vision_transformer
1.0.0
在此存儲庫中,我們從論文中發布模型
這些模型已在ImageNet和Imagenet-21K數據集上進行了預訓練。我們提供用於微調Jax/Flax中發布模型的代碼。
該代碼庫中的模型最初是在https://github.com/google-research/big_vision/中進行培訓的/vit_i21k.py用於預訓練vit或configs/trass.py用於傳輸模型)。
目錄:
在Colabs下方,既有GPU,又有TPU(8個核心,數據並行性)。
第一個COLAB展示了視覺變壓器和MLP混合器的JAX守則。該COLAB允許您直接從COLAB UI中的存儲庫中編輯文件,並帶有註釋的Colab單元,這些COLAB單元逐步引導您瀏覽代碼,並讓您與數據進行交互。
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/main/vit_jax.ipynb
第二個COLAB允許您探索> 50k視覺變壓器和用於生成第三篇論文數據“如何訓練VIT?”的數據的混合檢查點。 COLAB包括用於探索和選擇檢查點的代碼,並使用此倉庫中的JAX代碼進行推理,還使用流行的timm Pytorch庫,該庫也可以直接加載這些檢查點。請注意,少數模型也可以直接從TF-Hub提供:Sayakpaul/Collections/Vision_transformer(Sayak Paul的外部貢獻)。
第二個COLAB還可以讓您在任何TFD數據集和您自己的數據集上微調檢查點,並在單個JPEG文件中進行示例(可選地直接從Google Drive讀取)。
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/main/vit_jax_augreg.ipynb
注意:目前(6/20/21)Google COLAB僅支持單個GPU(NVIDIA TESLA T4),而TPU(當前TPUV2-8)間接地連接到Colab VM並通過慢速網絡進行通信,從而導致漂亮的網絡。訓練速度不佳。如果您有多種數據進行微調,通常需要設置專用的計算機。有關詳細信息,請參見雲部分上的運行。
確保您的機器上安裝了Python>=3.10 。
通過運行來安裝JAX和Python依賴性:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
對於JAX的較新版本,請遵循此處鏈接的相應存儲庫中提供的說明。請注意,CPU,GPU和TPU的安裝說明略有不同。
安裝FlaxFormer,按照此處鏈接的相應存儲庫中提供的說明。
有關更多詳細信息,請參閱下面雲上運行的部分。
您可以在感興趣的數據集上微調下載的模型。所有模型共享相同的命令行接口。
例如,用於對CIFAR10上的VIT-B/16進行微調(在Imagenet21K上進行預訓練)(請注意我們如何指定b16,cifar10作為配置的參數,以及我們如何指示代碼直接從GCS Buccet訪問模型而不是首先將它們下載到本地目錄):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k '為了微調CIFAR10上的Mixer-B/16(在Imagenet21K上進行預訓練):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' “如何訓練VIT?...”紙張添加了> 50k檢查點,您可以使用configs/augreg.py配置進行微調。當您僅指定模型名稱( config.name值中的configs/model.py )時,則選擇了上游驗證精度的最佳i21k檢查點(“推薦”檢查點,請參見論文第4.5節)。要下定決心要使用哪種型號,請查看紙張中的圖3。還可以選擇一個不同的檢查點(請參閱Colab vit_jax_augreg.ipynb ),然後從filename或adapt_filename列中指定值,該值與無需.npz的文件名對應於gs://vit_models/augreg目錄。
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01當前,該代碼將自動下載CIFAR-10和CIFAR-100數據集。使用TensorFlow數據集庫可以輕鬆地集成其他公共或自定義數據集。請注意,您還需要更新vit_jax/input_pipeline.py以指定有關任何添加數據集的一些參數。
請注意,我們的代碼使用所有可用的GPU/TPU進行微調。
要查看所有可用標誌的詳細列表,請運行python3 -m vit_jax.train --help 。
記憶的註釋:
--config.accum_steps=8的值,或者,您也可以減少--config.batch=512 (並相應地降低--config.base_lr )。--config.shuffle_buffer=50000 。 由Alexey Dosovitskiy*†,Lucas Beyer*,Alexander Kolesnikov*,Dirk Weissenborn*,Xiaohua Zhai*,Thomas Unterthiner,Mostafa Dehghani,Matthiassinerer,Matthiassinerer,Matthias Minderer,Georg Heigold,Georg Heigold,Sylvain Gelly,Sylvain Gelly Gelly Gelly,Jakzkob Usit和neilial and neil neil andsby*I.
