streaming
v0.9.1
我們構建了StreamDataSet,以盡可能快,便宜和可擴展的雲存儲在大型數據集上進行培訓。
它是專門為大型模型的多節點,分佈式培訓而設計的,最大程度地提高了正確性保證,性能和易用性。現在,您可以在任何地方有效地訓練,而與培訓數據位置無關。只需在需要時流中所需的數據即可。要了解有關我們為什麼構建StreamDataSet的更多信息,請閱讀我們的公告博客。
StreamingDataSet與任何數據類型兼容,包括圖像,文本,視頻和多模式數據。
支持主要的雲存儲提供商(AWS,OCI,GCS,Azure,Databricks和任何S3兼容對象存儲,例如CloudFlare R2,CoreWeave,Backblaze B2等),並設計為用於您的Pytorch IterabledataSet類的置換式替代品,StreamDataSet無縫集成到您現有的培訓工作流程中。

可以使用pip安裝流媒體:
PIP安裝MosaiCML流程
將您的原始數據集轉換為我們支持的流媒體格式之一:
可以編碼和解碼任何Python對象的MDS(Mosaic Data Shard)格式
CSV / TSV
jsonl
import numpy as npfrom PIL import Imagefrom streaming import MDSWriter# Local or remote directory in which to store the compressed output filesdata_dir = 'path-to-dataset'# A dictionary mapping input fields to their data typescolumns = {'image': 'jpeg' ,'class':'int'}#shard Compression,如果AnyCompression ='ZSTD'#使用mdswriterwith mdswriter(out = data_dir,columns = columns = columns = compression = compression = compression = compression = compression = compression = out)將樣品保存為shards:in範圍(10000)(10000) ):sample = {'image':image.fromarray(np.random.randint(0,256,(32,32,3),np.uint8)),' class':np.random.randint(10),,
} out.write(示例)將流數據集上傳到您選擇的雲存儲(AWS,OCI或GCP)。以下是使用AWS CLI將目錄上傳到S3存儲桶的一個示例。
$ AWS S3 CP-恢復途徑to to-dataset s3:// my-bucket/to to to to to to to-dataset
