An Awesome Collection for LLM in Chinese
收集和梳理中文LLM相關
自ChatGPT為代表的大語言模型(Large Language Model, LLM)出現以後,由於其驚人的類通用人工智能(AGI)的能力,掀起了新一輪自然語言處理領域的研究和應用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起來的較小規模的LLM開源之後,業界湧現了非常多基於LLM的二次微調或應用的案例。本項目旨在收集和梳理中文LLM相關的開源模型、應用、數據集及教程等資料,目前收錄的資源已達100+個!
如果本項目能給您帶來一點點幫助,麻煩點個️吧~
同時也歡迎大家貢獻本項目未收錄的開源模型、應用、數據集等。提供新的倉庫信息請發起PR,並按照本項目的格式提供倉庫鏈接、star數,簡介等相關信息,感謝~
常見底座模型細節概覽:
底座 包含模型 模型參數大小 訓練token數 訓練最大長度 是否可商用 ChatGLM ChatGLM/2/3/4 Base&Chat 6B 1T/1.4 2K/32K 可商用 LLaMA LLaMA/2/3 Base&Chat 7B/8B/13B/33B/70B 1T/2T 2k/4k 部分可商用 Baichuan Baichuan/2 Base&Chat 7B/13B 1.2T/1.4T 4k 可商用 Qwen Qwen/1.5/2/2.5 Base&Chat&VL 7B/14B/32B/72B/110B 2.2T/3T/18T 8k/32k 可商用 BLOOM BLOOM 1B/7B/176B-MT 1.5T 2k 可商用 Aquila Aquila/2 Base/Chat 7B/34B - 2k 可商用 InternLM InternLM/2/2.5 Base/Chat/VL 7B/20B - 200k 可商用 Mixtral Base&Chat 8x7B - 32k 可商用 Yi Base&Chat 6B/9B/34B 3T 200k 可商用 DeepSeek Base&Chat 1.3B/7B/33B/67B - 4k 可商用 XVERSE Base&Chat 7B/13B/65B/A4.2B 2.6T/3.2T 8k/16k/256k 可商用
目錄 目錄1. 模型 2. 應用2.1 垂直領域微調 2.2 LangChain應用 2.3 其他應用 3. 數據集 4. LLM訓練微調框架 5. LLM推理部署框架 6. LLM評測 7. LLM教程LLM基礎知識 提示工程教程 LLM應用教程 LLM實戰教程 8. 相關倉庫 Star History
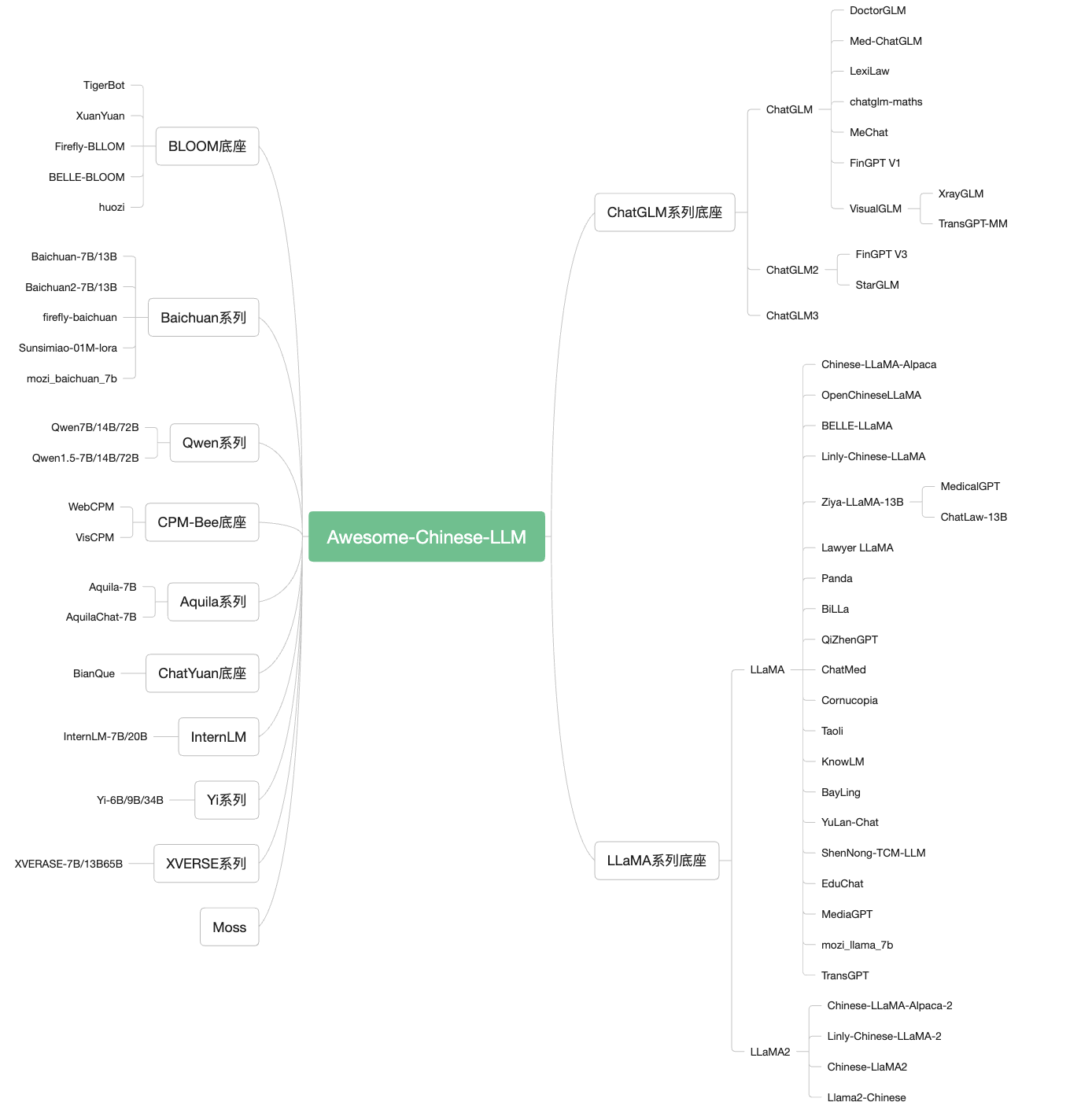
1. 模型
1.1 文本LLM模型 ChatGLM:地址:https://github.com/THUDM/ChatGLM-6B 簡介:中文領域效果最好的開源底座模型之一,針對中文問答和對話進行了優化。經過約1T 標識符的中英雙語訓練,輔以監督微調、反饋自助、人類反饋強化學習等技術的加持 ChatGLM2-6B地址:https://github.com/THUDM/ChatGLM2-6B 簡介:基於開源中英雙語對話模型ChatGLM-6B 的第二代版本,在保留了初代模型對話流暢、部署門檻較低等眾多優秀特性的基礎之上,引入了GLM 的混合目標函數,經過了1.4 T 中英標識符的預訓練與人類偏好對齊訓練;基座模型的上下文長度擴展到了32K,並在對話階段使用8K 的上下文長度訓練;基於Multi-Query Attention 技術實現更高效的推理速度和更低的顯存佔用;允許商業使用。 ChatGLM3-6B地址:https://github.com/THUDM/ChatGLM3 簡介:ChatGLM3-6B 是ChatGLM3 系列中的開源模型,在保留了前兩代模型對話流暢、部署門檻低等眾多優秀特性的基礎上,ChatGLM3-6B 引入瞭如下特性:更強大的基礎模型: ChatGLM3- 6B 的基礎模型ChatGLM3-6B-Base 採用了更多樣的訓練數據、更充分的訓練步數和更合理的訓練策略;更完整的功能支持: ChatGLM3-6B 採用了全新設計的Prompt 格式,除正常的多輪對話外。同時原生支持工具調用(Function Call)、代碼執行(Code Interpreter)和Agent 任務等複雜場景;更全面的開源序列: 除了對話模型ChatGLM3-6B 外,還開源了基礎模型ChatGLM3-6B-Base、長文本對話模型ChatGLM3-6B-32K。以上所有權重對學術研究完全開放,在填寫問捲進行登記後亦允許免費商業使用。 GLM-4地址:https://github.com/THUDM/GLM-4 簡介:GLM-4-9B 是智譜AI 推出的最新一代預訓練模型GLM-4 系列中的開源版本。 在語義、數學、推理、代碼和知識等多方面的數據集測評中, GLM-4-9B 及其人類偏好對齊的版本GLM-4-9B-Chat 均表現出超越Llama-3-8B 的卓越性能。除了能進行多輪對話,GLM-4-9B-Chat 還具備網頁瀏覽、代碼執行、自定義工具調用(Function Call)和長文本推理(支持最大128K 上下文)等高級功能。本代模型增加了多語言支持,支持包括日語,韓語,德語在內的26 種語言。我們還推出了支持1M 上下文長度(約200 萬中文字符)的GLM-4-9B-Chat-1M 模型和基於GLM-4-9B 的多模態模型GLM-4V-9B。 GLM-4V -9B具備1120 * 1120 高分辨率下的中英雙語多輪對話能力,在中英文綜合能力、感知推理、文字識別、圖表理解等多方面多模態評測中,GLM-4V-9B 表現出超越GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和Claude 3 Opus 的卓越性能。 Qwen/Qwen1.5/Qwen2/Qwen2.5地址:https://github.com/QwenLM 簡介:通義千問是阿里雲研發的通義千問大模型系列模型,包括參數規模為18億(1.8B)、70億(7B)、140億(14B)、720億(72B)和1100億(110B)。各個規模的模型包括基礎模型Qwen,以及對話模型。數據集包括文本和代碼等多種數據類型,覆蓋通用領域和專業領域,能支持8~32K的上下文長度,針對插件調用相關的對齊數據做了特定優化,當前模型能有效調用插件以及升級為Agent 。 InternLM地址:https://github.com/InternLM/InternLM-techreport 簡介:商湯科技、上海AI實驗室聯合香港中文大學、復旦大學和上海交通大學發布千億級參數大語言模型“書生·浦語”(InternLM)。據悉,“書生·浦語”具有1040億參數,基於“包含1.6萬億token的多語種高質量數據集”訓練而成。 InternLM2地址:https://github.com/InternLM/InternLM 簡介:商湯科技、上海AI實驗室聯合香港中文大學、復旦大學和上海交通大學發布千億級參數大語言模型“書生·浦語”(InternLM2)。 