(*)同等的技術貢獻,(†)同等的建議。
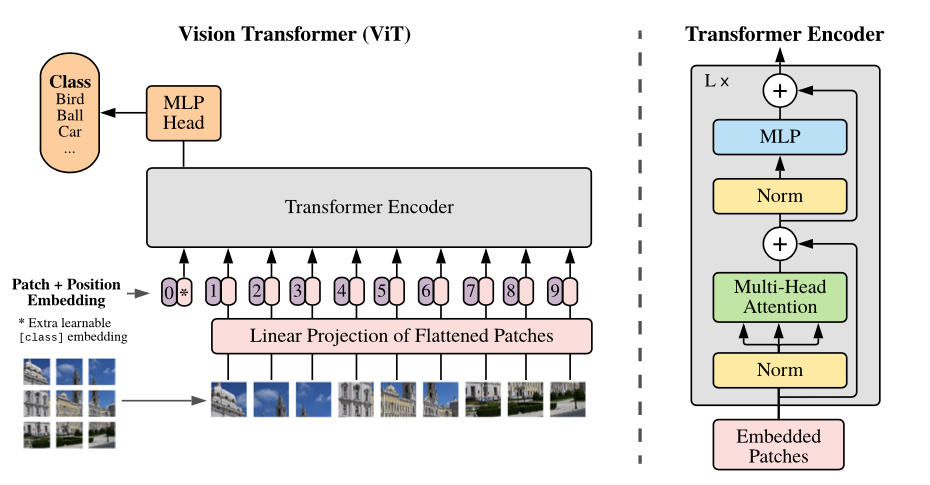
模型的概述:我們將圖像拆分為固定尺寸的補丁,線性嵌入每個貼片,添加位置嵌入,然後將矢量的序列饋送到標準變壓器編碼器中。為了執行分類,我們使用標準方法將額外的可學習的“分類令牌”添加到序列中。
我們在不同的GCS存儲桶中提供各種VIT模型。這些模型可以通過EG下載:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
模型文件名(不帶.npz擴展名)對應於vit_jax/configs/models.py的config.model_name 。
gs://vit_models/imagenet21k在Imagenet-21K上預先訓練的模型。gs://vit_models/imagenet21k+imagenet2012模型在Imagenet-21K上預先訓練,並在Imagenet上進行微調。gs://vit_models/augreg在Imagenet-21K上預先訓練的模型,應用不同量的AUGREG。提高性能。gs://vit_models/sam用SAM預先訓練的模型。gs://vit_models/gsam用GSAM預先訓練的模型。我們建議使用以下檢查點,該檢查站接受了具有最好的預訓練指標的AUGREG培訓:
| 模型 | 預訓練的檢查點 | 尺寸 | 微調檢查點 | 解決 | img/sec | 成像網的精度 |
|---|---|---|---|---|---|---|
| l/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85% |
| ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58% |
| R+Ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40% |
使用來自gs://vit_models/imagenet21k的模型複制了原始VIT論文(https://arxiv.org/abs/2010.11929)的結果。
| 模型 | 數據集 | 輟學= 0.0 | 輟學= 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | CIFAR10 | 98.72%,3.9h(A100),TB.DEV | 98.94%,10.1H(V100),TB.DEV |
| R50+VIT-B_16 | CIFAR100 | 90.88%,4.1H(A100),tb.dev | 92.30%,10.1h(v100),tb.dev |
| R50+VIT-B_16 | Imagenet2012 | 83.72%,9.9h(A100),TB.DEV | 85.08%,24.2h(v100),tb.dev |
| VIT-B_16 | CIFAR10 | 99.02%,2.2h(a100),tb.dev | 98.76%,7.8h(v100),tb.dev |
| VIT-B_16 | CIFAR100 | 92.06%,2.2H(A100),tb.dev | 91.92%,7.8h(v100),tb.dev |
| VIT-B_16 | Imagenet2012 | 84.53%,6.5h(A100),TB.DEV | 84.12%,19.3h(v100),tb.dev |
| VIT-B_32 | CIFAR10 | 98.88%,0.8h(a100),tb.dev | 98.75%,1.8h(v100),tb.dev |
| VIT-B_32 | CIFAR100 | 92.31%,0.8H(A100),TB.DEV | 92.05%,1.8h(v100),tb.dev |
