GroundingDINO
Grounding DINO SwinB

IDEA-CVR,思想研究
Shilong Liu,Zhaoyang Zeng,Tianhe Ren,Feng Li,Hao Zhang,Jie Yang,Chunyuan Li,Jianwei Yang,Hang Su,Jun Zhu,Jun Zhu,Lei Zhang ? 。
[ Paper ] [ Demo ] [ BibTex ]
Pytorch實施和驗證模型用於接地恐龍。有關詳細信息,請參閱紙接地Dino:將Dino與接地預培訓結婚以進行開放式對象檢測。
2023/07/18 :我們釋放語義SAM,這是一種通用圖像分割模型,可實現段並識別任何所需粒度的任何內容。代碼和檢查點可用!2023/06/17 :我們提供了一個示例,以評估Coco Zero-Shot性能的恐龍。2023/04/15 :對於那些對開放式識別感興趣的人,請參閱野外閱讀中的簡歷!2023/04/08 :我們發布演示,將接地恐龍與Gligen結合起來,以進行更可控制的圖像編輯。2023/04/08 :我們發布演示,將接地恐龍與穩定的擴散相結合以進行圖像編輯。2023/04/06 :我們通過將“地面”與任何名為“接地段”的部分結合在一起,建立了一個新的演示,目的是支持地面的細分。2023/03/28 :YouTube視頻有關接地恐龍和基本對象檢測及時工程。 [Skalskip]2023/03/28 :在擁抱臉部空間時添加一個演示!2023/03/27 :支持僅CPU-模式。現在,該模型可以在沒有GPU的機器上運行。2023/03/25 :COLAB可用地接地Dino的演示。 [Skalskip]2023/03/22 :現在可以使用代碼! 嫁給地面恐龍和格里根
嫁給地面恐龍和格里根(image, text)對作為輸入。900 (默認情況下)對象框。每個框在所有輸入單詞上都有相似性分數。 (如下圖所示。)box_threshold的框。text_threshold 。dogs two dogs with a stick. ,您可以選擇具有最高文本dogs的盒子作為最終輸出。.用於接地恐龍。 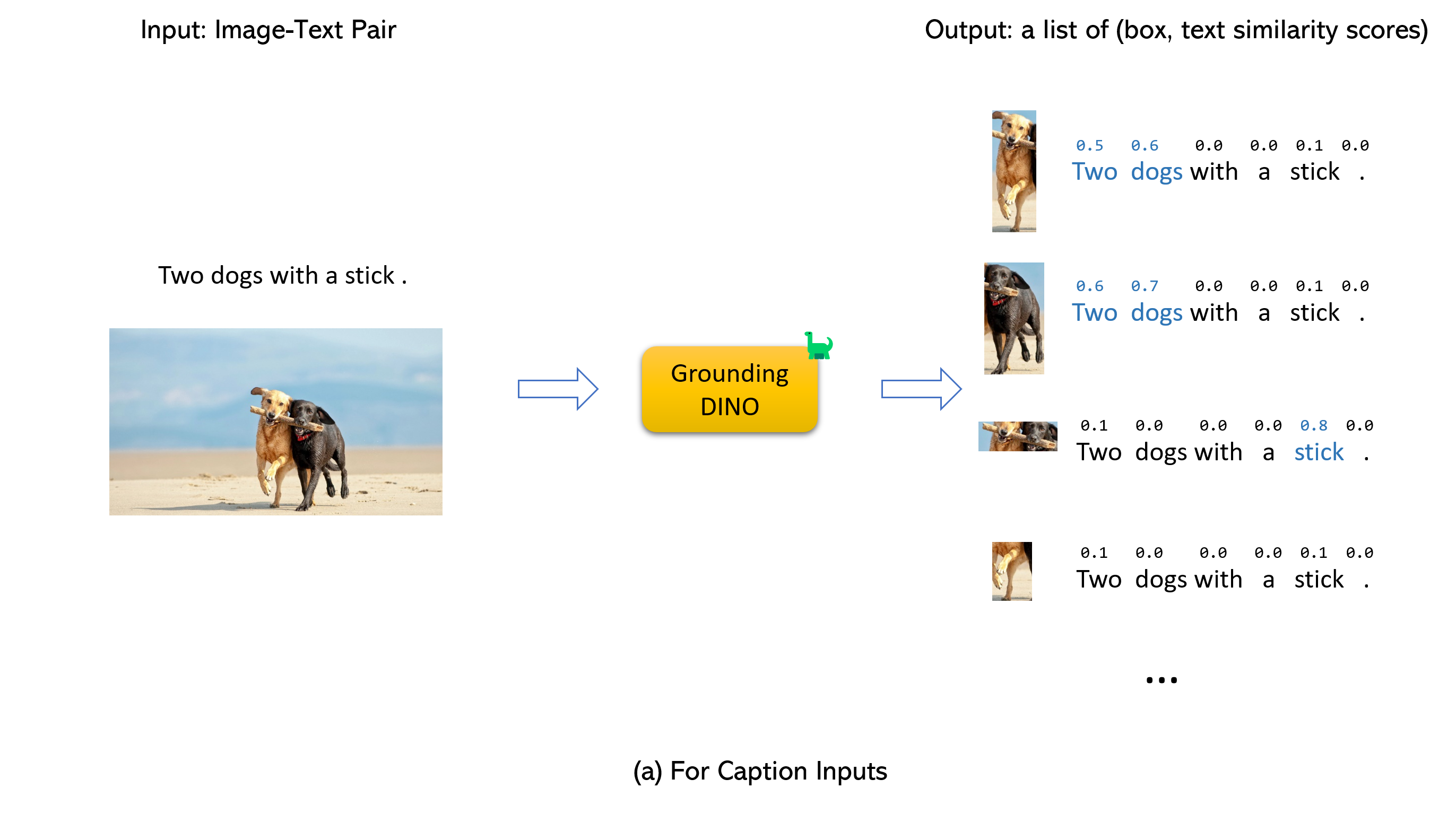
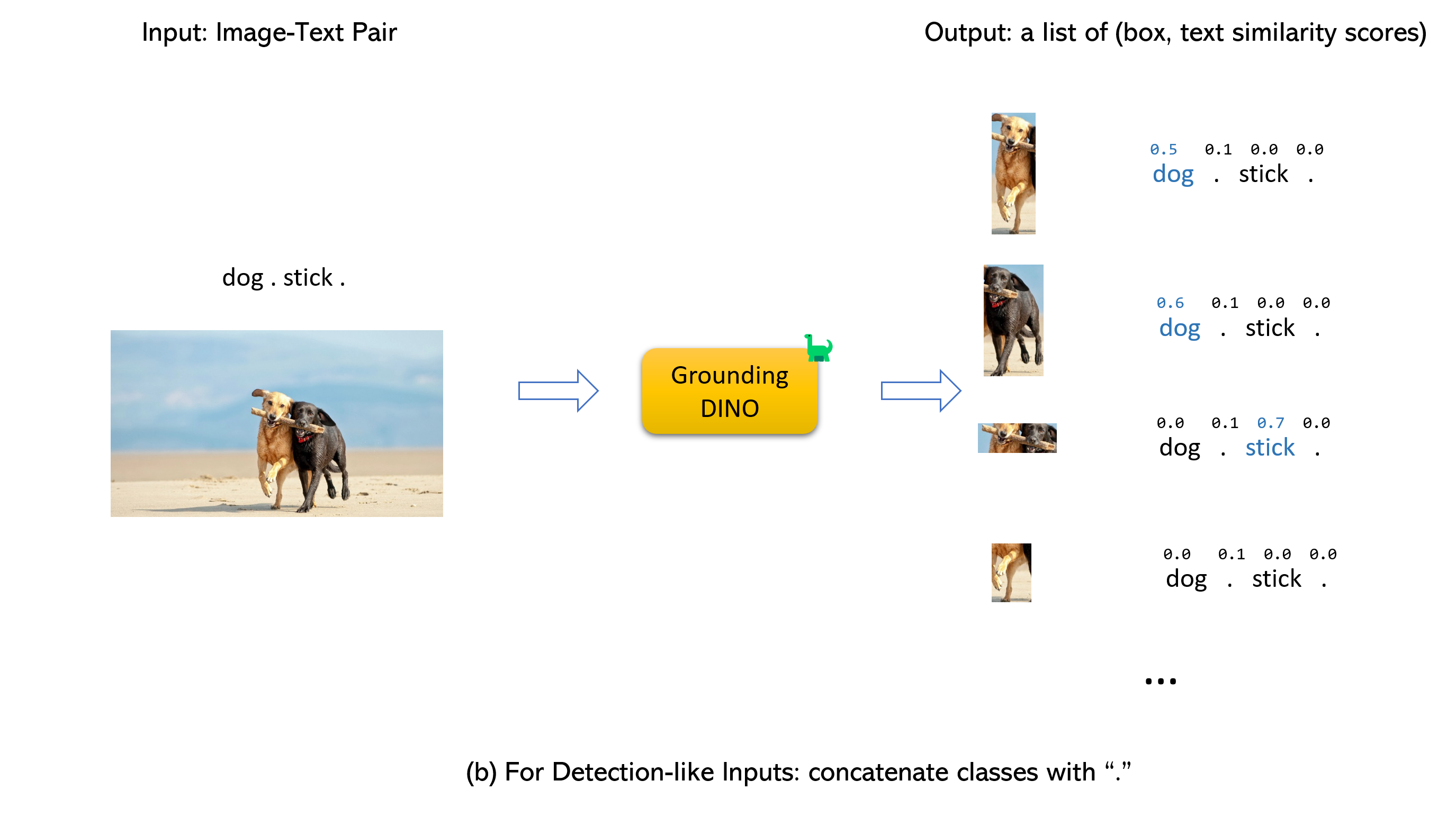
筆記:
CUDA_HOME 。如果沒有CUDA,它將以僅CPU模式進行編譯。請確保嚴格遵循安裝步驟,否則該程序可能會產生:
NameError: name ' _C ' is not defined如果發生這種情況,請通過seclone git重新安裝地面迪諾,然後再次完成所有安裝步驟。
echo $CUDA_HOME如果什麼都沒打印,則意味著您沒有設置路徑/
運行此操作,以便將環境變量設置為當前外殼。
export CUDA_HOME=/path/to/cuda-11.3請注意,CUDA的版本應與您的CUDA運行時對齊,因為可能同時存在多個CUDA。
如果要永久設置CUDA_HOME,請使用:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrc之後,來源bashrc文件並檢查cuda_home:
source ~ /.bashrc
echo $CUDA_HOME在此示例中,/path/to/cuda-11.3應替換為安裝CUDA工具包的路徑。您可以通過在您的終端中輸入哪個NVCC來找到它:
例如,如果輸出為/usr/local/cuda/bin/nvcc,則:
export CUDA_HOME=/usr/local/cuda安裝:
1.從github插入地面倉庫。
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..檢查您的GPU ID(僅當您使用GPU時)
nvidia-smi替換{GPU ID} , image_you_want_to_detect.jpg和"dir you want to save the output"並在以下命令中使用適當的值
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu mode如果您想指定要檢測到的短語,這裡是一個演示:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode token_spans指定短語的開始和結束位置。例如,第一個短語是[[9, 10], [11, 14]] 。 "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' 。因此,它是指a cat短語。同樣, [[19, 20], [21, 24]]是指a dog短語。
