ainovelprompter
1.0.0
AI新穎的提示者可以根據用戶指定特徵為小說生成寫作提示。
AI Novel Novel Propter是一個桌面應用程序,旨在幫助作家為Chatgpt和Claude等人工智能寫作助理創建一致且結構良好的提示。該工具有助於管理故事元素,角色細節,並生成正確格式的提示,以繼續您的小說。
可執行文件在構建/bin上可執行
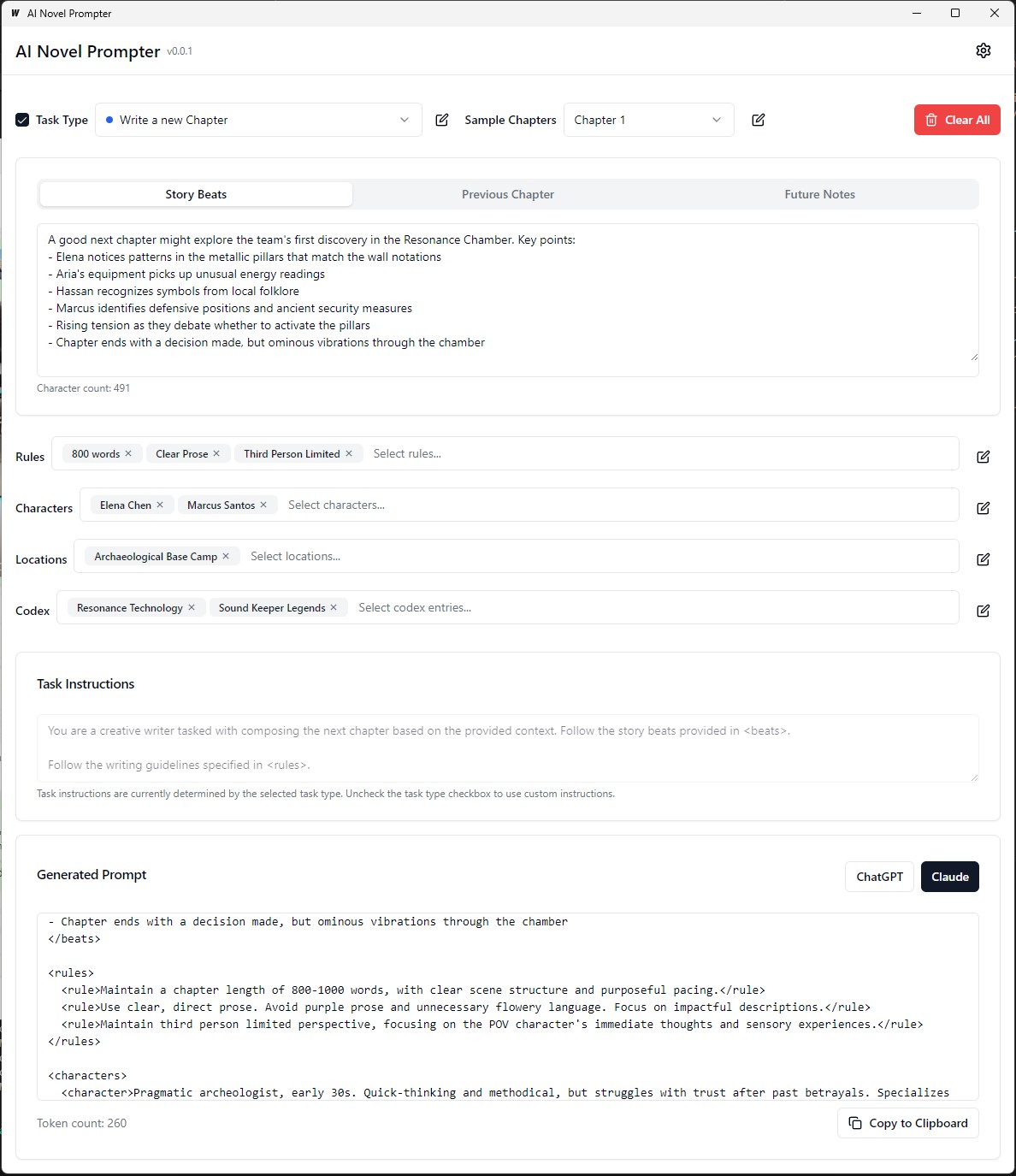
每個類別都可以在不同的提示中進行編輯,保存和重複使用:
前端:
後端:
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev要構建可重新分配的生產模式包,請使用wails build 。
wails build可執行文件在構建/bin上可執行
或以:
wails build -nsis可以為Mac完成此指南的最新部分
構建應用程序將在build目錄中可用。
初始設置:
創建一個提示:
生成輸出:
在運行應用程序之前,請確保已安裝以下內容:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
導航到server目錄:
cd server
安裝GO依賴性:
go mod download
使用您的數據庫配置更新config.yaml文件。
運行數據庫遷移:
go run cmd/main.go migrate
啟動後端服務器:
go run cmd/main.go
導航到client端目錄:
cd ../client
安裝前端依賴性:
npm install
啟動前端開發服務器:
npm start
http://localhost:3000訪問應用程序。 git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
使用您的數據庫配置更新docker-compose.yml文件。
使用Docker組成啟動應用程序:
docker-compose up -d
http://localhost:3000訪問應用程序。 server/config.yaml文件中修改後端配置。client/src/config.ts文件中修改前端配置。 要構建生產前端,請在client目錄中運行以下命令:
npm run build
可以在client/build目錄中生成生產的文件。
該小指南提供了有關如何在Linux(WSL)的Windows子系統上安裝PostgreSQL的說明,以及管理用戶權限並解決常見問題的步驟。
打開WSL終端:啟動您的WSL發行版(建議使用Ubuntu)。
更新軟件包:
sudo apt update安裝PostgreSQL :
sudo apt install postgresql postgresql-contrib檢查安裝:
psql --version設置PostgreSQL用戶密碼:
sudo passwd postgres創建數據庫:
createdb mydb訪問數據庫:
psql mydb來自SQL文件的導入表:
psql -U postgres -q mydb < /path/to/file.sql列出數據庫和表:
l # List databases
dt # List tables in the current database開關數據庫:
c dbname創建新用戶:
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;授予特權:
ALTER USER your_db_user CREATEDB;角色不存在錯誤:切換到“ Postgres”用戶:
sudo -i -u postgres
createdb your_db_name拒絕創建擴展名的權限:登錄為'Postgres'並執行:
CREATE EXTENSION IF NOT EXISTS pg_trgm;未知用戶錯誤:確保您使用已識別的系統用戶或正確地涉及SQL環境中的PostgreSQL用戶,而不是通過sudo 。
為了生成自定義培訓數據,以微調語言模型來模仿喬治·麥克唐納(George MacDonald)的寫作風格,該過程始於Gutenberg Project Gutenberg的一部小說“公主和哥布林”的全文。然後,使用提示提示將文本分解為單個故事節奏或關鍵時刻,該提示指示AI為每個節拍生成一個JSON對象,捕獲作者,情感語氣,寫作類型和實際文本摘錄。
接下來,GPT-4用於用自己的文字重寫每個故事節拍,從而生成一組帶有唯一標識符的JSON數據,將每個重寫的節拍鏈接到其原始對應物。為了簡化數據並使其對訓練更有用,使用Python功能將各種情感色調映射到較小的核心音調。然後使用兩個JSON文件(原始和重寫的節拍)來生成訓練提示,在此要求該模型以原始作者的樣式重新繪製GPT-4生成的文本。最後,將這些提示及其目標輸出格式化為JSONL和JSON文件,準備用於微調語言模型以捕獲MacDonald的獨特寫作樣式。
在上一個示例中,使用語言模型生成解釋文本的過程涉及一些手動任務。用戶必須手動提供輸入文本,運行腳本,然後查看生成的輸出以確保其質量。如果輸出不符合所需的標準,則用戶將需要手動用不同的參數重試生成過程或對輸入文本進行調整。
但是,隨著process_text_file函數的更新版本,整個過程已完全自動化。該函數需要讀取輸入文本文件,將其分成段落,並自動將每個段落髮送到語言模型以進行釋義。它結合了各種檢查和重試機制,以處理生成的輸出不符合指定標準的情況,例如包含不必要的短語,太短或太長或由多個段落組成。
自動化過程包括幾個關鍵功能:
從最後一個處理的段落恢復:如果腳本被中斷或需要多次運行,它將自動檢查輸出文件並從最後一段成功地解釋段落中恢復處理。這樣可以確保進步不會丟失,並且腳本可以在其停止的位置接收。
帶有隨機種子和溫度的重試機制:如果生成的釋義無法滿足指定的標準,則腳本將自動將生成過程檢驗到指定的次數。每次重試時,它會隨機更改種子和溫度值以引入生成的響應中的變化,從而增加了獲得令人滿意的輸出的機會。
