Noise Reduction
1.0.0

關於項目
技術堆棧
文件結構
入門
結果和演示
未來的工作
貢獻者
致謝和資源
執照
需要刪除噪聲,這是自然誘導的,就像非環境噪聲一樣,該噪聲通過信號的降解而被去除。還請參考此文檔有關AI降噪的博客
使用用於音頻操縱的天秤座庫。
對於我們使用Scipy的音頻信號
Matplotlib用於操縱數據並可視化信號。
其餘的對於數學操作而言是龐大的,在波浪文件上操作的浪潮。
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
在窗戶上測試
git克隆https://github.com/dhriti03/noise-reduction.gitcd噪音 - 還原
在您的筆記本中安裝某些庫
PIP安裝波 PIP安裝libreosa PIP安裝scipy.io PIP安裝matplotlib.pyplot
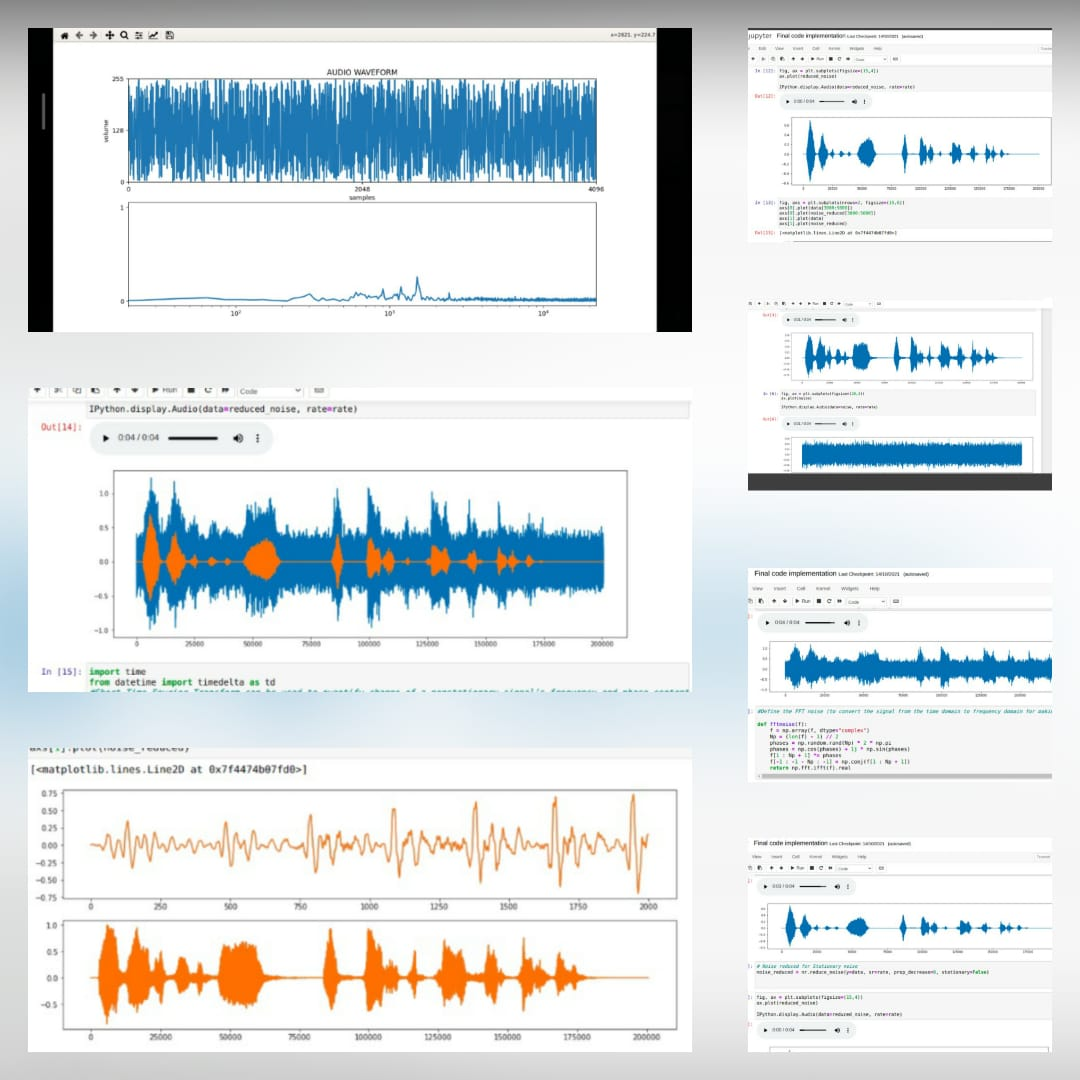
*這是原始音頻文件 * 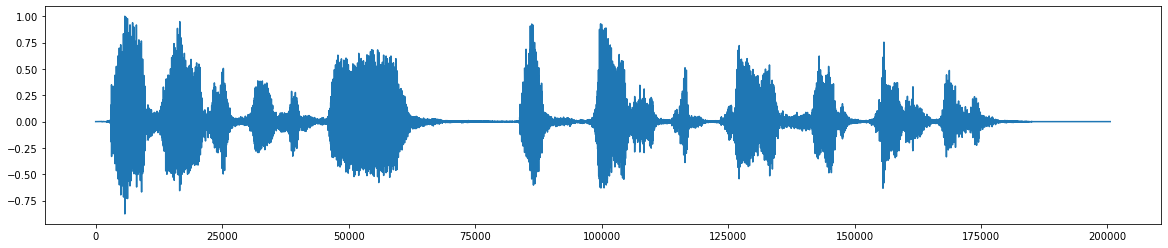 *添加噪音 *之後 *
*添加噪音 *之後 * 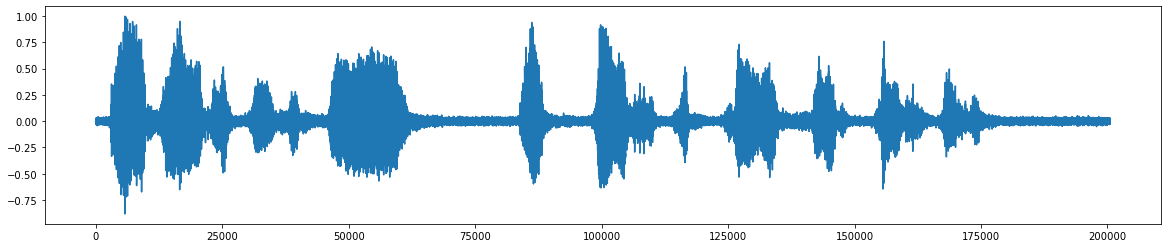 *刪除噪聲後的最終音頻信號 *
*刪除噪聲後的最終音頻信號 * 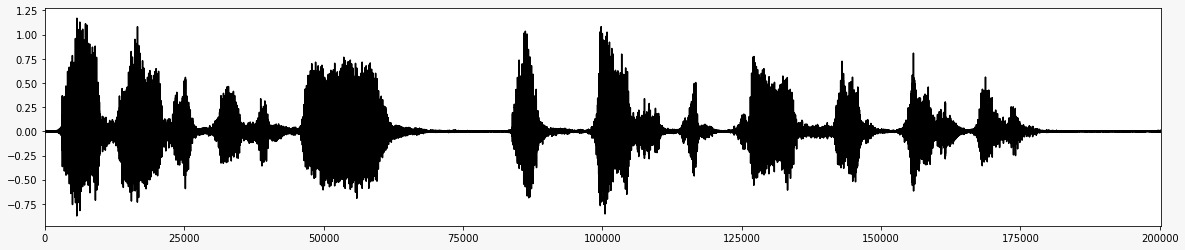 *該項目的流程圖 *
*該項目的流程圖 * 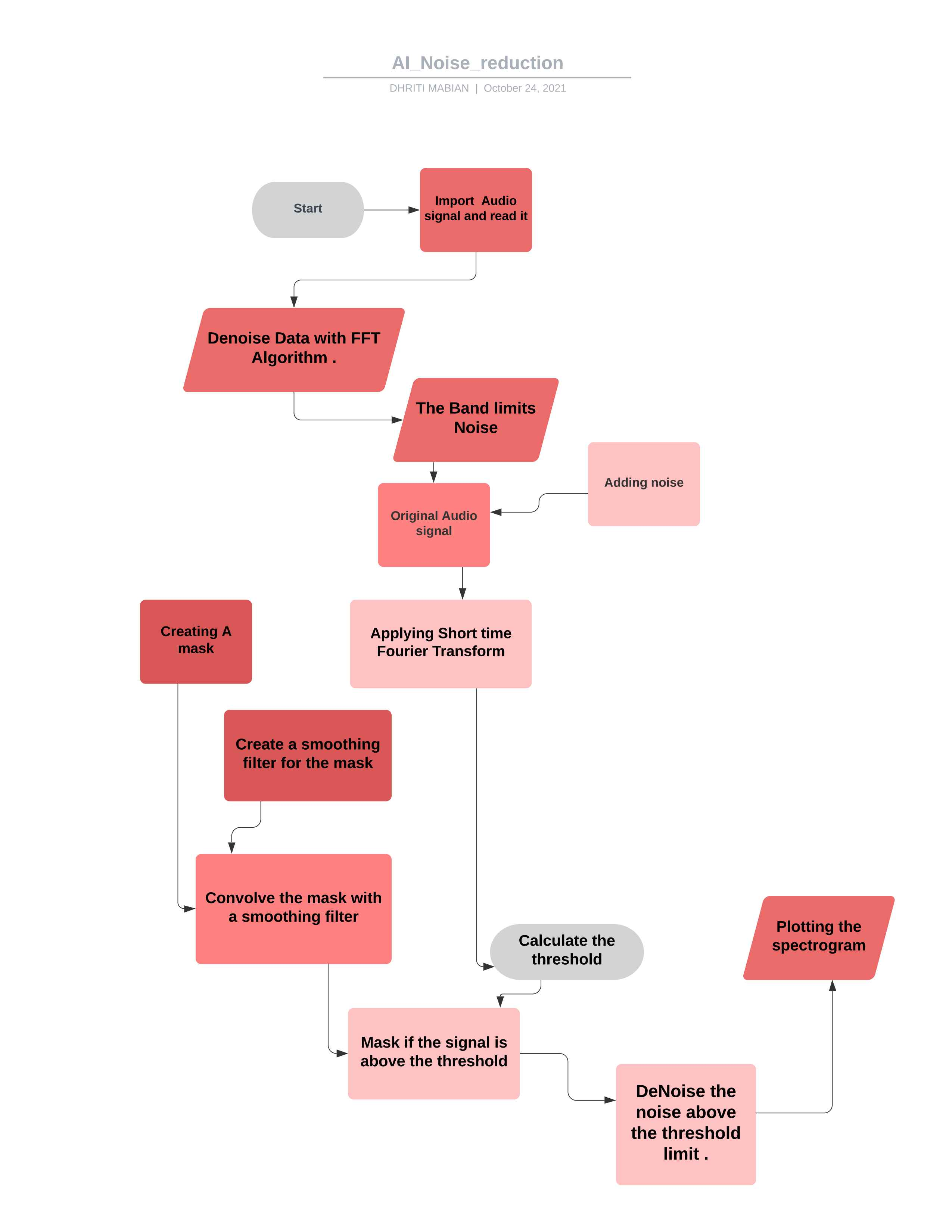
根據您的要求操縱代碼,您可以使用它來控制大多數音頻符號。 ##理論
在噪聲音頻剪輯上計算FFT
統計數據是根據噪聲的FFT計算的(頻率)
根據噪聲的統計數據(以及算法的所需靈敏度)計算閾值
通過將信號FFT與閾值進行比較來確定掩碼
在頻率和時間上使用過濾器使掩模平滑
面具被添加到信號的FFT上,並倒置
從scipy.io導入ipython import wavfileimport scipy.signalimport numpy as npimport matplotlib.pyplot作為pltimport libresaimport wave%matplotlib inline
在這裡,我們正在進口圖書館,例如用於創建用於交互式和探索性計算的全面環境的iPython lib。
從scipy.io庫中,使用多種python命令來操縱數據和可視化數據。
Numpy包含多維陣列和矩陣數據結構。因此,它可以用於對諸如三角,統計和代數例程等數組進行許多數學操作,因此是一個非常有用的庫。
matplotlib.pyplot庫有助於通過不同的可視化來理解大量數據。
Libersa使用音樂生成(使用LSTM),自動語音識別(使用LSTM)等音頻數據時使用。它提供了創建音樂信息檢索系統所需的構建塊。
%matplotlib inline啟用了內聯繪圖,該圖將在繪圖命令寫在的單元格下方。它提供了與jupyter筆記本等前端中後端的互動性。
