使用神經網絡反轉矩陣。
反轉矩陣對神經網絡提出了獨特的挑戰,這主要是由於執行精確的算術操作(例如乘法和激活分裂)的固有局限性。傳統的密集網絡通常需要這些任務的幫助,因為它們沒有明確設計來處理矩陣反轉中涉及的複雜性。用簡單密集的神經網絡進行的實驗顯示出了很大的困難,從而實現了準確的矩陣反轉。儘管進行了各種優化架構和培訓過程的嘗試,但結果通常需要改進。但是,過渡到更複雜的體系結構(7層剩餘網絡(RESNET))會導致性能明顯改善。
Resnet架構以其通過殘留連接學習深度表示的能力而聞名,已證明有效地解決了矩陣反轉。有了數百萬個參數,該網絡可以在更簡單的模型無法使用的數據中捕獲複雜的模式。但是,這種複雜性是有效的:有效概括需要大量的培訓數據。
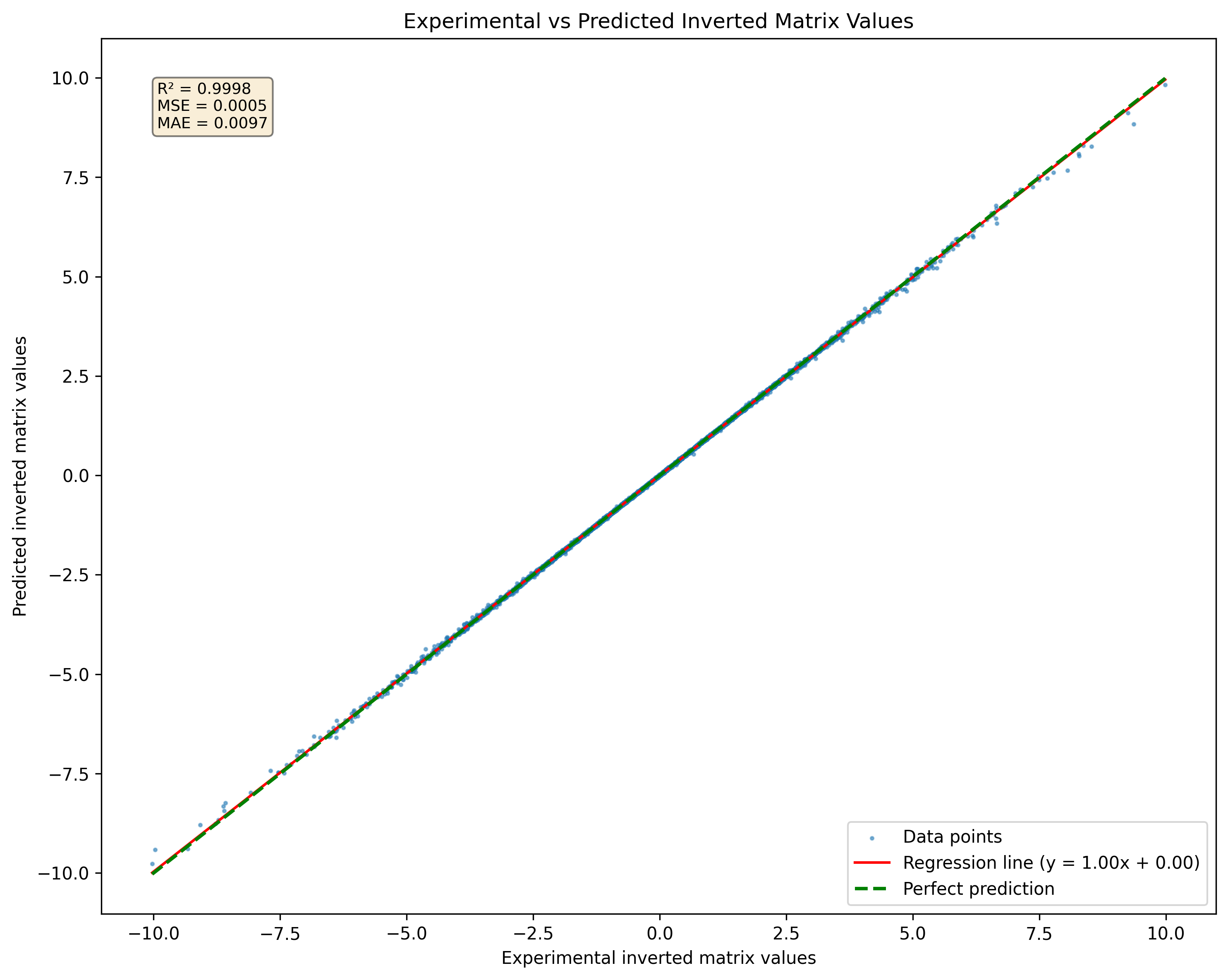 圖1:神經網絡的可視化預測數據集中從未見過的一組矩陣3x3的倒置矩陣
圖1:神經網絡的可視化預測數據集中從未見過的一組矩陣3x3的倒置矩陣
為了評估神經網絡在預測矩陣反轉時的性能,採用了特定的損失函數:
在此等式中:
目的是最大程度地減少身份矩陣與原始矩陣的乘積及其預測倒數之間的差異。該損失函數有效地衡量了預測的逆向準確性的距離。
另外,如果
此損失功能比傳統損失函數具有不同的優勢,例如平方誤差(MSE)或平均絕對誤差(MAE)。
反轉精度的直接測量矩陣反轉的主要目標是確保矩陣的乘積及其逆產生標識矩陣。損耗函數通過測量與身份矩陣的偏差直接捕獲了這一要求。相反,MSE和MAE專注於預測值與真實值之間的差異,而無需明確解決矩陣反轉的基本屬性。
通過使用評估乘積AA -1AA -1與II的損失函數來強調結構完整性,它強調維持所涉及的矩陣的結構完整性。這在保留線性關係至關重要的應用中尤其重要。傳統的損失功能(例如MSE和MAE)無法解釋這一結構性方面,可能導致解決方案最小化誤差但無法滿足矩陣反轉的數學要求。
適用於非單個矩陣的損失函數固有地假設倒置的矩陣是非單星的(即,可逆的)。在存在奇異矩陣的情況下,傳統的損失功能可能會產生誤導性結果,因為它們不能解釋不可能獲得有效的逆向。提出的損失函數突出了這種局限性,通過嘗試倒入奇異矩陣時會產生較大的錯誤。