有關更多詳細信息,請參見demo/inference_on_a_image.py 。
與Python一起跑步:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Web UI
我們還提供了一個演示代碼,將接地Dino與Gradio Web UI集成。有關更多詳細信息,請參見文件demo/gradio_app.py 。
筆記本
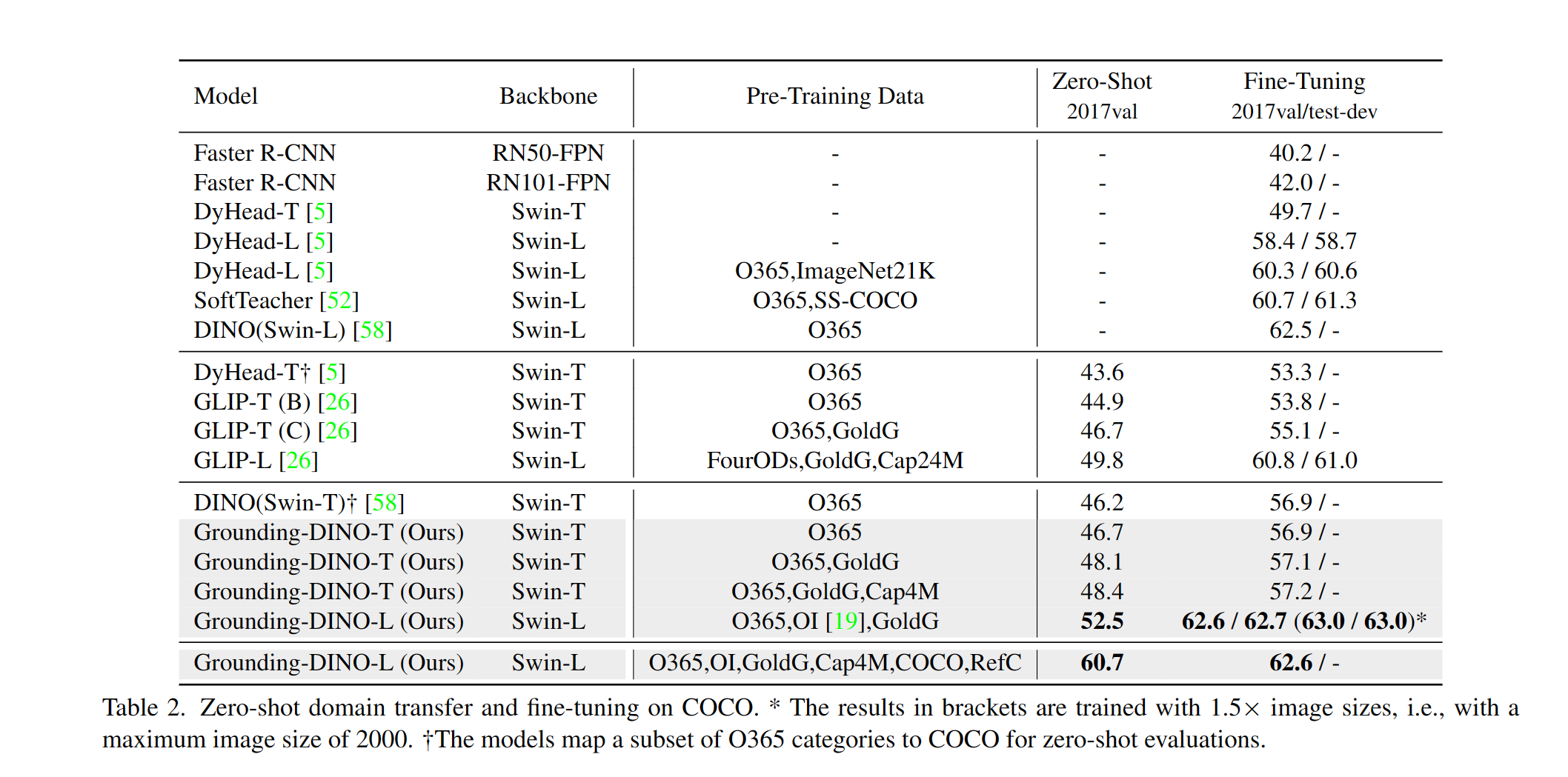
我們提供了一個示例,以評估可可對地面的Dino Zero-Sho-Shot性能。結果應為48.5 。
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
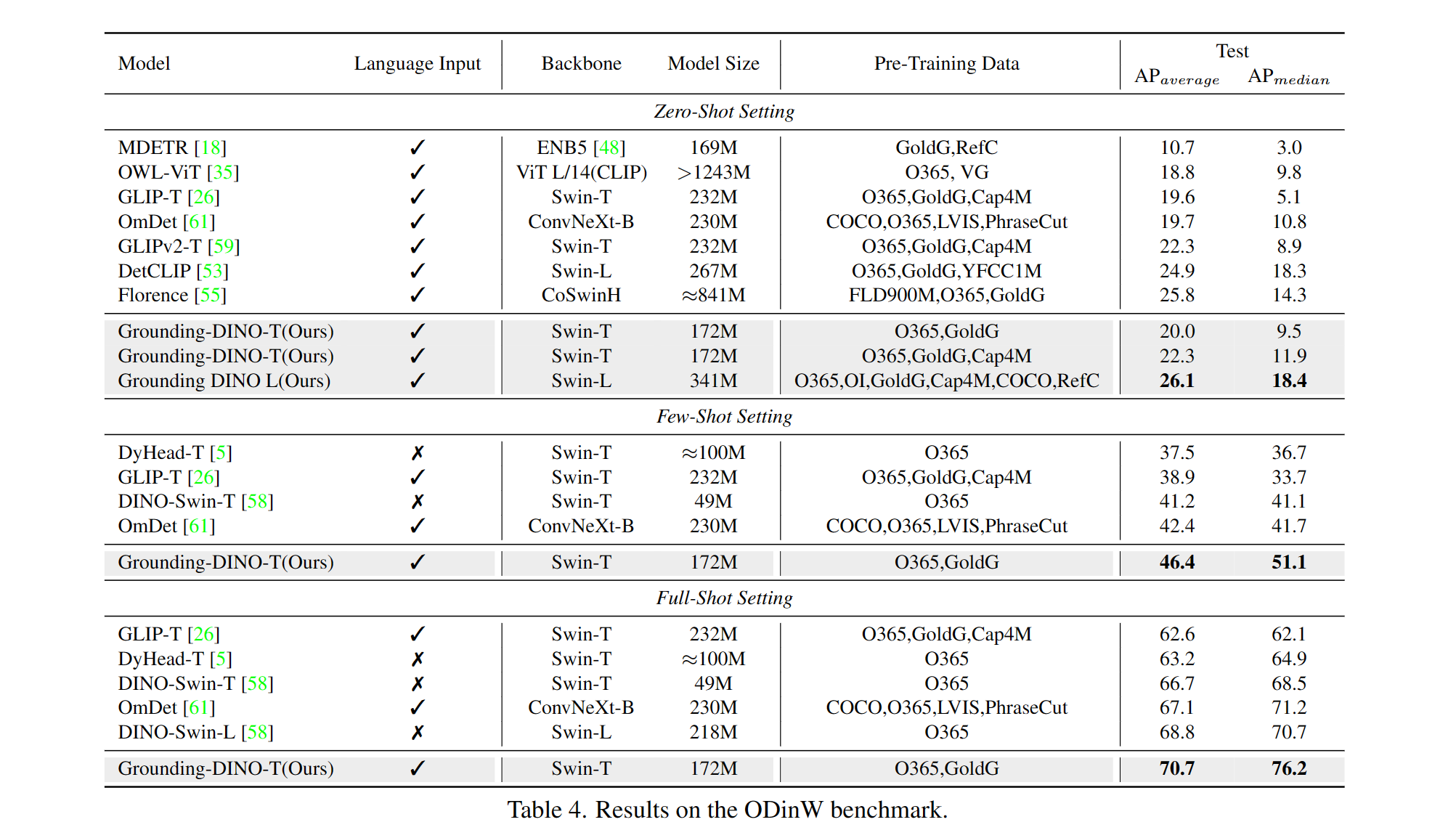
--image_dir /path/to/imagedir/ie/val2017| 姓名 | 骨幹 | 數據 | 可可的盒子AP | 檢查點 | config | |
|---|---|---|---|---|---|---|