wav_loc = r'/home/noings_reduction/downloads/wave/file.wav'rate,data = wavfile.read(wav_loc,mmap = false)
在這裡,我們採用WAW文件路徑位置,然後使用來自Scipy.io庫的WaveFile模塊讀取WAW文件。使用參數(文件名 - 字符串或打開文件句柄,是輸入WAV文件。)然後(mmap:bool,可選的,其中是否將數據讀取為內存映射(默認值:false)。
def fftnoise(f):f = np.Array(f,dtype =“複雜”)np =(len(f) - 1)// 2lase = np.random.rand.rand(np) * 2 * np.piphases = np 。 )返回np.fft.ifft(f)
在這裡,我們首先簡要定義FFT噪聲函數,快速傅立葉變換(FFT)是一種計算序列或其逆(IDFT)的離散傅立葉變換(DFT)的算法。傅立葉分析將信號從其原始域(通常是時間或空間)轉換為頻域中的表示形式,反之亦然。 DFT是通過將一系列值分解為不同頻率的組件來獲得的。
使用快速傅立葉變換並定義數據類型複雜的函數,最後計算函數的實際部分。在此,將最小頻率和最大頻率之間的頻率設置為1,而休息不需要的頻率被忽略了。
提供文件位置
讀取WAV文件
-32767至+32767是適當的音頻(對稱),而32768表示在此時剪輯的音頻
wav-file是16位整數,範圍為[-32768,32767],因此除以32768(2^15),將給出[-1,1]的適當的二組配件範圍
def band_limited_noise(min_freq,max_freq,samples = 1024,採樣= 1):freqs = np.abs(np.fft.fft.fftfreq(samples,1 / samples,1 / sampleaser)f = np.法(樣本> = min_freq ,freqs <= max_freq)] = 1返回fftnoise(f)
函數或時間序列的傅立葉變換僅限於有限的頻率或波長范圍。
用標準FREQ定義最小限制和最大限制的FREQ。
noings_len = 2#secondsnoise = band_limited_noise(min_freq = 4000,max_freq = 12000,samples = len(data),samplerate = rate = rate)*10noise_clip = noiese [:reside diesuct [速度*noye_len] audio_clip_band_band_limited = data+data+data+ data+dogati
帶限制的白噪聲塊指定了兩側光譜,其中單元為Hz。
將最大為12000和最小頻率為4000的最小頻率,將噪聲和所提供的數據進行比較。
在這裡,我們通過具有速率的產物和噪聲信號的LEN來剪輯噪聲信號。