來自TORCH.UTILS.DATA import DataLoAdervrom trow imprimpt streamDataSet#遠程路徑,其中完整數據集持續使用StordRemote ='s3:// my-bucket/my-bucket/my-bucket/path to to to to to to to to to to to to to to to to to to to to path to to local working dir,其中數據集在操作las cach ='/tmp ='/tmp ='/tmp ='/tmp ='/tmp ='/tmp = '/tmp ='/tmp /to to to to to to create create stream datasetDataSet = streamingdataset(local = local = local = remote = remote,shuffle = true)#讓我們查看樣本#1337中的內容...示例= dataset [1337] img = sample ['image ['image '] cls =示例['class']#創建pytorch dataloaderdataloader = dataloader(dataset)
入門指南,示例,API參考和其他有用的信息可以在我們的文檔中找到。
我們有端到端的教程用於培訓模型:
CIFAR-10
臉部固有
Syntheticnlp
我們還提供以下流行數據集的入門代碼,可以在streaming目錄中找到:
| 數據集 | 任務 | 讀 | 寫 |
|---|---|---|---|
| Laion-400m | 文字和圖像 | 讀 | 寫 |
| Webvid | 文字和視頻 | 讀 | 寫 |
| C4 | 文字 | 讀 | 寫 |
| Enwiki | 文字 | 讀 | 寫 |
| 樁 | 文字 | 讀 | 寫 |
| ADE20K | 圖像分割 | 讀 | 寫 |
| CIFAR10 | 圖像分類 | 讀 | 寫 |
| 可可 | 圖像分類 | 讀 | 寫 |
| 成像網 | 圖像分類 | 讀 | 寫 |
開始在這些數據集上培訓:
使用convert目錄的相應腳本將原始數據轉換為.mds格式。
例如:
$ python -m streaming.multimodal.convert.webvid - in <csv file> - 輸出<mds <mds output umput Directory>
導入數據集類以開始訓練模型。
來自stream.multimodal import streamInsideWebViddataset = streamInsideWebVid(local = local = local,remote,遠程=遠程,shuffle = true)
輕鬆地使用與Stream數據集混合物進行實驗。數據集採樣可以相對(比例)或絕對(重複或樣本項)控制。在流媒體播放期間,不同的數據集被流式傳輸,洗牌並無縫恰到時間混合。
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
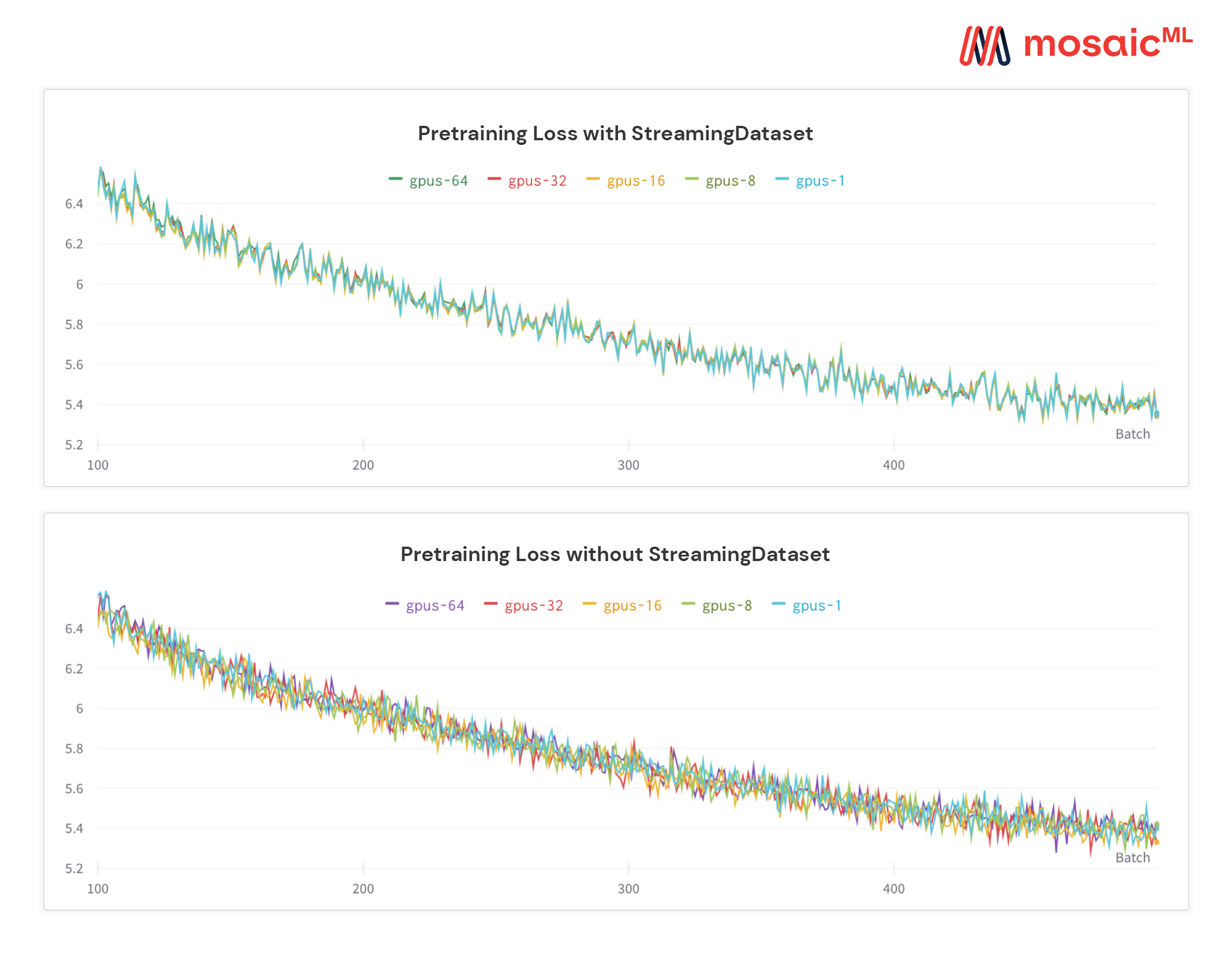
我們解決方案的一個獨特功能:無論GPU,節點或CPU工人的數量如何,樣本的順序都相同。這使得更容易:
複製和調試訓練運行和損失尖峰
在64 GPU上加載一個檢查站,並在8 GPU上進行調試,並具有可重複性
請參閱下圖 - 訓練1、8、16、32或64 GPU的模型產生完全相同的損耗曲線(直至浮點數學的局限性!)