InternLM2 在數理、代碼、對話、創作等各方面能力都獲得了長足進步,綜合性能達到開源模型的領先水平。 InternLM2 包含兩種模型規格:7B 和20B。 7B 為輕量級的研究和應用提供了一個輕便但性能不俗的模型,20B 模型的綜合性能更為強勁,可以有效支持更加複雜的實用場景。 DeepSeek-V2地址:https://github.com/deepseek-ai/DeepSeek-V2 簡介:DeepSeek-V2:強大、經濟、高效的專家混合語言模型 Baichuan-7B地址:https://github.com/baichuan-inc/Baichuan-7B 簡介:由百川智能開發的一個開源可商用的大規模預訓練語言模型。基於Transformer結構,在大約1.2萬億tokens上訓練的70億參數模型,支持中英雙語,上下文窗口長度為4096。在標準的中文和英文權威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。 Baichuan-13B地址:https://github.com/baichuan-inc/baichuan-13B 簡介:Baichuan-13B 是由百川智能繼Baichuan-7B 之後開發的包含130 億參數的開源可商用的大規模語言模型,在權威的中文和英文benchmark 上均取得同尺寸最好的效果。該項目發布包含有預訓練(Baichuan-13B-Base) 和對齊(Baichuan-13B-Chat) 兩個版本。 Baichuan2地址:https://github.com/baichuan-inc/Baichuan2 簡介:由百川智能推出的新一代開源大語言模型,採用2.6 萬億Tokens 的高質量語料訓練,在多個權威的中文、英文和多語言的通用、領域benchmark上取得同尺寸最佳的效果,發布包含有7B、13B的Base和經過PPO訓練的Chat版本,並提供了Chat版本的4bits量化。 XVERSE-7B地址:https://github.com/xverse-ai/XVERSE-7B 簡介:由深圳元象科技自主研發的支持多語言的大語言模型,支持8K 的上下文長度(Context Length),使用2.6 萬億token 的高質量、多樣化的數據對模型進行充分訓練,支持中、英、俄、西等40 多種語言。並包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系統上推理。 XVERSE-13B地址:https://github.com/xverse-ai/XVERSE-13B 簡介:由深圳元象科技自主研發的支持多語言的大語言模型,支持8K 的上下文長度(Context Length),使用3.2 萬億token 的高質量、多樣化的數據對模型進行充分訓練,支持中、英、俄、西等40 多種語言。包含長序列對話模型XVERSE-13B-256K ,該版本模型最大支持256K 的上下文窗口長度,約25w 字的輸入內容,可以協助進行文獻總結、報告分析等任務。並包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系統上推理。 XVERSE-65B地址:https://github.com/xverse-ai/XVERSE-65B 簡介:由深圳元象科技自主研發的支持多語言的大語言模型,支持16K 的上下文長度(Context Length),使用2.6 萬億token 的高質量、多樣化的數據對模型進行充分訓練,支持中、英、俄、西等40 多種語言。包含增量預訓練到3.2 萬億token 的XVERSE-65B-2 模型。並包含GGUF、GPTQ量化版本的模型,支持在llama.cpp、vLLM在MacOS/Linux/Windows系統上推理。 XVERSE-MoE-A4.2B地址:https://github.com/xverse-ai/XVERSE-MoE-A4.2B 簡介:由深圳元象科技自主研發的支持多語言的大語言模型(Large Language Model),使用混合專家模型(MoE,Mixture-of-experts)架構,模型的總參數規模為258 億,實際激活的參數量為42 億,支持8K 的上下文長度(Context Length),使用3.2 萬億token 的高質量、多樣化的數據對模型進行充分訓練,支持中、英、俄、西等40 多種語言。 Skywork地址:https://github.com/SkyworkAI/Skywork 簡介:該項目開源了天工系列模型,該系列模型在3.2TB高質量多語言和代碼數據上進行預訓練,開源了包括模型參數,訓練數據,評估數據,評估方法。具體包括Skywork-13B-Base模型、Skywork-13B-Chat模型、Skywork-13B-Math模型和Skywork-13B-MM模型,以及每個模型的量化版模型,以支持用戶在消費級顯卡進行部署和推理。 Yi地址:https://github.com/01-ai/Yi 簡介:該項目開源了Yi-6B和Yi-34B等模型,該系列模型最長可支持200K的超長上下文窗口版本,可以處理約40萬漢字超長文本輸入,理解超過1000頁的PDF文檔。 Chinese-LLaMA-Alpaca:地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca 簡介:中文LLaMA&Alpaca大語言模型+本地CPU/GPU部署,在原版LLaMA的基礎上擴充了中文詞表並使用了中文數據進行二次預訓練 Chinese-LLaMA-Alpaca-2:地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2 簡介:該項目將發布中文LLaMA-2 & Alpaca-2大語言模型,基於可商用的LLaMA-2進行二次開發。 Chinese-LlaMA2:地址:https://github.com/michael-wzhu/Chinese-LlaMA2 簡介:該項目基於可商用的LLaMA-2進行二次開發決定在次開展Llama 2的中文漢化工作,包括Chinese-LlaMA2: 對Llama 2進行中文預訓練;第一步:先在42G中文預料上進行訓練;後續將會加大訓練規模;Chinese-LlaMA2-chat: 對Chinese-LlaMA2進行指令微調和多輪對話微調,以適應各種應用場景和多輪對話交互。同時我們也考慮更為快速的中文適配方案:Chinese-LlaMA2-sft-v0: 採用現有的開源中文指令微調或者是對話數據,對LlaMA-2進行直接微調(將於近期開源)。 Llama2-Chinese:地址:https://github.com/FlagAlpha/Llama2-Chinese 簡介:該項目專注於Llama2模型在中文方面的優化和上層建設,基於大規模中文數據,從預訓練開始對Llama2模型進行中文能力的持續迭代升級。 