因此添加了噪聲和給定的數據
實際上,添加噪聲擴大了訓練數據集的大小。
隨機噪聲被添加到輸入變量中,每次暴露於模型時它們都會不同。
在輸入樣本中添加噪聲是一種簡單的數據增強形式。
添加噪聲意味著網絡無法記住培訓樣本,因為它們一直在改變,
導致較小的網絡權重和一個更健壯的網絡,其概括誤差較低。
導入DateTime的時間導入TIMEDELTA為TD
導入時間該模塊提供了各種與時間相關的功能。有關相關功能,另請參見DateTime和日曆模塊。類dateTime.timedelta
持續時間表達兩個日期,時間或日期時間實例之間的差異到微秒分辨率。
def _stft(y,n_fft,hop_length,win_length):返回blibrosa.stft(y = y,n_fft = n_fft = n_fft,hop_length = hop_length = hop_length,win_length = win_length)
短時間傅立葉變換可用於量化非組織信號的頻率和相位內容隨時間的變化。
跳長應指連續幀之間的樣本數量。對於信號分析,HOP長度應小於幀大小,因此幀重疊。
參數ynp.ndarray [shape =(n,)],實價輸入信號
N_FFTINT> 0 [標量]
用零填充後的窗戶信號的長度。 STFT矩陣D中的行數為(1 + N_FFT/2) 。默認值N_FFT = 2048樣品,對應於93毫秒的物理持續時間,採樣速率為22050 Hz,即Librosa中的默認採樣率。該值適用於音樂信號。但是,在語音處理中,推薦的值為512,對應於23毫秒,採樣速率為22050 Hz。無論如何,我們建議將N_FFT設置為兩個功率,以優化快速傅立葉變換(FFT)算法的速度。
hop_lengthint> 0 [標量]
相鄰STFT列之間的音頻樣本數。
較小的值增加了D中的列數,而不會影響STFT的頻率分辨率。
如果未指定,則默認為win_length // 4(見下文)。
win_lengthint <= n_fft [標量]
每個音頻框架都用長度win_length的窗口窗口,然後用零填充以匹配N_FFT 。
較小的值改善了STFT的時間分辨率(即,以頻率分辨率為代價(即區分頻率緊密間隔的純音調的能力)以犧牲頻率分辨率為代價)。這種效果稱為時頻定位權衡取捨,需要根據輸入信號y的屬性進行調整。
如果未指定,則默認為win_length = n_fft 。
返回libresa.istft(y,hop_length,win_length)
反向短時傅立葉變換(ISTFT)。通過最大程度地降低stft_matrix和y之間的平方平方誤差和y之間的平方誤差,將復合物值頻譜stft_matrix轉化為y。
通常,窗口函數,跳長和其他參數應與STFT相同,這主要導致來自未修改的STFT_MATRIX的信號的完美重建。
def _amp_to_db(x):返回libreosa.core.mplitude_to_db(x,ref = 1.0,amin = 1e-20,top_db = 80.0)