在硬件故障或損失峰值之後,在數據加載器旋轉時,等待您的工作恢復可能很昂貴,而且很煩人。多虧了我們確定的樣本訂購,StreamDataSet使您可以在長期訓練中恢復幾秒鐘而不是小時的培訓。
與現有解決方案相比,最大程度地減少恢復延遲可以節省數千美元的出口費和閒置的GPU計算時間。
我們的MDS格式將無關緊要的工作切割為骨骼,與數據層加載器瓶頸的替代方案相比,超低樣品潛伏期和更高的吞吐量。
| 工具 | 吞吐量 |
|---|---|
| StreamingDataset | 〜19000 img/sec |
| ImageFolder | 〜18000 img/sec |
| WebDataSet | 〜16000 img/sec |
顯示的結果來自Imagenet + Resnet-50訓練,在第一個時期後,數據緩存後,在5個重複中收集了5個訓練。
由於我們的洗牌算法,使用StreamingDataSet的模型收斂與使用本地磁盤一樣好。
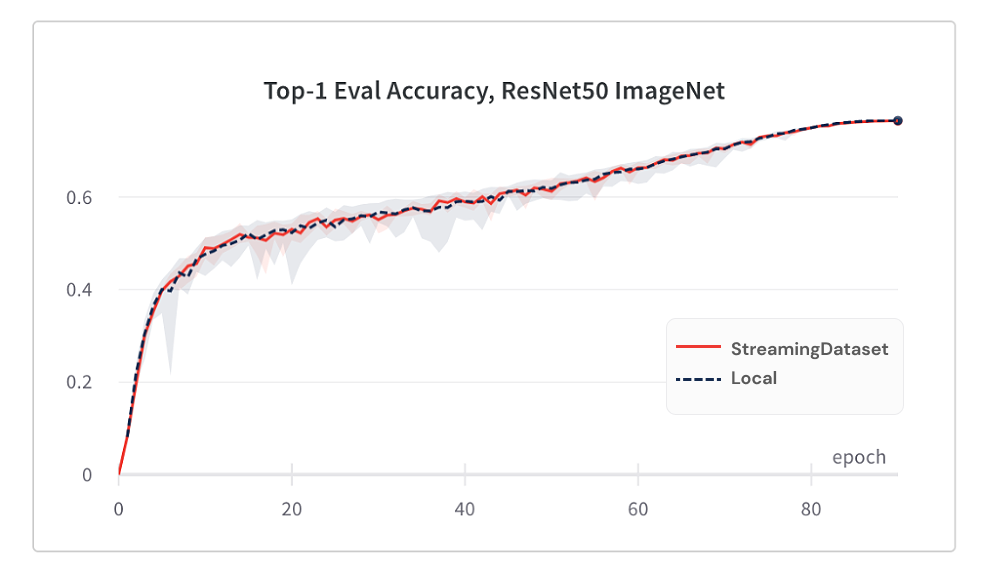
以下是Imagenet + Resnet-50訓練的結果,該培訓收集了5個重複。
| 工具 | TOP-1準確性 |
|---|---|
| StreamingDataset | 76.51%+/- 0.09 |
| ImageFolder | 76.57%+/- 0.10 |
| WebDataSet | 76.23%+/- 0.17 |
分配給節點的所有樣品中的流式dataset隨機散裝,而替代解決方案僅在較小的池中(在單個過程中)中的樣品進行洗牌樣品。在更寬的游泳池上進行改組會更多地散佈相鄰的樣品。此外,我們的洗牌算法最大程度地減少了掉落的樣品。我們發現,這兩個改組功能對模型收斂有利。
需要時訪問您需要的數據。
即使尚未下載示例,您也可以訪問dataset[i]以獲取示例i 。下載將立即啟動,結果將在完成後返回 - 類似於地圖式的Pytorch數據集,其樣品依次按任何順序訪問。
dataset = streamdataset(...)示例=數據集[19543]
StreamingDataSet將在任何數量的樣本上愉快地迭代。您不必永遠刪除樣品,因此數據集可以在烘烤數量的設備上排除。相反,每個時期都重複了不同的樣品選擇(無掉落),以便每個設備都會處理相同的計數。
dataset = streamingdataset(...)dl = dataloader(數據集,num_workers = ...)
動態刪除最近使用的碎片,以將磁盤使用保持在指定的限制下。通過設置streamdataset參數cache_limit啟用了這一點。有關更多詳細信息,請參見“改組指南”。
dataset = StreamingDataset( cache_limit='100gb', ... )
以下是一些使用StreamingDataSet的項目和實驗。有東西要添加嗎? 發送電子郵件至[email protected]或加入我們的社區懈怠。
BiomedLM:Mosaicml和Stanford CRFM的生物醫學特定領域的大型語言模型
馬賽克擴散模型:訓練穩定的從划痕成本<$ 160k
Mosaic LLM:GPT-3質量<$ 500K
馬賽克重新安裝:與馬賽克重新連接和作曲家相關的快速計算機視覺訓練
Mosaic DeepLabv3:使用MosaiCML食譜更快的圖像分割訓練速度更快
…還有更多!敬請關注!
我們歡迎任何貢獻,拉的請求或問題。
要開始貢獻,請參閱我們的貢獻頁面。
PS:我們正在招聘!
如果您喜歡這個項目,請給我們一顆星星並查看我們的其他項目:
作曲家 -現代的Pytorch庫,使可擴展,高效的神經網絡培訓變得容易
MOSAICML示例- 快速訓練ML模型的參考示例,並具有很高的準確性 - 具有GPT /大語言模型的入門代碼,穩定的擴散,Bert,Resnet -50和DeepLabV3
MOSAICML雲- 我們構建的培訓平台旨在最大程度地降低LLM,擴散模型和其他大型型號的培訓成本 - 具有多雲的編排,輕鬆的多節點縮放以及用於加速訓練時間的高度優化
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