當使用神經網絡進行基質反演時,一個重要的局限性是它們無法有效地處理奇異矩陣。單數矩陣沒有逆;因此,神經網絡試圖預測此類矩陣逆的任何嘗試都會產生不正確的結果。在實踐中,如果在訓練或推理過程中呈現一個單數矩陣,則網絡仍可能會輸出結果,但是此輸出將無效或有意義。該限制強調了確保訓練數據盡可能由非單明性矩陣組成的重要性。
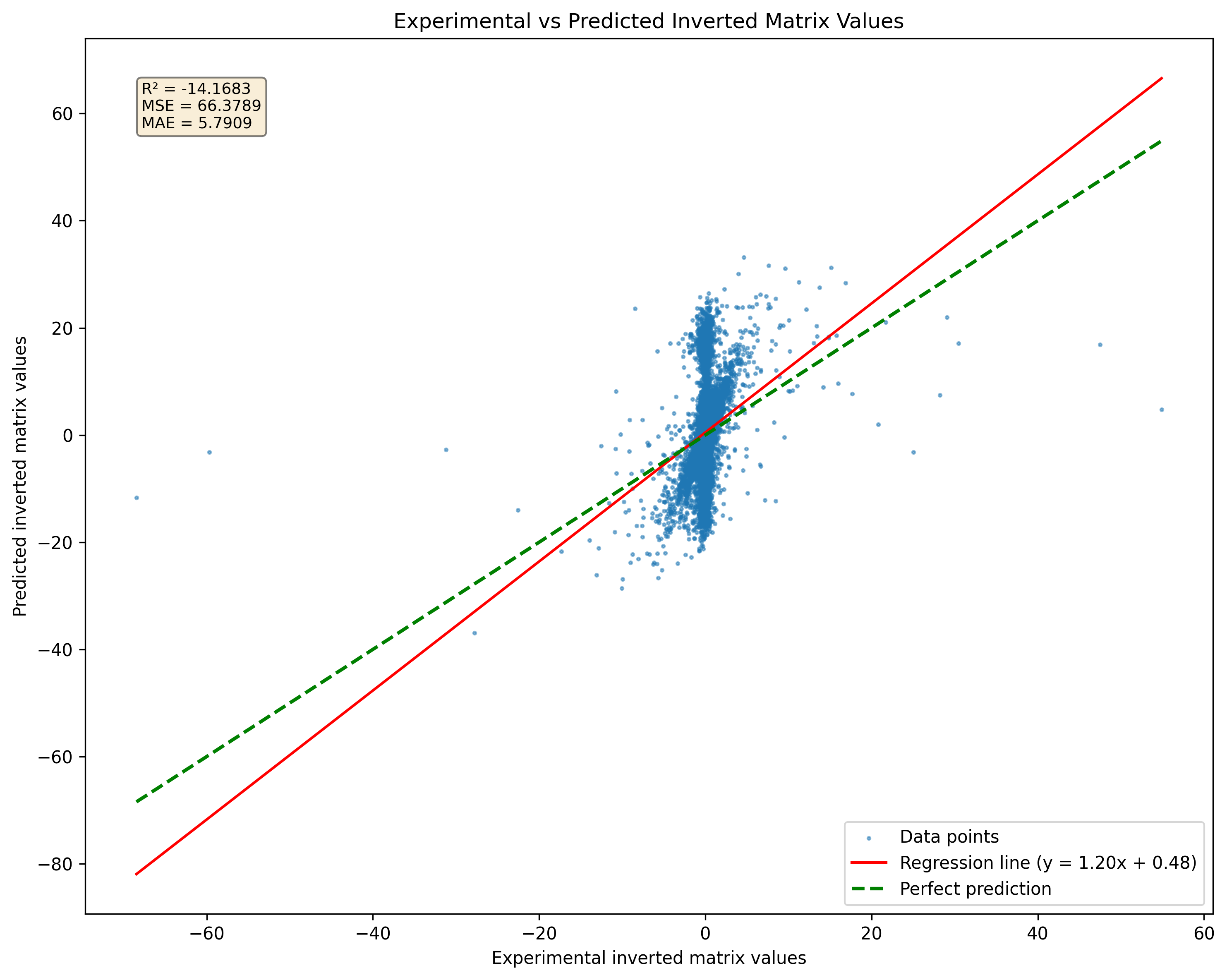 圖2:奇異矩陣與偽引導的模型預測的比較。請注意,無論基質奇異性如何,該模型都會產生結果。
圖2:奇異矩陣與偽引導的模型預測的比較。請注意,無論基質奇異性如何,該模型都會產生結果。
研究表明,重新網絡模型可以記住大量樣品而不會明顯喪失準確性。但是,將數據集大小提高到1000萬個樣本可能會導致嚴重的過度擬合。儘管數據量大量,但這種過度擬合仍會發生,這突顯了僅增加數據集大小並不能保證改進複雜模型的概括。為了應對這一挑戰,可以採用連續的數據生成策略。可以在創建的情況下即時生成樣品並將其饋送到網絡中,而不是依靠靜態數據集。這種方法對於緩解過度擬合至關重要,不僅提供了各種培訓示例,而且還確保該模型暴露於不斷發展的數據集中。
總而言之,儘管由於算術操作的局限性,矩陣反轉對神經網絡固有的挑戰,但利用Resnet等高級體系結構可以產生更好的結果。但是,必須仔細考慮數據要求和過度適合風險。連續生成培訓樣本可以增強模型的學習過程並提高矩陣反轉任務中的性能。該版本在討論培訓矩陣反轉的神經網絡的挑戰和策略的同時保持了非個人化的語氣。
DeepMatrixInversion根據LGPLV3許可證分配
要了解更多詳細信息,請閱讀文件“許可”或轉到“ http://www.gnu.org/licenses/lgpl-3.0.html”
DeepMatrixInversion目前是Giuseppe Marco Randazzo的財產。
要安裝DeepMatrixInversion存儲庫,您可以在下面使用詩歌,PIP或PIPX之間進行選擇,這是兩種方法的說明。
git clone https://github.com/gmrandazzo/DeepMatrixInversion.git
cd DeepMatrixInversion
python3 -m venv .venv