1.將振幅光譜圖轉換為DB尺度頻譜圖。這等同於power_to_db(s ** 2),但為方便起見提供。
返回libreosa.core.db_to_amplitude(x,ref = 1.0)
將DB尺度的光譜圖轉換為振幅光譜圖。
這有效地反轉振幅_to_db:
db_to_amplitude(s_db)〜= 10.0 (0.5*(s_db + log10(ref)/10))**
def plot_spectRogram(信號,標題):圖,ax = plt.subplots(figsize =(20,4))cax = ax.matshow(信號,origin,origin =“ lower”,factor =“ auto”,cmap = plt. cm。地震,vmin = -1 * np.max(np.abs(signal)),vmax = np.max(np.abs(signal)),
)用信號作為輸入繪製鏡頭。
軸類包含大多數圖元素:軸,tick,line2d,文本,多邊形等,並設置坐標系。
它在Matplotlib中提供了可通過此功能訪問的多個顏色地圖。
圖。Colorbar(CAX)AX.SET_TITLE(標題)
查看發生的事情的最佳方法是添加一個配色鍵(創建散點圖之後)。您會注意到,0到10000之間的外觀值全部低於條的最低部分,那裡的東西非常淺綠色。
通常,Vmin以下的值將以最低的顏色顏色,而Vmax上方的值將獲得最高的顏色。
如果您將VMAX小於VMIN設置,則在內部將交換它們。儘管根據Matplotlib的確切版本和所謂的精確函數,Matplotlib可能會發出錯誤警告。因此,最好將VMIN設置為始終低於Vmax。
def plot_statistics_and_filter(mean_freq_noise,std_freq_noise,noings_thresh,smoothing_filter):圖,ax = plt.subplots(ncols = 2,figsize = 2,figsize =(20,4))噪音”))
plt_std,= ax [0] .plot(noye_thresh,label =“噪聲閾值(按頻率)”)ax [0] .set_title(“蒙版的閾值”)
ax [0] .legend()cax = ax [1] .matshow(smoothing_filter,origin =“ lower”)fic.colorbar(cax)ax [1] .set_title(“平滑蒙版的濾鏡”)繪製了降噪的基本統計數據。
信噪比(SNR或S/N)是科學和工程中使用的措施,將所需信號的水平與背景噪聲水平進行比較。
SNR定義為信號功率與噪聲功率的比率,通常在分貝中表達。
高於1:1(大於0 dB)的比率比噪聲更多的信號。
設置噪聲掩蔽的閾值頻率。
掩蓋閾值是指由於存在另一種聲音,因此一種聲音聽不清的過程。