OpenChineseLLaMA:地址:https://github.com/OpenLMLab/OpenChineseLLaMA 簡介:基於LLaMA-7B 經過中文數據集增量預訓練產生的中文大語言模型基座,對比原版LLaMA,該模型在中文理解能力和生成能力方面均獲得較大提升,在眾多下游任務中均取得了突出的成績。 BELLE:地址:https://github.com/LianjiaTech/BELLE 簡介:開源了基於BLOOMZ和LLaMA優化後的一系列模型,同時包括訓練數據、相關模型、訓練代碼、應用場景等,也會持續評估不同訓練數據、訓練算法等對模型表現的影響。 Panda:地址:https://github.com/dandelionsllm/pandallm 簡介:開源了基於LLaMA-7B, -13B, -33B, -65B 進行中文領域上的持續預訓練的語言模型, 使用了接近15M 條數據進行二次預訓練。 Robin (羅賓):地址:https://github.com/OptimalScale/LMFlow 簡介:Robin (羅賓)是香港科技大學LMFlow團隊開發的中英雙語大語言模型。僅使用180K條數據微調得到的Robin第二代模型,在Huggingface榜單上達到了第一名的成績。 LMFlow支持用戶快速訓練個性化模型,僅需單張3090和5個小時即可微調70億參數定制化模型。 Fengshenbang-LM:地址:https://github.com/IDEA-CCNL/Fengshenbang-LM 簡介:Fengshenbang-LM(封神榜大模型)是IDEA研究院認知計算與自然語言研究中心主導的大模型開源體系,該項目開源了姜子牙通用大模型V1,是基於LLaMa的130億參數的大規模預訓練模型,具備翻譯,編程,文本分類,信息抽取,摘要,文案生成,常識問答和數學計算等能力。除姜子牙系列模型之外,該項目還開源了太乙、二郎神系列等模型。 BiLLa:地址:https://github.com/Neutralzz/BiLLa 簡介:該項目開源了推理能力增強的中英雙語LLaMA模型。模型的主要特性有:較大提升LLaMA的中文理解能力,並儘可能減少對原始LLaMA英文能力的損傷;訓練過程增加較多的任務型數據,利用ChatGPT生成解析,強化模型理解任務求解邏輯;全量參數更新,追求更好的生成效果。 Moss:地址:https://github.com/OpenLMLab/MOSS 簡介:支持中英雙語和多種插件的開源對話語言模型,MOSS基座語言模型在約七千億中英文以及代碼單詞上預訓練得到,後續經過對話指令微調、插件增強學習和人類偏好訓練具備多輪對話能力及使用多種插件的能力。 Luotuo-Chinese-LLM:地址:https://github.com/LC1332/Luotuo-Chinese-LLM 簡介:囊括了一系列中文大語言模型開源項目,包含了一系列基於已有開源模型(ChatGLM, MOSS, LLaMA)進行二次微調的語言模型,指令微調數據集等。 Linly:地址:https://github.com/CVI-SZU/Linly 簡介:提供中文對話模型Linly-ChatFlow 、中文基礎模型Linly-Chinese-LLaMA 及其訓練數據。 中文基礎模型以LLaMA 為底座,利用中文和中英平行增量預訓練。項目匯總了目前公開的多語言指令數據,對中文模型進行了大規模指令跟隨訓練,實現了Linly-ChatFlow 對話模型。 Firefly:地址:https://github.com/yangjianxin1/Firefly 簡介:Firefly(流螢) 是一個開源的中文大語言模型項目,開源包括數據、微調代碼、多個基於Bloom、baichuan等微調好的模型等;支持全量參數指令微調、QLoRA低成本高效指令微調、LoRA指令微調;支持絕大部分主流的開源大模型,如百川baichuan、Ziya、Bloom、LLaMA等。持lora與base model進行權重合併,推理更便捷。 ChatYuan地址:https://github.com/clue-ai/ChatYuan 簡介:元語智能發布的一系列支持中英雙語的功能型對話語言大模型,在微調數據、人類反饋強化學習、思維鍊等方面進行了優化。 ChatRWKV:地址:https://github.com/BlinkDL/ChatRWKV 簡介:開源了一系列基於RWKV架構的Chat模型(包括英文和中文),發布了包括Raven,Novel-ChnEng,Novel-Ch與Novel-ChnEng-ChnPro等模型,可以直接閒聊及進行詩歌,小說等創作,包括7B和14B等規模的模型。 CPM-Bee地址:https://github.com/OpenBMB/CPM-Bee 簡介:一個完全開源、允許商用的百億參數中英文基座模型。它採用Transformer自回歸架構(auto-regressive),在超萬億(trillion)高質量語料上進行預訓練,擁有強大的基礎能力。開發者和研究者可以在CPM-Bee基座模型的基礎上在各類場景進行適配來以創建特定領域的應用模型。 TigerBot地址:https://github.com/TigerResearch/TigerBot 簡介:一個多語言多任務的大規模語言模型(LLM),開源了包括模型:TigerBot-7B, TigerBot-7B-base,TigerBot-180B,基本訓練和推理代碼,100G預訓練數據,涵蓋金融、法律、百科的領域數據以及API等。 Aquila地址:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila 簡介:由智源研究院發布,Aquila語言大模型在技術上繼承了GPT-3、LLaMA等的架構設計優點,替換了一批更高效的底層算子實現、重新設計實現了中英雙語的tokenizer ,升級了BMTrain並行訓練方法,是在中英文高質量語料基礎上從0開始訓練的,通過數據質量的控制、多種訓練的優化方法,實現在更小的數據集、更短的訓練時間,獲得比其它開源模型更優的性能。也是首個支持中英雙語知識、支持商用許可協議、符合國內數據合規需要的大規模開源語言模型。 Aquila2地址:https://github.com/FlagAI-Open/Aquila2 簡介:由智源研究院發布,Aquila2 系列,包括基礎語言模型Aquila2-7B,Aquila2-34B 和Aquila2-70B-Expr ,對話模型AquilaChat2-7B ,AquilaChat2-34B 和AquilaChat2-70B-Expr,長文本對話模型AquilaChat2-7B-16k 和AquilaChat2-34B-16。 Anima地址:https://github.com/lyogavin/Anima 簡介:由艾寫科技開發的一個開源的基於QLoRA的33B中文大語言模型,該模型基於QLoRA的Guanaco 33B模型使用Chinese-Vicuna項目開放的訓練數據集guanaco_belle_merge_v1.0進行finetune訓練了10000個step,基於Elo rating tournament評估效果較好。 KnowLM地址:https://github.com/zjunlp/KnowLM 簡介:KnowLM項目旨在發布開源大模型框架及相應模型權重以助力減輕知識謬誤問題,包括大模型的知識難更新及存在潛在的錯誤和偏見等。