. .venv/bin/activate
pip install poetry
poetry install
這將使用所有必要的軟件包來設置您的環境,以運行DeepMatrixInversion。
創建虛擬環境並使用PIP安裝Deppmatrixinversion
python3 -m venv .venv
. .venv/bin/activate
pip install git+https://github.com/gmrandazzo/DeepMatrixInversion.git
如果您希望使用PIPX,該PIPX允許您在隔離環境中安裝Python應用程序,請按照以下步驟進行操作:
python3 -m pip install --user pipx
apt-get install pipx
brew install pipx
sudo dnf install pipx
PIPX安裝git+https://github.com/gmrandazzo/deepmatrixinversion.git
要訓練可以執行矩陣倒置的模型,您將使用dmxtrain命令。此命令使您可以指定控制訓練過程的各種參數,例如矩陣的大小,值範圍和訓練持續時間。
dmxtrain --msize < matrix_size > --rmin < min_value > --rmax < max_value > --epochs < number_of_epochs > --batch_size < size_of_batches > --n_repeats < number_of_repeats > --mout < output_model_path > dmxtrain --msize --rmin -1 --rmax 1 --epochs 5000 --batch_size 1024 --n_repeats 3 --mout ./Model_3x3
--msize <matrix_size>: Specifies the size of the square matrices to be generated for training. For example, 3 for 3x3 matrices.