因此,掩蓋閾值是在存在另一種稱為“掩蔽器”的噪音的情況下使聲音可聽見的聲音的聲音水平
因此增加了閾值。
模糊的噪聲信號具有各種低通濾波器
將定製過濾器應用於圖像(2D卷積)
def emovenoise(#要平均三角波的正斜率部分(上升)的信號(電壓),以嘗試刪除盡可能多的噪聲。audio_clip,#這些剪輯是我們使用的參數,操作noiese_clip,n_grad_freq = 2,#使用掩碼平滑的頻率頻道。 2048,#由``窗口''窗口的每個音頻窗口'窗口窗口的長度為`win_length',然後用零填充``n_fft`..hop_length = 512'' n_std_thresh = 1.5, #比噪聲的平均db(在每個頻率級別)被視為signalProp_decrease = 1.0,#在多大程度上降低噪聲(1 = all,0 = none)derbose = false ,#標誌允許您編寫外觀呈現的正則表達式= false,#是繪製算法的步驟):
def emovenoise(平均為三角波的正斜率部分(上升)的信號(電壓),以試圖消除盡可能多的噪聲。
audio_clip,
這些剪輯是我們要進行各自操作的參數
noings_clip, n_grad_freq = 2用掩模平滑多少個頻道。
n_grad_time = 4,用掩碼平滑多少個時間通道。
N_FFT = 2048
STFT列之間幀的數字音頻。
win_length = 2048,每個音頻幀均由window()窗口。該窗口的長度為win_length ,然後用零填充以匹配n_fft 。
hop_length = 512, sTFT列之間幀的數字音頻。
N_STD_THRESH = 1.5比噪聲的平均db(在每個頻率級別上)要被視為信號的標準偏差大多數
prop_decrease = 1.0,您應在多大程度上降低噪聲(1 =全部,0 =無)
冗長= false,
標誌允許您編寫看起來像visual = false的正則表達式, #是繪製算法的步驟):
noings_stft = _stft(noings_clip,n_fft,hop_length,win_length)noiese_stft_db = _amp_to_db(np.abs(noings_stft))
STFT上的噪音
轉換為DB
mean_freq_noise = np.mean(noings_stft_db,axis = 1)std_freq_noise = np.std(noings_stft_db,axis = 1)
計算噪聲的統計數據
在這裡,我們為閾值噪聲添加了平均值和標準噪聲和N_STD噪聲。
sig_stft = _stft(audio_clip,n_fft,hop_length,win_length)sig_stft_db = _amp_to_db(np.abs(sig_stft))
STFT在信號上
mask_gain_db = np.min(_amp_to_db(np.abs(sig_stft))))
將值計算為掩碼數據庫