該項目一期發布了基於Llama的抽取大模型智析,使用中英文語料對LLaMA(13B)進行進一步全量預訓練,並基於知識圖譜轉換指令技術對知識抽取任務進行優化。 BayLing地址:https://github.com/ictnlp/BayLing 簡介:一個具有增強的跨語言對齊的通用大模型,由中國科學院計算技術研究所自然語言處理團隊開發。百聆(BayLing)以LLaMA為基座模型,探索了以交互式翻譯任務為核心進行指令微調的方法,旨在同時完成語言間對齊以及與人類意圖對齊,將LLaMA的生成能力和指令跟隨能力從英語遷移到其他語言(中文)。在多語言翻譯、交互翻譯、通用任務、標準化考試的測評中,百聆在中文/英語中均展現出更好的表現。百聆提供了在線的內測版demo,以供大家體驗。 YuLan-Chat地址:https://github.com/RUC-GSAI/YuLan-Chat 簡介:YuLan-Chat是中國人民大學GSAI研究人員開發的基於聊天的大語言模型。它是在LLaMA的基礎上微調開發的,具有高質量的英文和中文指令。 YuLan-Chat可以與用戶聊天,很好地遵循英文或中文指令,並且可以在量化後部署在GPU(A800-80G或RTX3090)上。 PolyLM地址:https://github.com/DAMO-NLP-MT/PolyLM 簡介:一個在6400億個詞的數據上從頭訓練的多語言語言模型,包括兩種模型大小(1.7B和13B)。 PolyLM覆蓋中、英、俄、西、法、葡、德、意、荷、波、阿、土、希伯來、日、韓、泰、越、印尼等語種,特別是對亞洲語種更友好。 huozi地址:https://github.com/HIT-SCIR/huozi 簡介:由哈工大自然語言處理研究所多位老師和學生參與開發的一個開源可商用的大規模預訓練語言模型。 該模型基於Bloom 結構的70 億參數模型,支持中英雙語,上下文窗口長度為2048,同時還開源了基於RLHF訓練的模型以及全人工標註的16.9K中文偏好數據集。 YaYi地址:https://github.com/wenge-research/YaYi 簡介:雅意大模型在百萬級人工構造的高質量領域數據上進行指令微調得到,訓練數據覆蓋媒體宣傳、輿情分析、公共安全、金融風控、城市治理等五大領域,上百種自然語言指令任務。雅意大模型從預訓練初始化權重到領域模型的迭代過程中,我們逐步增強了它的中文基礎能力和領域分析能力,並增加了多輪對話和部分插件能力。同時,經過數百名用戶內測過程中持續不斷的人工反饋優化,進一步提升了模型性能和安全性。已開源基於LLaMA 2 的中文優化模型版本,探索適用於中文多領域任務的最新實踐。 YAYI2地址:https://github.com/wenge-research/YAYI2 簡介:YAYI 2 是中科聞歌研發的新一代開源大語言模型,包括Base 和Chat 版本,參數規模為30B。 YAYI2-30B 是基於Transformer 的大語言模型,採用了超過2 萬億Tokens 的高質量、多語言語料進行預訓練。針對通用和特定領域的應用場景,我們採用了百萬級指令進行微調,同時藉助人類反饋強化學習方法,以更好地使模型與人類價值觀對齊。本次開源的模型為YAYI2-30B Base 模型。 Yuan-2.0地址:https://github.com/IEIT-Yuan/Yuan-2.0 簡介:該項目開源了由浪潮信息發布的新一代基礎語言大模型,具體開源了全部的3個模型源2.0-102B,源2.0-51B和源2.0-2B。並且提供了預訓練,微調,推理服務的相關腳本。源2.0是在源1.0的基礎上,利用更多樣的高質量預訓練數據和指令微調數據集,令模型在語義、數學、推理、代碼、知識等不同方面具備更強的理解能力。 Chinese-Mixtral-8x7B地址:https://github.com/HIT-SCIR/Chinese-Mixtral-8x7B 簡介:該項目基於Mixtral-8x7B稀疏混合專家模型進行了中文擴詞表增量預訓練,開源了Chinese-Mixtral-8x7B擴詞表模型以及訓練代碼。該模型的的中文編解碼效率較原模型顯著提高。同時通過在大規模開源語料上進行的增量預訓練,該模型具備了強大的中文生成和理解能力。 BlueLM地址:https://github.com/vivo-ai-lab/BlueLM 簡介:BlueLM 是由vivo AI 全球研究院自主研發的大規模預訓練語言模型,本次發布包含7B 基礎(base) 模型和7B 對話(chat) 模型,同時我們開源了支持32K 的長文本基礎(base ) 模型和對話(chat) 模型。 TuringMM地址:https://github.com/lightyear-turing/TuringMM-34B-Chat 簡介:TuringMM-34B-Chat是一款開源的中英文Chat模型,由北京光年無限科技有限公司基於Yi-34B開源模型、基於14w的精標教育數據進行sft微調以及15W對齊數據進行DPO偏好學習得到的一個微調模型。 Orion地址:https://github.com/OrionStarAI/Orion 簡介:Orion-14B-Base是一個具有140億參數的多語種大模型,該模型在一個包含2.5萬億token的多樣化數據集上進行了訓練,涵蓋了中文、英語、日語、韓語等多種語言。 OrionStar-Yi-34B-Chat地址:https://github.com/OrionStarAI/OrionStar-Yi-34B-Chat 簡介:OrionStar-Yi-34B-Chat 是獵戶星空基於零一萬物開源的Yi-34B模型,使用15W+ 的高質量語料訓練而來微調大模型,旨在為大模型社區用戶提供卓越的交互體驗。 MiniCPM地址:https://github.com/OpenBMB/MiniCPM 簡介:MiniCPM 是面壁智能與清華大學自然語言處理實驗室共同開源的系列端側大模型,主體語言模型MiniCPM-2B 僅有24億(2.4B)的非詞嵌入參數量, 總計2.7B參數量。 Mengzi3地址:https://github.com/Langboat/Mengzi3 簡介:Mengzi3 8B/13B模型基於Llama架構,語料精選自網頁、百科、社交、媒體、新聞,以及高質量的開源數據集。通過在萬億tokens上進行多語言語料的繼續訓練,模型的中文能力突出並且兼顧多語言能力。
1.2 多模態LLM模型
2. 應用
2.1 垂直領域微調
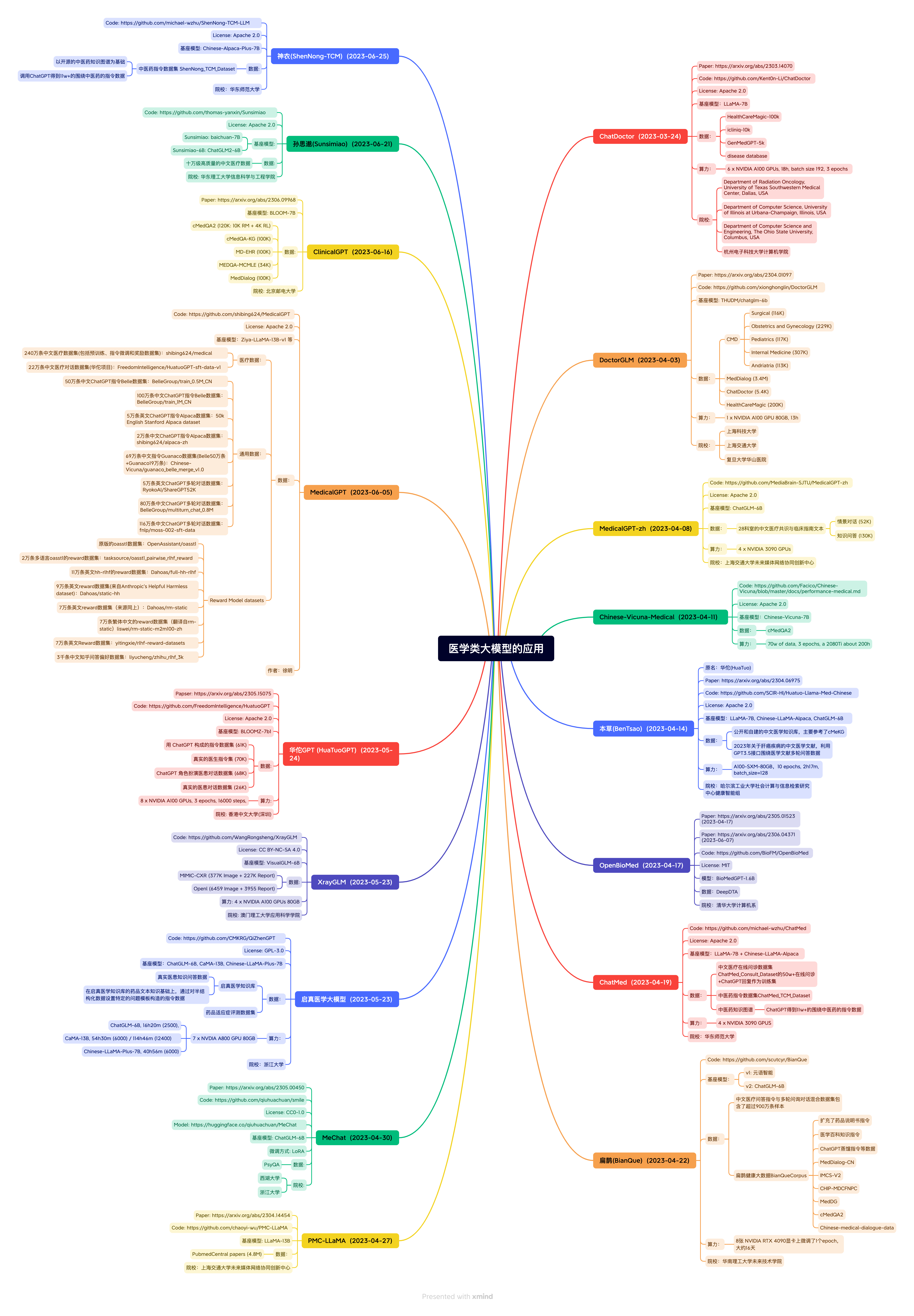
醫療
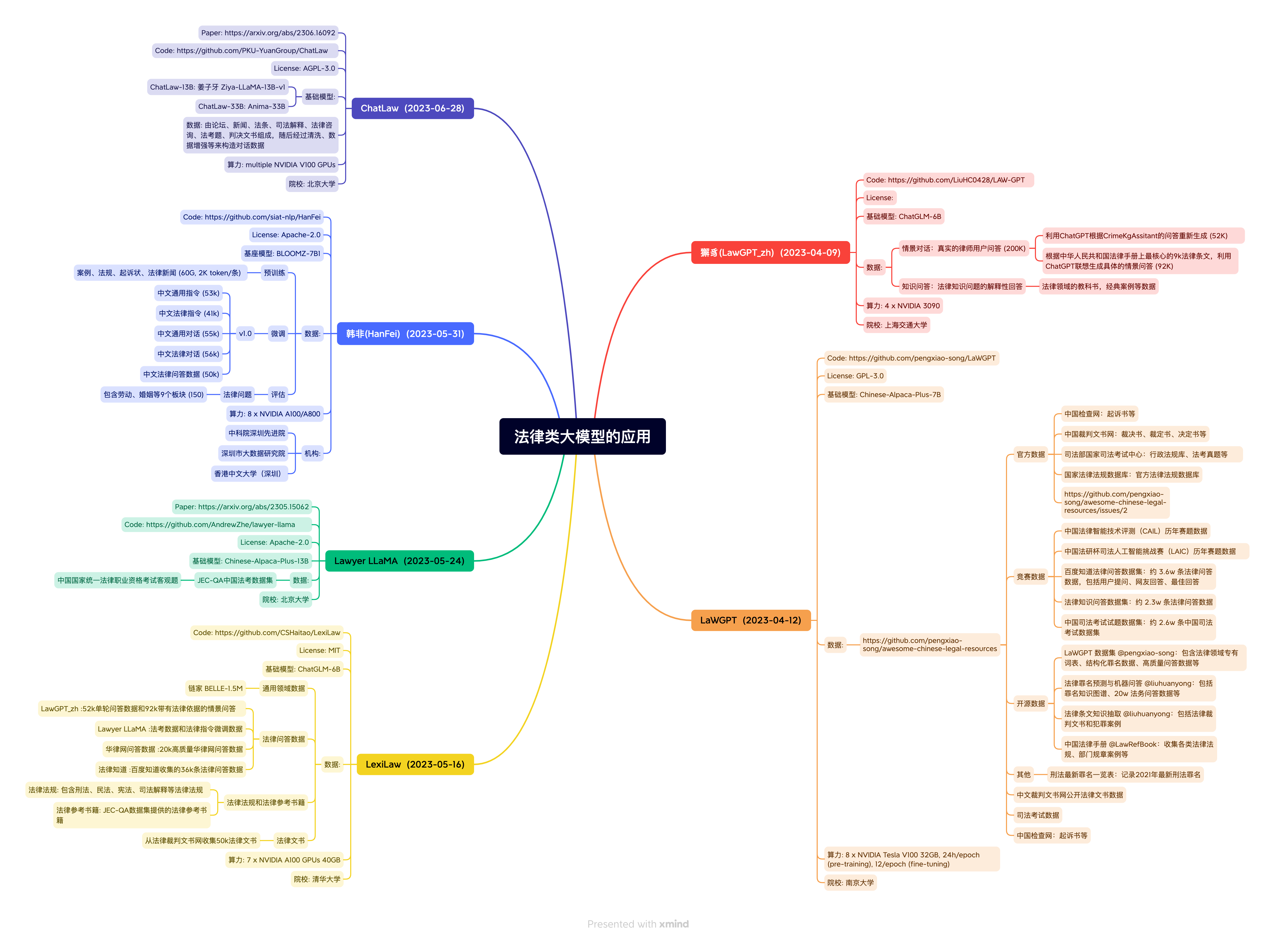
法律
金融
教育 桃李(Taoli):
地址:https://github.com/blcuicall/taoli 簡介:一個在國際中文教育領域數據上進行了額外訓練的模型。項目基於目前國際中文教育領域流通的500餘冊國際中文教育教材與教輔書、漢語水平考試試題以及漢語學習者詞典等,構建了國際中文教育資源庫,構造了共計88000 條的高質量國際中文教育問答數據集,並利用收集到的數據對模型進行指令微調,讓模型習得將知識應用到具體場景中的能力。 EduChat:
地址:https://github.com/icalk-nlp/EduChat 簡介:該項目華東師範大學計算機科學與技術學院的EduNLP團隊研發,主要研究以預訓練大模型為基底的教育對話大模型相關技術,融合多樣化的教育垂直領域數據,輔以指令微調、價值觀對齊等方法,提供教育場景下自動出題、作業批改、情感支持、課程輔導、高考諮詢等豐富功能,服務於廣大老師、學生和家長群體,助力實現因材施教、公平公正、富有溫度的智能教育。 chatglm-maths:
地址:https://github.com/yongzhuo/chatglm-maths 簡介:基於chatglm-6b微調/LORA/PPO/推理的數學題解題大模型, 樣本為自動生成的整數/小數加減乘除運算, 可gpu/cpu部署,開源了訓練數據集等。 MathGLM:
地址:https://github.com/THUDM/MathGLM 簡介:該項目由THUDM研發,開源了多個能進行20億參數可以進行準確多位算術運算的語言模型,同時開源了可用於算術運算微調的數據集。 QiaoBan:
地址:https://github.com/HIT-SCIR-SC/QiaoBan 簡介:該項目旨在構建一個面向兒童情感陪伴的大模型,這個倉庫包含:用於指令微調的對話數據/data,巧板的訓練代碼,訓練配置文件,使用巧板進行對話的示例代碼(TODO ,checkpoint將發布至huggingface)。
科技 天文大語言模型StarGLM:
地址:https://github.com/Yu-Yang-Li/StarGLM 簡介:基於ChatGLM訓練了天文大語言模型,以期緩解大語言模型在部分天文通用知識和前沿變星領域的幻覺現象,為接下來可處理天文多模態任務、部署於望遠鏡陣列的觀測Agent——司天大腦(數據智能處理)打下基礎。 TransGPT·致遠:
地址:https://github.com/DUOMO/TransGPT 簡介:開源交通大模型,主要致力於在真實交通行業中發揮實際價值。它能夠實現交通情況預測、智能諮詢助手、公共交通服務、交通規劃設計、交通安全教育、協助管理、交通事故報告和分析、自動駕駛輔助系統等功能。 Mozi:
地址:https://github.com/gmftbyGMFTBY/science-llm 簡介:該項目開源了基於LLaMA和Baichuan的科技論文大模型,可以用於科技文獻的問答和情感支持。
電商 EcomGPT地址:https://github.com/Alibaba-NLP/EcomGPT 簡介:一個由阿里發布的面向電商領域的語言模型,該模型基於BLOOMZ在電商指令微調數據集上微調得到,人工評估在12個電商評測數據集上超過ChatGPT。
網絡安全 SecGPT地址:https://github.com/Clouditera/secgpt 簡介:開項目開源了網絡安全大模型,該模型基於Baichuan-13B採用Lora做預訓練和SFT訓練,此外該項目還開源了相關預訓練和指令微調數據集等資源。
農業 后稷(AgriMa):地址:https://github.com/zhiweihu1103/AgriMa 簡介:首個中文開源農業大模型是由山西大學、山西農業大學與The Fin AI聯合研發,以Baichuan為底座,基於海量有監督農業領域相關數據微調,具備廣泛的農業知識和智能分析能力,該模型旨在為農業領域提供全面而高效的信息處理和決策支持。 稷豐(AgriAgent):地址:https://github.com/zhiweihu1103/AgriAgent 簡介:首個開源中文農業多模態大模型是由山西農業大學研發,以MiniCPM-Llama3-V 2.5為底座,能夠從圖像、文本、氣象數據等多源信息中提取有用信息,為農業生產提供全面、精準的智能化解決方案。我們致力於將稷豐應用於作物健康監測、病蟲害識別、土壤肥力分析、農田管理優化等多個方面,幫助農民提升生產效率,減少資源浪費,促進農業的可持續發展。
2.2 LangChain應用
2.3 其他應用 wenda:
地址:https://github.com/wenda-LLM/wenda 簡介:一個LLM調用平台。為小模型外掛知識庫查找和設計自動執行動作,實現不亞於於大模型的生成能力。 JittorLLMs:
地址:https://github.com/Jittor/JittorLLMs 簡介:計圖大模型推理庫:筆記本沒有顯卡也能跑大模型,具有成本低,支持廣,可移植,速度快等優勢。 LMFlow:
地址:https://github.com/OptimalScale/LMFlow 簡介:LMFlow是香港科技大學LMFlow團隊開發的大模型微調工具箱。 LMFlow工具箱具有可擴展性強、高效、方便的特性。 LMFlow僅使用180K條數據微調,即可得到在Huggingface榜單第一名的Robin模型。 LMFlow支持用戶快速訓練個性化模型,僅需單張3090和5個小時即可微調70億參數定制化模型。 fastllm:
地址:https://github.com/ztxz16/fastllm 簡介:純c++的全平台llm加速庫,chatglm-6B級模型單卡可達10000+token / s,支持moss, chatglm, baichuan模型,手機端流暢運行。 WebCPM
地址:https://github.com/thunlp/WebCPM 簡介:一個支持可交互網頁搜索的中文大模型。 GPT Academic:
地址:https://github.com/binary-husky/gpt_academic 簡介:為GPT/GLM提供圖形交互界面,特別優化論文閱讀潤色體驗,支持並行問詢多種LLM模型,支持清華chatglm等本地模型。兼容復旦MOSS, llama, rwkv, 盤古等。 ChatALL:
地址:https://github.com/sunner/ChatALL 簡介:ChatALL(中文名:齊叨)可以把一條指令同時發給多個AI,可以幫助用戶發現最好的回答。 CreativeChatGLM:
地址:https://github.com/ypwhs/CreativeChatGLM 簡介:可以使用修訂和續寫的功能來生成創意內容,可以使用“續寫”按鈕幫ChatGLM 想一個開頭,並讓它繼續生成更多的內容,你可以使用“修訂”按鈕修改最後一句ChatGLM 的回覆. docker-llama2-chat:
地址:https://github.com/soulteary/docker-llama2-chat 簡介:開源了一個只需要三步就可以上手LLaMA2的快速部署方案。 ChatGLM2-Voice-Cloning:
地址:https://github.com/KevinWang676/ChatGLM2-Voice-Cloning 簡介:實現了一個可以和喜歡的角色沉浸式對話的應用,主要採用ChatGLM2+聲音克隆+視頻對話的技術。 Flappy
地址:https://github.com/pleisto/flappy 簡介:一個產品級面向所有程序員的LLM SDK, LazyLLM