| VIT-B_32 | Imagenet2012 | 81.66%,3.3h(a100),tb.dev | 81.31%,4.9h(v100),tb.dev |
| VIT-L_16 | CIFAR10 | 99.13%,6.9h(A100),TB.DEV | 99.14%,24.7h(v100),tb.dev |
| VIT-L_16 | CIFAR100 | 92.91%,7.1H(A100),tb.dev | 93.22%,24.4h(v100),tb.dev |
| VIT-L_16 | Imagenet2012 | 84.47%,16.8h(A100),TB.DEV | 85.05%,59.7h(v100),tb.dev |
| VIT-L_32 | CIFAR10 | 99.06%,1.9H(A100),TB.DEV | 99.09%,6.1H(V100),TB.DEV |
| VIT-L_32 | CIFAR100 | 93.29%,1.9H(A100),TB.DEV | 93.34%,6.2h(v100),tb.dev |
| VIT-L_32 | Imagenet2012 | 81.89%,7.5h(A100),TB.DEV | 81.13%,15.0h(v100),tb.dev |
我們還要強調,通過較短的培訓時間表可以實現高質量的結果,並鼓勵我們的代碼用戶使用超參數來折衷準確性和計算預算。下表列出了CIFAR-10/100數據集的一些示例。
| 上游 | 模型 | 數據集 | total_steps / hamphup_steps | 準確性 | 牆上的時間 | 關聯 |
|---|---|---|---|---|---|---|
| Imagenet21K | VIT-B_16 | CIFAR10 | 500 /50 | 98.59% | 17m | Tensorboard.dev |
| Imagenet21K | VIT-B_16 | CIFAR10 | 1000 /100 | 98.86% | 39m | Tensorboard.dev |
| Imagenet21K | VIT-B_16 | CIFAR100 | 500 /50 | 89.17% | 17m | Tensorboard.dev |
| Imagenet21K | VIT-B_16 | CIFAR100 | 1000 /100 | 91.15% | 39m | Tensorboard.dev |
由Ilya Tolstikhin*,Neil Houlsby*,Alexander Kolesnikov*,Lucas Beyer*,Xiaohua Zhai,Thomas Unterthiner,Jessica Yung,Andreas Steiner,Andreas Steiner,Daniel Keysers,Daniel Keysers,Jakob Uszkkoreit,Mario Lucic,Mario Lucic,Alexey Dosovitskiy。
(*)同等貢獻。
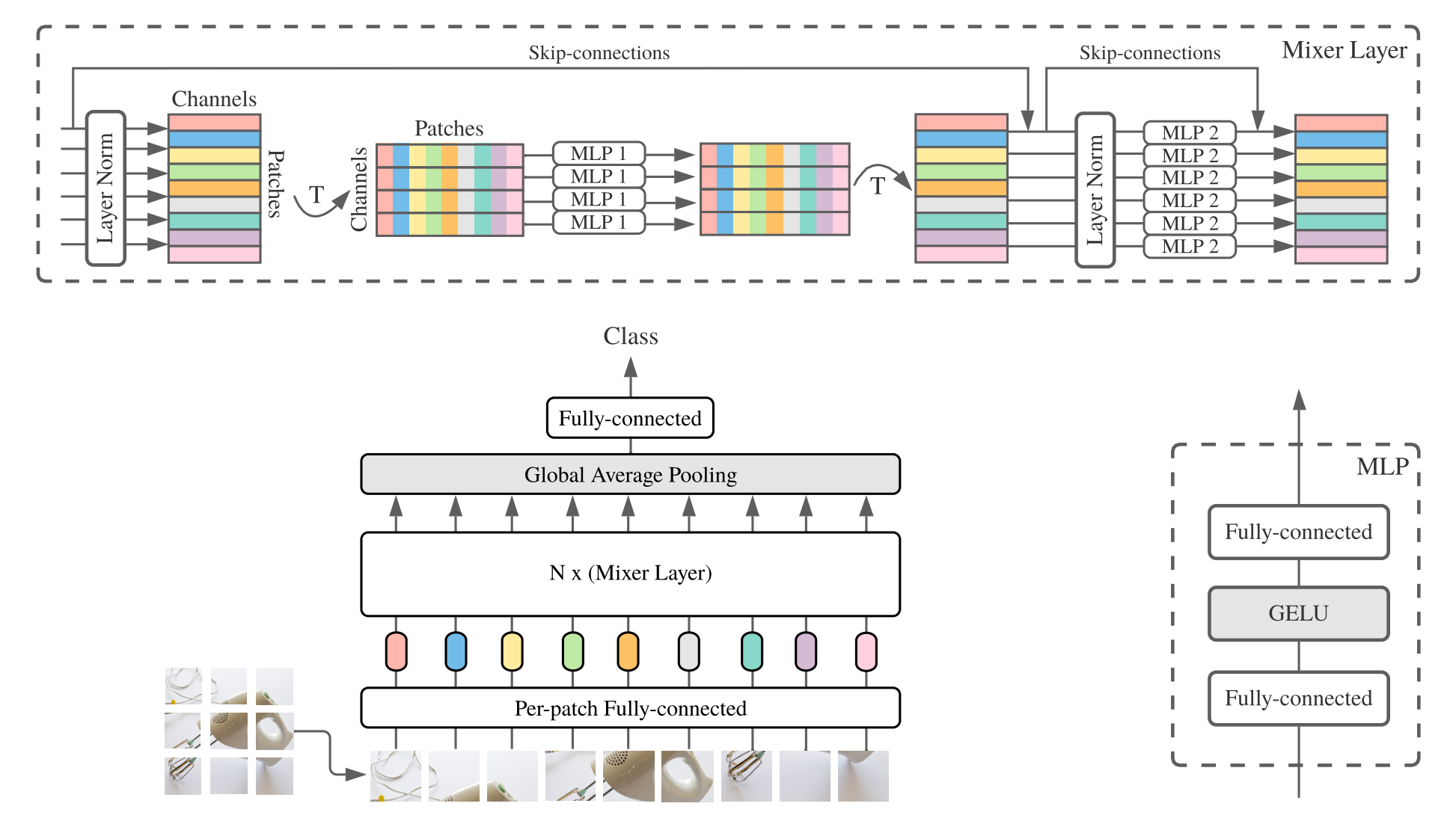
MLP-Mixer(簡短的混合器)由每次斑點線性嵌入,混合層和分類器頭組成。混合層包含一個令牌混合MLP和一個混合MLP,每個MLP由兩個完全連接的層和一個Gelu非線性組成。其他組件包括:跳過連接,輟學和線性分類器頭。
對於安裝,請按照上述步驟進行相同的步驟。
我們提供了在ImageNet和Imagenet-21K數據集上預先訓練的混合器-B/16和混合器L/16模型。詳細信息可以在混合紙的表3中找到。所有模型都可以找到:
https://console.cloud.google.com/storage/mixer_models/