| 1 | 接地tino-t | SWIN-T | O365,Goldg,CAP4M | 48.4(零射) / 57.2(微調) | github鏈接| HF鏈接 | 關聯 |
| 2 | 接地迪諾-B | SWIN-B | 可可,O365,GoldG,CAP4M,OpenImage,Odinw-35,Refcoco | 56.7 | github鏈接| HF鏈接 | 關聯 |

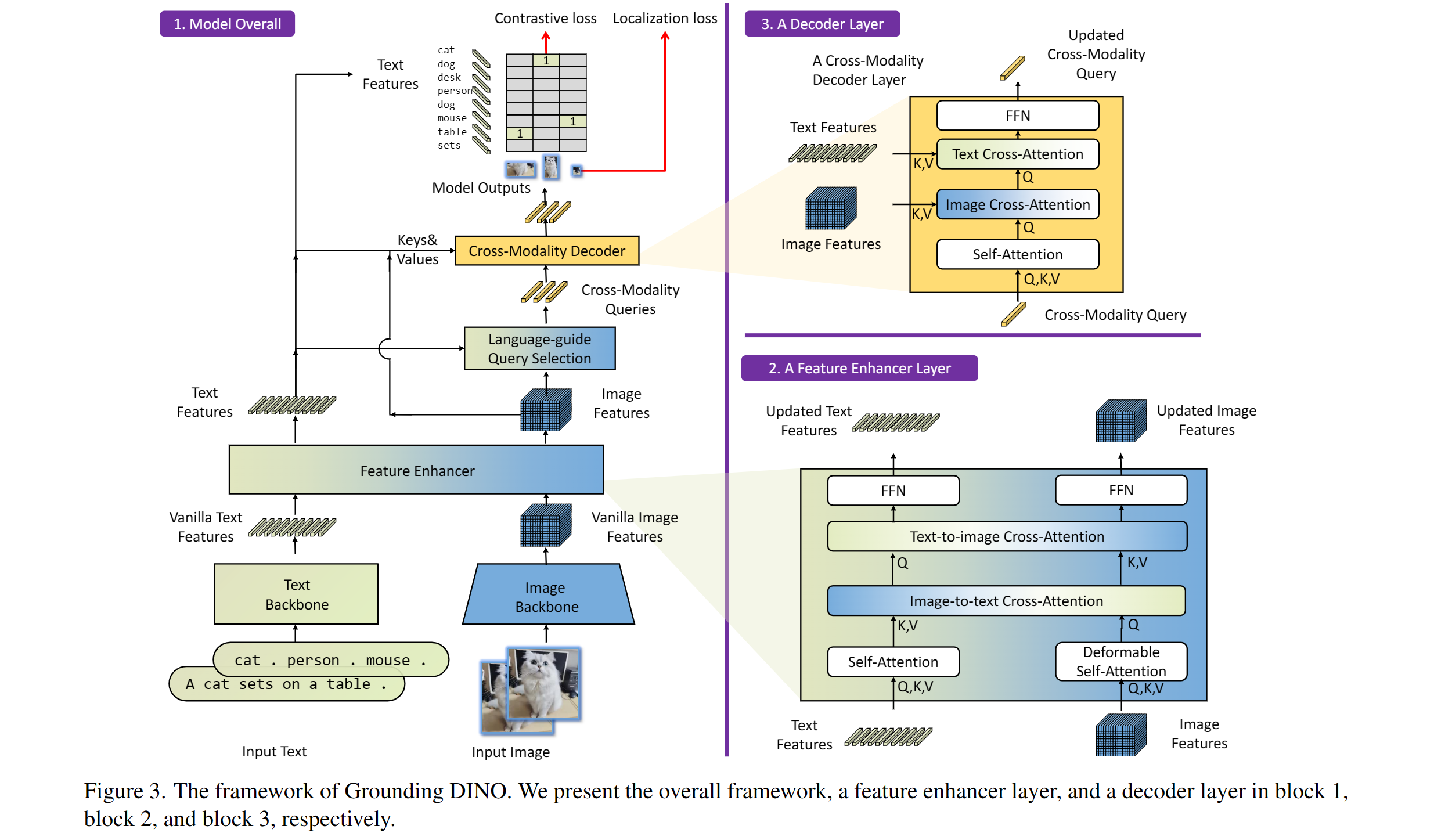
包括:文本骨幹,圖像骨幹,功能增強器,語言引導的查詢選擇和交叉模式解碼器。
我們的模型與Dino和Glip有關。感謝他們的出色工作!
我們還要感謝以前的出色工作,包括Detr,可變形的DETR,SMCA,有條件的DETR,錨點DETR,Dynamic Detr,Dab-Dert,DAB-DETR,DN-DET。也可以使用新的工具箱detrex。
感謝Stable擴散和Gligen的出色模型。
如果您發現我們的工作對您的研究有幫助,請考慮引用以下Bibtex條目。
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

