並思考你是否能夠僅在當前狀態空間的情況下區分給定的行為。有關更多詳細信息,請參閱來源文件。
toy_car_IRL.py - 主文件,這是 IRL 程式碼所在的位置。讓我們一步一步看一下程式碼 -
{%要點51542f27e97eac1559a00f06b757df1a%}
導入相依性並定義重要參數,根據需要變更行為。 FRAMES 是您希望 RL 演算法運行的幀數。 100K還可以,大約需要2小時。
{%要點49b602b9a3090773d492310175bb2e3f%}
創建易於使用的 irlAgent 類,該類接受隨機和專家行為以及如圖所示的其他重要參數。
{%要點bc17c06a07ea3b915827e89f3c13a2ae%}
getRLAgentFE 函數使用強化學習器中的 IRL_helper 來訓練新模型,並透過運行該模型 2000 次迭代來獲得特徵期望。它基本上返回其獲得的每組權重 (W) 的特徵期望。
{% 要點 ce0ef99adc652c7469f1bc4303a3af41 %}
更新我們保存獲得的策略及其各自的 t 值的字典。其中 t = (weights.tanspose)x(expert-newPolicy)。
{% 要點 be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
上面討論的主要 IRL 演算法的實現。 {%要點9faee18596467ee33ac5d91fd0cb675f%}
凸優化在收到新策略時更新權重,基本上為專家策略分配 +1 標籤,為所有其他策略分配 -1 標籤,並在上述限制下優化權重。要了解有關此優化的更多信息,請訪問網站
{%要點30cf6c59b9915054f3cf6d278f8f8a11%}
建立一個 irlAgent 並傳遞所需的參數,在您希望學習其權重的專家行為類型之間進行選擇,然後執行 optimizationWeightFinder() 函數。請注意,我已經獲得了紅色、黃色和棕色行為的特徵期望。演算法終止後,您將在「weights-red/yellow/brown.txt」中獲得權重列表,其中包含相應選定的行為。現在,要從所有獲得的權重中選擇最佳可能的行為,請播放saved-models_BEHAVIOR/evaluatedPolicies/目錄中保存的模型,模型以以下格式保存: 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+迭代次數+ '-164-150-100-50000-100000' + '.h5' 。基本上,不同的迭代你會得到不同的權重,先玩模型找出表現最好的模型,然後記下該模型的迭代次數,與該迭代次數對應的權重是讓你最接近專家的權重行為。
然後還有一些文件您可能不需要更新/修改,至少對於本文中的內容來說是這樣 -
經過大約 10-15 次迭代後,演算法在所有 4 種不同的選擇行為中收斂,我得到了以下結果:
| 重量 | 我喜歡黃色 | 我愛棕色 | 我愛紅色 | 我愛碰撞 |
|---|---|---|---|---|
| w1(左感測器距離) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2(中間感測器距離) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3(右感測器距離) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4(黑色) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| W5(黃色) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| W6(棕色) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| W7(紅色) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8(崩潰) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
前三個行為中屬於碰撞特徵的權重被賦予較高的負值,因為這 3 個專家行為不希望智能體碰撞到障礙物。而最後一個行為(即討厭的機器人)中相同特徵的權重是正的,因為專家行為提倡碰撞。
顯然,顏色特徵的權重與專家行為相關,當需要該顏色時權重較高,否則為相當低/負值以獲得獨特的行為。
距離特徵權重非常模糊(違反直覺),很難在權重中找出一些有意義的模式。我唯一想指出的是,在當前設定下甚至可以區分順時針和逆時針行為,距離特徵將攜帶此資訊。
請注意,在設計問題結構時,首先考慮您作為一個人是否能夠區分給定行為與當前狀態集(觀察)的可用性,這一點非常重要。否則,您可能只是強制演算法尋找不同的權重,而沒有完全提供必要的資訊。
如果你真的想進入 IRL,我建議你實際上嘗試教代理一種新的行為(你可能必須為此修改環境,因為當前狀態集可能的不同行為已經被利用了,好吧至少對我來說是這樣)。
安裝 Pygame 的依賴項:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
然後安裝 Pygame 本身:
pip3 install hg+http://bitbucket.org/pygame/pygame
這是模擬使用的物理引擎。它剛剛經歷了相當重要的重寫 (v5),因此您需要獲取舊的 v4 版本。 v4 是為 Python 2 編寫的,因此有幾個額外的步驟。
返回您的家或下載並取得 Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
拆開包裝:
tar zxvf pymunk-4.0.0.tar.gz
從 Python 2 更新到 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
安裝它:
cd .. python3 setup.py install
現在回到克隆reinforcement-learning-car位置,並確保一切都可以與快速python3 learning.py配合使用。如果您看到螢幕上出現一個小點在螢幕上飛來飛去,那麼您就可以開始了!
首先,您需要訓練一個模型。這會將權重保存到saved-models資料夾中。您可能需要在運行之前建立此資料夾。您可以透過執行以下命令來訓練模型:
python3 learning.py
訓練模型可能需要 1 小時到 36 小時不等,具體取決於網路的複雜性和樣本的大小。但是,它會每 25,000 幀輸出一次權重,因此您可以在更短的時間內進入下一步。
編輯playing.py檔案以更改要載入的模型的路徑名稱。對此感到抱歉,我知道它應該是命令列參數。
然後,觀看汽車自行繞過障礙物!
python3 playing.py
這就是全部內容了。