請注意,這些模型也可以直接從TF-HUB獲得:Sayakpaul/Collections/MLP-Mixer(Sayak Paul的外部貢獻)。
我們在Google Cloud Machine上使用了四個V100 GPU在該存儲庫中使用了四個V100 GPU的微調代碼。這是結果:
| 上游 | 模型 | 數據集 | 準確性 | wall_clock_time | 關聯 |
|---|---|---|---|---|---|
| 成像網 | 混音器-B/16 | CIFAR10 | 96.72% | 3.0H | Tensorboard.dev |
| 成像網 | 混音器l/16 | CIFAR10 | 96.59% | 3.0H | Tensorboard.dev |
| Imagenet-21k | 混音器-B/16 | CIFAR10 | 96.82% | 9.6H | Tensorboard.dev |
| Imagenet-21k | 混音器l/16 | CIFAR10 | 98.34% | 10.0h | Tensorboard.dev |
有關詳細信息,請參閱Google AI博客文章LIT:在圖像模型中添加語言理解,或閱讀CVPR紙“ LIT:使用鎖定圖像文本調整”(https://arxiv.org/abs/2111.079991) )。
我們發布了一個具有成像Zeroshot精度為72.1%的變壓器B/16基本模型,以及一個具有ImageNet Zeroshot精度為75.7%的L/16大型模型。有關這些型號的更多詳細信息,請參閱LIT模型卡。
我們提供一個帶有小文本編碼器的瀏覽器演示(最小的型號甚至應該在現代手機上運行):
https://google-research.github.io/vision_transformer/lit/
最後,COLAB使用與圖像和文本編碼器的JAX模型:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
請注意,以上模型尚未支持多語言輸入,但是我們正在努力發布此類模型,並一旦可用來更新該存儲庫。
該存儲庫僅包含針對LIT模型的評估代碼。您可以在big_vision存儲庫中找到培訓代碼:
https://github.com/google-research/big_vision/tree/main/main/big_vision/configs/proj/image_text
預期的zeroshot結果來自model_cards/lit.md (請注意,Zeroshot評估與COLAB中的簡化評估略有不同):
| 模型 | B16B_2 | L16L |
|---|---|---|
| Imagenet零射 | 73.9% | 75.7% |
| Imagenet V2零射 | 65.1% | 66.6% |
| CIFAR100零射 | 79.0% | 80.5% |
| PETS37零射 | 83.3% | 83.3% |
| resisc45零射 | 25.3% | 25.6% |
| MS-Coco字幕圖像到文本檢索 | 51.6% | 48.5% |
| MS-Coco字幕文本對圖像檢索 | 31.8% | 31.1% |
雖然上colabs上方的起步非常有用,但您通常需要在具有更強大加速器的較大機器上訓練。
您可以使用以下命令在Google Cloud上設置使用GPU的VM:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAME另外,您可以使用以下類似命令來設置帶有TPU的雲VM(以下從TPU教程複製的命令):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME然後像往常一樣獲取存儲庫和安裝依賴關係(包括帶有TPU支持的jaxlib ):