地址:https://github.com/LazyAGI/LazyLLM 簡介:LazyLLM是一款低代碼構建多Agent大模型應用的開發工具,協助開發者用極低的成本構建複雜的AI應用,並可以持續的迭代優化效果。 LazyLLM提供了更為靈活的應用功能定制方式,並實現了一套輕量級網管機制來支持一鍵部署多Agent應用,支持流式輸出,兼容多個Iaas平台,且支持對應用中的模型進行持續微調。 MemFree
地址:https://github.com/memfreeme/memfree 簡介:MemFree 是一個開源的Hybrid AI 搜索引擎,可以同時對您的個人知識庫(如書籤、筆記、文檔等)和互聯網進行搜索, 為你提供最佳答案。 MemFree 支持自託管的極速無服務器向量數據庫,支持自託管的極速Local Embedding and Rerank Service,支持一鍵部署。
3. 數據集
預訓練數據集 MNBVC
地址:https://github.com/esbatmop/MNBVC 數據集說明:超大規模中文語料集,不但包括主流文化,也包括各個小眾文化甚至火星文的數據。 MNBVC數據集包括新聞、作文、小說、書籍、雜誌、論文、台詞、帖子、wiki、古詩、歌詞、商品介紹、笑話、糗事、聊天記錄等一切形式的純文本中文數據。數據均來源於互聯網收集,且在持續更新中。 WuDaoCorporaText
地址:https://data.baai.ac.cn/details/WuDaoCorporaText 數據集說明:WuDaoCorpora是北京智源人工智能研究院(智源研究院)構建的大規模、高質量數據集,用於支撐大模型訓練研究。目前由文本、對話、圖文對、視頻文本對四部分組成,分別緻力於構建微型語言世界、提煉對話核心規律、打破圖文模態壁壘、建立視頻文字關聯,為大模型訓練提供堅實的數據支撐。 CLUECorpus2020
地址:https://github.com/CLUEbenchmark/CLUECorpus2020 數據集說明:通過對Common Crawl的中文部分進行語料清洗,最終得到100GB的高質量中文預訓練語料,可直接用於預訓練、語言模型或語言生成任務以及專用於簡體中文NLP任務的小詞表。 WanJuan-1.0
地址:https://opendatalab.org.cn/WanJuan1.0 數據集說明:書生·萬卷1.0為書生·萬卷多模態語料庫的首個開源版本,包含文本數據集、圖文數據集、視頻數據集三部分,數據總量超過2TB。 目前,書生·萬卷1.0已被應用於書生·多模態、書生·浦語的訓練。通過對高質量語料的“消化”,書生系列模型在語義理解、知識問答、視覺理解、視覺問答等各類生成式任務表現出的優異性能。 seq-monkey-data
SFT數據集 RefGPT:基於RefGPT生成大量真實和定制的對話數據集
地址:https://github.com/DA-southampton/RedGPT 數據集說明:包括RefGPT-Fact和RefGPT-Code兩部分,其中RefGPT-Fact給出了5萬中文的關於事實性知識的多輪對話,RefGPT-Code給出了3.9萬中文編程相關的多輪對話數據。 COIG
地址:https://huggingface.co/datasets/BAAI/COIG 數據集說明:維護了一套無害、有用且多樣化的中文指令語料庫,包括一個人工驗證翻譯的通用指令語料庫、一個人工標註的考試指令語料庫、一個人類價值對齊指令語料庫、一個多輪反事實修正聊天語料庫和一個leetcode 指令語料庫。 generated_chat_0.4M:
地址:https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M 數據集說明:包含約40萬條由BELLE項目生成的個性化角色對話數據,包含角色介紹。但此數據集是由ChatGPT產生的,未經過嚴格校驗,題目或解題過程可能包含錯誤。 alpaca_chinese_dataset:
地址:https://github.com/hikariming/alpaca_chinese_dataset 數據集說明:根據斯坦福開源的alpaca數據集進行中文翻譯,並再製造一些對話數據 Alpaca-CoT:
地址:https://github.com/PhoebusSi/Alpaca-CoT 數據集說明:統一了豐富的IFT數據(如CoT數據,目前仍不斷擴充)、多種訓練效率方法(如lora,p-tuning)以及多種LLMs,三個層面上的接口,打造方便研究人員上手的LLM-IFT研究平台。 pCLUE:
地址:https://github.com/CLUEbenchmark/pCLUE 數據集說明:基於提示的大規模預訓練數據集,用於多任務學習和零樣本學習。包括120萬訓練數據,73個Prompt,9個任務。 firefly-train-1.1M:
地址:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M 數據集說明:23個常見的中文數據集,對於每個任務,由人工書寫若干種指令模板,保證數據的高質量與豐富度,數據量為115萬 BELLE-data-1.5M:
地址:https://github.com/LianjiaTech/BELLE/tree/main/data/1.5M 數據集說明:通過self-instruct生成,使用了中文種子任務,以及openai的text-davinci-003接口,涉及175個種子任務 Chinese Scientific Literature Dataset:
地址:https://github.com/ydli-ai/csl 數據集說明:中文科學文獻數據集(CSL),包含396,209 篇中文核心期刊論文元信息(標題、摘要、關鍵詞、學科、門類)以及簡單的prompt Chinese medical dialogue data:
地址:https://github.com/Toyhom/Chinese-medical-dialogue-data 數據集說明:中文醫療對話數據集,包括:<Andriatria_男科> 94596個問答對<IM_內科> 220606個問答對<OAGD_婦產科> 183751個問答對<Oncology_腫瘤科> 75553個問答對<Pediatric_兒科> 101602個問答對<Surgical_外科> 115991個問答對總計792099個問答對。 Huatuo-26M:
地址:https://github.com/FreedomIntelligence/Huatuo-26M 數據集說明:Huatuo-26M 是一個中文醫療問答數據集,此數據集包含了超過2600萬個高質量的醫療問答對,涵蓋了各種疾病、症狀、治療方式、藥品信息等多個方面。 Huatuo-26M 是研究人員、開發者和企業為了提高醫療領域的人工智能應用,如聊天機器人、智能診斷系統等需要的重要資源。 Alpaca-GPT-4:
地址:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM 數據集說明:Alpaca-GPT-4 是一個使用self-instruct 技術,基於175 條中文種子任務和GPT-4 接口生成的50K 的指令微調數據集。 InstructionWild
地址:https://github.com/XueFuzhao/InstructionWild 數據集說明:InstructionWild 是一個從網絡上收集自然指令並過濾之後使用自然指令結合ChatGPT 接口生成指令微調數據集的項目。主要的指令來源:Twitter、CookUp.AI、Github 和Discard。 ShareChat
地址:https://paratranz.cn/projects/6725 數據集說明:一個倡議大家一起翻譯高質量ShareGPT 數據的項目。 項目介紹:清洗/構造/翻譯中文的ChatGPT數據,推進國內AI的發展,人人可煉優質中文Chat 模型。本數據集為ChatGPT約九萬個對話數據,由ShareGPT API獲得(英文68000,中文11000條,其他各國語言)。項目所有數據最終將以CC0 協議併入Multilingual Share GPT 語料庫。 Guanaco
地址:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset 數據集說明:一個使用Self-Instruct 的主要包含中日英德的多語言指令微調數據集。 chatgpt-corpus
地址:https://github.com/PlexPt/chatgpt-corpus 數據集說明:開源了由ChatGPT3.5 生成的300萬自問自答數據,包括多個領域,可用於用於訓練大模型。 SmileConv
地址:https://github.com/qiuhuachuan/smile 數據集說明:數據集通過ChatGPT改寫真實的心理互助QA為多輪的心理健康支持多輪對話(single-turn to multi-turn inclusive language expansion via ChatGPT),該數據集含有56k個多輪對話,其對話主題、詞彙和篇章語義更加豐富多樣,更加符合在長程多輪對話的應用場景。
偏好數據集
4. LLM訓練微調框架
5. LLM推理部署框架
6. LLM評測 FlagEval (天秤)大模型評測體系及開放平台
地址:https://github.com/FlagOpen/FlagEval 簡介:旨在建立科學、公正、開放的評測基準、方法、工具集,協助研究人員全方位評估基礎模型及訓練算法的性能,同時探索利用AI方法實現對主觀評測的輔助,大幅提升評測的效率和客觀性。 FlagEval (天秤)創新構建了“能力-任務-指標”三維評測框架,細粒度刻畫基礎模型的認知能力邊界,可視化呈現評測結果。 C-Eval: 構造中文大模型的知識評估基準:
地址:https://github.com/SJTU-LIT/ceval 簡介:構造了一個覆蓋人文,社科,理工,其他專業四個大方向,52 個學科(微積分,線代…),從中學到大學研究生以及職業考試,一共13948 道題目的中文知識和推理型測試集。此外還給出了當前主流中文LLM的評測結果。 OpenCompass:
地址:https://github.com/InternLM/opencompass 簡介:由上海AI實驗室發布的面向大模型評測的一站式平台。主要特點包括:開源可複現;全面的能力維度:五大維度設計,提供50+ 個數據集約30 萬題的的模型評測方案;豐富的模型支持:已支持20+ HuggingFace 及API 模型;分佈式高效評測:一行命令實現任務分割和分佈式評測,數小時即可完成千億模型全量評測;多樣化評測範式:支持零樣本、小樣本及思維鏈評測,結合標準型或對話型提示詞模板;靈活化拓展。 SuperCLUElyb: SuperCLUE瑯琊榜
地址:https://github.com/CLUEbenchmark/SuperCLUElyb 簡介:中文通用大模型匿名對戰評價基準,這是一個中文通用大模型對戰評價基準,它以眾包的方式提供匿名、隨機的對戰。他們發布了初步的結果和基於Elo評級系統的排行榜。 GAOKAO-Bench:
地址:https://github.com/OpenLMLab/GAOKAO-Bench 簡介:GAOKAO-bench是一個以中國高考題目為數據集,測評大模型語言理解能力、邏輯推理能力的測評框架,收集了2010-2022年全國高考卷的題目,其中包括1781道客觀題和1030道主觀題,構建起GAOKAO-bench的數據部分。 AGIEval:
地址:https://github.com/ruixiangcui/AGIEval 簡介:由微軟發布的一項新型基準測試,這項基準選取20種面向普通人類考生的官方、公開、高標準往常和資格考試,包括普通大學入學考試(中國高考和美國SAT 考試)、法學入學考試、數學競賽、律師資格考試、國家公務員考試等等。 Xiezhi:
地址:https://github.com/mikegu721/xiezhibenchmark 簡介:由複旦大學發布的一個綜合的、多學科的、能夠自動更新的領域知識評估Benchmark,包含了哲學、經濟學、法學、教育學、文學、歷史學、自然科學、工學、農學、醫學、軍事學、管理學、藝術學這13個學科門類,24萬道學科題目,516個具體學科,249587道題目。 Open LLM Leaderboard:
地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 簡介:由HuggingFace組織的一個LLM評測榜單,目前已評估了較多主流的開源LLM模型。評估主要包括AI2 Reasoning Challenge, HellaSwag, MMLU, TruthfulQA四個數據集上的表現,主要以英文為主。 CMMLU:
地址:https://github.com/haonan-li/CMMLU 簡介:CMMLU是一個綜合性的中文評估基準,專門用於評估語言模型在中文語境下的知識和推理能力。 CMMLU涵蓋了從基礎學科到高級專業水平的67個主題。它包括:需要計算和推理的自然科學,需要知識的人文科學和社會科學,以及需要生活常識的中國駕駛規則等。此外,CMMLU中的許多任務具有中國特定的答案,可能在其他地區或語言中並不普遍適用。因此是一個完全中國化的中文測試基準。 MMCU:
地址:https://github.com/Felixgithub2017/MMCU 簡介:該項目提供對中文大模型語義理解能力的測試,評測方式、評測數據集、評測記錄都公開,確保可以復現。該項目旨在幫助各位研究者們評測自己的模型性能,並驗證訓練策略是否有效。 chinese-llm-benchmark:
地址:https://github.com/jeinlee1991/chinese-llm-benchmark 簡介:中文大模型能力評測榜單:覆蓋百度文心一言、chatgpt、阿里通義千問、訊飛星火、belle / chatglm6b 等開源大模型,多維度能力評測。不僅提供能力評分排行榜,也提供所有模型的原始輸出結果! Safety-Prompts:
地址:https://github.com/thu-coai/Safety-Prompts 簡介:由清華大學提出的一個關於LLM安全評測benchmark,包括安全評測平台等,用於評測和提升大模型的安全性,囊括了多種典型的安全場景和指令攻擊的prompt。 PromptCBLUE: 中文醫療場景的LLM評測基準
地址:https://github.com/michael-wzhu/PromptCBLUE 簡介:為推動LLM在醫療領域的發展和落地,由華東師範大學聯合阿里巴巴天池平台,復旦大學附屬華山醫院,東北大學,哈爾濱工業大學(深圳),鵬城實驗室與同濟大學推出PromptCBLUE評測基準, 將16種不同的醫療場景NLP任務全部轉化為基於提示的語言生成任務,形成首個中文醫療場景的LLM評測基準。 HalluQA: 中文幻覺評估基準
地址:https://github.com/xiami2019/HalluQA 簡介:該項目提出了一個名為HalluQA的基準測試,用於衡量中文大型語言模型中的幻覺現象。 HalluQA包含450個精心設計的對抗性問題,涵蓋多個領域,並考慮了中國歷史文化、風俗和社會現象。在構建HalluQA時,考慮了兩種類型的幻覺:模仿性虛假和事實錯誤,並基於GLM-130B和ChatGPT構建對抗性樣本。為了評估,設計了一種使用GPT-4進行自動評估的方法,判斷模型輸出是否是幻覺。
7. LLM教程
LLM基礎知識 HuggingLLM:
地址:https://github.com/datawhalechina/hugging-llm 簡介:介紹ChatGPT 原理、使用和應用,降低使用門檻,讓更多感興趣的非NLP或算法專業人士能夠無障礙使用LLM創造價值。 LLMsPracticalGuide:
地址:https://github.com/Mooler0410/LLMsPracticalGuide 簡介:該項目提供了關於LLM的一系列指南與資源精選列表,包括LLM發展歷程、原理、示例、論文等。
提示工程教程
LLM應用教程
LLM實戰教程 LLMs九層妖塔:
地址:https://github.com/km1994/LLMsNineStoryDemonTower 簡介:ChatGLM、Chinese-LLaMA-Alpaca、MiniGPT-4、FastChat、LLaMA、gpt4all等實戰與經驗。 llm-action:
地址:https://github.com/liguodongiot/llm-action 簡介:該項目提供了一系列LLM實戰的教程和代碼,包括LLM的訓練、推理、微調以及LLM生態相關的一些技術文章等。 llm大模型訓練專欄:
地址:https://www.zhihu.com/column/c_1252604770952642560 簡介:該項目提供了一系列LLM前言理論和實戰實驗,包括論文解讀與洞察分析。 書生·浦語大模型實戰營
地址:https://github.com/InternLM/tutorial 簡介:該課程由上海人工智能實驗室重磅推出。課程包括大模型微調、部署與評測全鏈路,目的是為廣大開發者搭建大模型學習和實踐開發的平台。
8. 相關倉庫 FindTheChatGPTer:
地址:https://github.com/chenking2020/FindTheChatGPTer 簡介:ChatGPT爆火,開啟了通往AGI的關鍵一步,本項目旨在匯總那些ChatGPT的開源平替們,包括文本大模型、多模態大模型等,為大家提供一些便利。 LLM_reviewer:
地址:https://github.com/SpartanBin/LLM_reviewer 簡介:總結歸納近期井噴式發展的大語言模型,以開源、規模較小、可私有化部署、訓練成本較低的'小羊駝類'模型為主。 Awesome-AITools:
地址:https://github.com/ikaijua/Awesome-AITools 簡介:收藏整理了AI相關的實用工具、評測和相關文章。 open source ChatGPT and beyond:
地址:https://github.com/SunLemuria/open_source_chatgpt_list 簡介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more to go. Awesome Totally Open Chatgpt:
地址:https://github.com/nichtdax/awesome-totally-open-chatgpt 簡介:This repo record a list of totally open alternatives to ChatGPT. Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM 簡介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs. DecryptPrompt:
地址:https://github.com/DSXiangLi/DecryptPrompt 簡介:總結了Prompt&LLM論文,開源數據&模型,AIGC應用。 Awesome Pretrained Chinese NLP Models:
地址:https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models 簡介:收集了目前網上公開的一些高質量中文預訓練模型。 ChatPiXiu:
地址:https://github.com/catqaq/ChatPiXiu 簡介:該項目旨在打造全面且實用的ChatGPT模型庫和文檔庫。當前V1版本梳理了包括:相關資料調研+通用最小實現+領域/任務適配等。 LLM-Zoo:
地址:https://github.com/DAMO-NLP-SG/LLM-Zoo 簡介:該項目收集了包括開源和閉源的LLM模型,具體包括了發佈時間,模型大小,支持的語種,領域,訓練數據及相應論文/倉庫等。 LLMs-In-China:
地址:https://github.com/wgwang/LLMs-In-China 簡介:該項目旨在記錄中國大模型發展情況,同時持續深度分析開源開放的大模型以及數據集的情況。 BMList:
地址:https://github.com/OpenBMB/BMList 簡介:該項目收集了參數量超過10億的大模型,並梳理了各個大模型的適用模態、發布的機構、適合的語種,參數量和開源地址、API等信息。 awesome-free-chatgpt:
地址:https://github.com/LiLittleCat/awesome-free-chatgpt 簡介:該項目收集了免費的ChatGPT 鏡像網站列表,ChatGPT的替代方案,以及構建自己的ChatGPT的教程工具等。 Awesome-Domain-LLM:
地址:https://github.com/luban-agi/Awesome-Domain-LLM 簡介:該項目收集和梳理垂直領域的開源模型、數據集及評測基準。
Star History