開發REST API使用SEQ2SEQ模型執行機器翻譯。模型部署是使用Google可以平台完成的。
項目是由以下方式創建的
該項目的數據可作為數據源上的文本文件獲得,其中每行在卡納達語中都有一個句子,並用太空定界符的英語翻譯。我們手動驗證隨機驗證,以確保每個示例都是有道理的。
首先,我們使用GRU RNN構建了通過注意機制來構建編碼器解碼器模型。培訓是使用Python腳本進行的
構建一個燒瓶應用程序,可以從地址上的本地計算機訪問http://127.0.0.1:5000/predict。
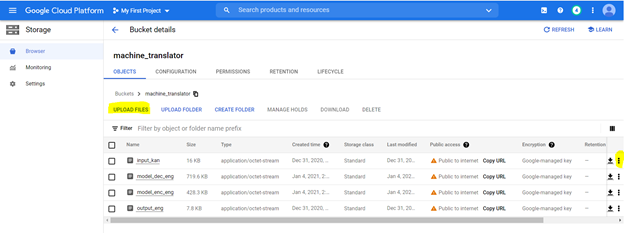
我們將使用腳本來訓練模型。訓練模型後,我們將將模型權重保存在.pt文件中,並存儲在Google Cloud Storage中。我們還通過將每個單詞索引到一個數字並醃製來構建詞彙詞典。這些醃製文件也存儲在存儲文件中。您可以在這些文件到位後在此處訪問它們,可以按照以下步驟進行部署
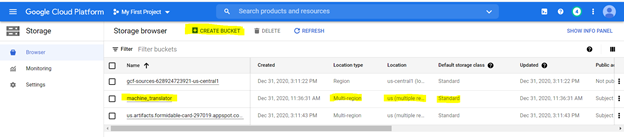
我們將將文件上傳到存儲存儲桶上。使用以下選項突出顯示以下規格創建一個存儲桶
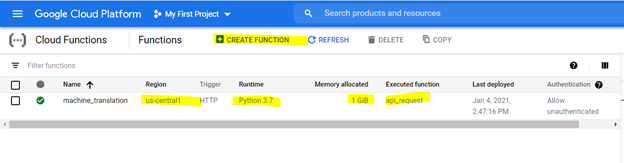
要創建雲功能,請在GCP平台上瀏覽它,並使用突出顯示的選項創建一個函數,
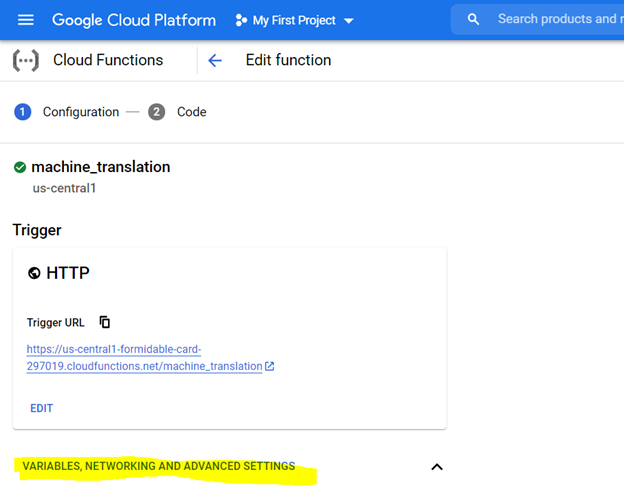
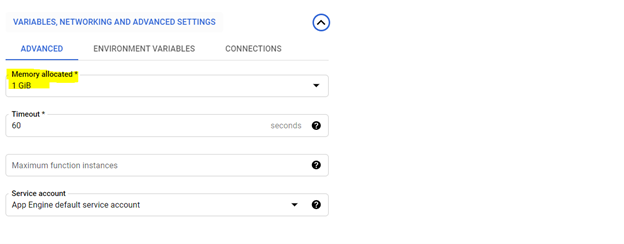
*建議分配1 GIB內存。設置後,單擊“下一步”,然後在雲功能控制台上部署代碼。
要部署代碼,請首先使用以下突出顯示的設置配置控制台,並使用要求文件(這等同於PIP install {library})準備環境,如下所述,
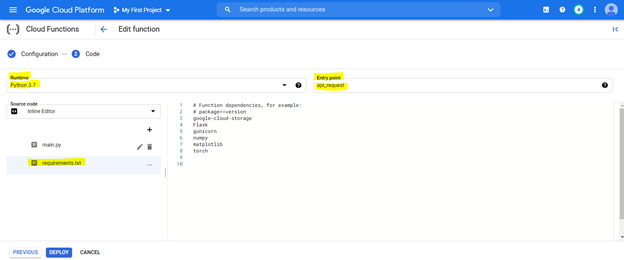
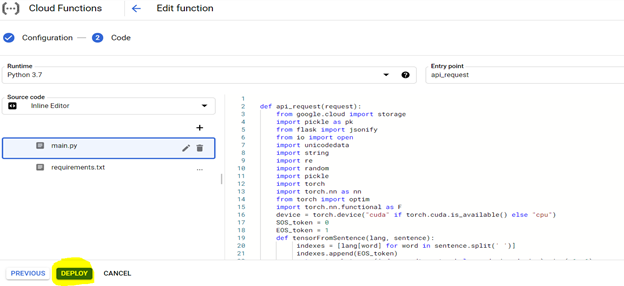

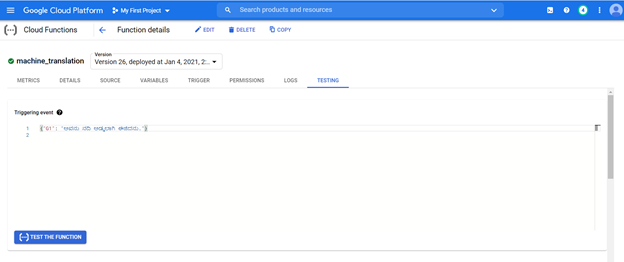

可以從任何系統的URL訪問部署的模型,以將Kannada句子轉換為英語。