Smootying_filter = np.outer(np.concatenate(concatenate)(
[np.linspace(0,1,n_grad_freq + 1,endpoint = false),np.linspace(1,0,n_grad_freq + 2),
這是給出的
)[1:-1],np.concatenate(
[np.linspace(0,1,n_grad_time + 1,endpoint = false),np.linspace(1,0,n_grad_time + 2),
這是給出的
)[1:-1],
)Smoothing_filter = Smoothing_filter / np.sum(Smoothing_filter)在時間和頻率上為掩模創建平滑過濾器
db_thresh = np.Repeat(np.Reshape(noings_thresh,[1,len(mean_freq_noise))),np.shape(sig_stft_db)[1],axis = 0,,
).t計算每個頻率/時間箱的閾值
sig_mask = sig_stft_db <db_thresh
信號的蒙版
sig_mask = scipy.signal.fftconvolve(sig_mask,Smoothing_filter,mode =“ same”)sig_mask = sig_mask * prop_decrease
帶平滑過濾器的掩蓋卷積
#掩蓋信號_stft_db_masked =(sig_stft_db *(1 -sig_mask)+ np.ones(np.shape(mask_gain_db)) * mask_gain_gain_db * sig_mask)# _TO_AMP (sig_stft_db_masked) * np.sign(sig_stft)) +(1J * sig_imag_masked)
掩蓋信號
#恢復signalRecovered_signal = _istft(sig_stft_amp,hop_length,win_length)rectioned_spec = _amp_to_db(np.abs(_stft(_STFT(recuceed_signal,n_fft,n_fft,n_fft,hop_length,hop_length,win_length))
)恢復信號
因此,如果信號高於閾值,則施加掩碼
用平滑過濾器捲動面具
為已經下載的WAV文件應用降噪算法。
在音頻信號的實時記錄上應用FFT。
進一步更深入地實施了AI的消除噪聲。
將降噪算法應用於各種形式的音頻文件。
帶有麥克風和ESP32的實時音頻信號,因此將獲取WAV文件以進行進一步的計算和信號處理。
Dhriti Mabian
Priyal Awankar
*SRA vjti_eklavya 2021
Shreyas Atre
苛刻的沙阿
大膽
降噪方法
從馬丁·亨氏(Martin Heinz)拿起樣板
蒂姆·塞恩堡
執照