--rmin <min_value>: Sets the minimum value for the random elements in the matrices. For instance, -1 will allow negative values.
--rmax <max_value>: Sets the maximum value for the random elements in the matrices. For example, 1 will limit values to a maximum of 1.
--epochs <number_of_epochs>: Defines how many epochs (complete passes through the training dataset) to run during training. A higher number typically leads to better performance; in this case, 5000.
--batch_size <size_of_batches>: Determines how many samples are processed before the model is updated. A batch size of 1024 means that 1024 samples are used in each iteration.
--n_repeats <number_of_repeats>: Indicates how many times to repeat the training process with different random seeds or initializations. This can help ensure robustness; for instance, repeating 3 times.
--mout <output_model_path>: Specifies where to save the trained model. In this example, it saves to ./Model_3x3.
訓練模型後,您可以使用它在新輸入矩陣上執行矩陣反轉。推斷的命令是DMXINVERT,它採用輸入矩陣並輸出其逆。
警告:DMXINVERT可以將比用於通過Sherman-Morrison-Woodbury矩陣塊反轉公式訓練模型的矩陣更大。此功能僅適用於矩陣的塊大小可以除以模型訓練塊大小而無需提醒。該功能是高度實驗性的,可能需要修改。
dmxinvert --inputmx <input_matrix_file> --inverseout <output_csv_file> --model <model_path>
dmxinvert --inputmx input_matrix.csv --inverseout output_inverse.csv --model ./Model_3x3_*
--inputmx <input_matrix_file>: Specifies the path to the input matrix file that you want to invert. This file should contain a valid matrix format (e.g., CSV).
--inverseout <output_csv_file>: Indicates where to save the resulting inverted matrix. The output will be saved in CSV format.
--model <model_path>: Provides the path to the trained model that will be used for performing the inversion.
生成具有輸入矩陣的人工數據集,並倒出輸出倒置DMX DMXDATASETGENERATOR
dmxdatasetgenerator 3 10 -1 1 test_3x3_range_-1+1
這將生成10個尺寸3x3的矩陣,數字在-1至+1範圍內。
dmxdatasetgenerator [matrix size] [number of samples] [range min] [range max] [outname_prefix]
然後可以使用DMXDATASETVERIFY驗證數據集
dmxdatasetverify test_3x3_range_-1+1_matrices_3x3.mx test_3x3_range_-1+1_matrices_inverted_3x3.mx invertible
Dataset valid.
dmxdatasetverify [dataset matrix to invert] [dataset matrix inverted] [type: invertible or singular]
輸入矩陣文件的格式應如下:
0.24077047370124594,-0.5012474139608847,-0.5409542929032876
-0.6257864520097793,-0.030705148203584942,-0.13723920334288975
-0.48095686716222064,0.19220406568380666,-0.34750000491973854
END
0.4575368007107925,0.9627977617090073,-0.4115240560547333
0.5191433428806012,0.9391491187187144,-0.000952683255491138
-0.17757763984424968,-0.7696584771443977,-0.9619759413623306
END
-0.49823271153034154,0.31993947803488587,0.9380291202366384
0.443652116558352,0.16745965310481048,-0.267270356721347
0.7075720067281346,-0.3310912886946993,-0.12013367141105102
END
每個數字的塊代表一個單獨的矩陣,然後是指示該矩陣末端的末端標記。