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activate如果您連接到附加GPU的VM,請使用以下命令安裝JAX和其他依賴關係:
pip install -r vit_jax/requirements.txt如果您連接到附加TPU的VM,請使用以下命令安裝JAX和其他依賴項:
pip install -r vit_jax/requirements-tpu.txt安裝FlaxFormer,按照此處鏈接的相應存儲庫中提供的說明。
對於GPU和TPU,請檢查JAX是否可以使用命令連接到附加的加速器:
python -c ' import jax; print(jax.devices()) '最後執行對模型進行微調部分中提到的命令之一。
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
按時間順序相反:
2022-08-18:添加了LIT-B16B_2型號,該型號接受了60k步驟(LIT_B16B:30K)的訓練,而圖像側沒有線性頭(LIT_B16B:768),並且性能更好。
2022-06-09:添加了使用ImageNet上GSAM從頭開始訓練的VIT和混音器模型,而無需大量數據增強。最終的VITS優於使用ADAMW優化器或原始SAM算法或具有強大數據增強的類似尺寸的尺寸。
2022-04-14:添加了點亮模型的型號和Colab。
2021-07-29:添加了VIT-B/8 AUGREG模型(3個上游檢查點和分辨率= 224的改編)。
2021-07-02:添加了“當視覺變壓器優於重置...”紙
2021-07-02:添加了SAM(清晰感最小化)優化的VIT和MLP混合檢查點。
2021-06-20:添加了“如何訓練您的Vit?...”紙,以及新的COLAB探索紙張中提到的> 50K預訓練和微調的檢查點。
2021-06-18:此存儲庫被重寫用於使用亞麻亞麻api和ml_collections.ConfigDict進行配置。
2021-05-19:隨著“如何培訓您的VIT?...”紙張,我們在Imagenet和Imagenet-21K上添加了超過50k的Vit和Hybrid模型,並具有不同程度的數據增強和模型正則化。並在Imagenet,Pets37,Kitti-Distance,Cifar-100和Resisc45上進行微調。請查看vit_jax_augreg.ipynb以瀏覽模型的此寶藏!例如,您可以使用該Colab從表3的i21k_300列中獲取推薦的預訓練和微調檢查點的文件名。
2020-12-01:添加了R50+VIT-B/16混合模型(在Resnet-50骨架之上的VIT-B/16)。當在Imagenet21K上預估計時,該模型幾乎達到了L/16模型的性能,而計算芬特的成本卻不到一半。請注意,“ R50”對B/16變體進行了修改:原始Resnet-50具有[3,4,6,3]塊,每個塊將圖像的分辨率減少了兩個因子。結合RESNET莖結合使用,這將導致32倍減少,因此即使貼片大小為(1,1),VIT-B/16變體也無法再實現。因此,我們將[3,4,9]塊用於R50+B/16變體。
2020-11-09:添加了VIT-L/16模型。
2020-10-29:在ImageNet-21K上預測的VIT-B/16和VIT-L/16模型,然後以224x224分辨率在Imagenet上進行微調(而不是默認的384x384)。這些型號的名稱具有後綴“ -224”。預計他們將分別達到81.2%和82.7%的TOP-1精確度。
安德烈亞斯·斯坦納(Andreas Steiner)準備的開源釋放。
注意:該存儲庫是從Google-Research/BIG_TRANSFER進行分配和修改的。
這不是官方的Google產品。