進度保存:腳本將進度保存到輸出文件中,每個指定的段落數(例如,每500段)。如果在處理大型文本文件期間發生任何中斷或錯誤的情況下,這種防止數據丟失。
詳細的日誌記錄和摘要:腳本提供詳細的日誌記錄信息,包括輸入段落,生成的輸出,重試嘗試以及失敗的原因。它還在結尾產生了一個摘要,顯示了段落的總數,成功的段落,跳過段落以及回程總數。
為了生成ORPO自定義培訓數據,以微調語言模型,以模仿喬治·麥克唐納(George MacDonald)的寫作風格。
輸入數據應為JSONL格式,每行包含一個包括提示和選擇響應的JSON對象。 (從上一個微調)要使用腳本,您需要使用API鍵設置OpenAI客戶端並指定輸入和輸出文件路徑。運行腳本將處理JSONL文件並生成一個帶有提示,選擇響應和生成的拒絕響應的CSV文件。腳本可以節省每100行的進度,並且可以在中斷的情況下恢復到關閉的位置。完成後,它提供了處理的總線路,書麵線,跳過線條和重試詳細信息的摘要。
數據集質量重要:95%的結果取決於數據集質量。乾淨的數據集是必不可少的,因為即使有一點糟糕的數據也會損害模型。
手動數據審查:清潔和評估數據集可以大大改善模型。這是一個耗時但必要的步驟,因為沒有任何參數調整可以修復有缺陷的數據集。
訓練參數不應改善,而應防止模型降解。在強大的數據集中,目標應該是在指導模型時避免負面影響。沒有最佳的學習率。
模型尺度和硬件限制:較大的型號(33B參數)可能會啟用更好的微調,但至少需要48GB VRAM,這使得它們在大多數家庭設置中都不切實際。
梯度積累和批處理大小:梯度積累有助於通過增強不同數據集的概括來減少過度擬合,但是幾批後它可能會降低質量。
與調整良好的模型相比,數據集的大小對於微調基本模型更為重要。超負荷具有過多的數據,可能會降低其先前的微調。
理想的學習率時間表從熱身階段開始,保持穩定,以使一個時代穩定,然後使用餘弦時間表逐漸減少。
模型等級和概括:可訓練參數的數量會影響模型的細節和概括。較低的模型可以更好地推廣但丟失細節。
LORA的適用性:參數有效的微調(PEFT)適用於大型語言模型(LLMS)和諸如穩定擴散(SD)之類的系統,證明其多功能性。
Unsploth社區幫助解決了Finetuning Llama3的幾個問題。以下是要記住的一些關鍵點:
雙BOS令牌:固定期間的雙BOS令牌可能會破壞東西。 Unsploth會自動解決此問題。
GGUF轉換:GGUF轉換被打破。小心雙BOS,然後使用CPU代替GPU進行轉換。 Unsploth具有內置的自動GGUF轉換。
故障基礎重量:Llama 3的某些基數(不是指令)的權重為“ buggy”(未訓練): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> 。這可能會導致NAN和越野車結果。不絨布會自動修復此問題。
系統提示:根據Unsploth社區的說法,添加系統提示可以使指示版本(可能是基本版本)更好。
量化問題:量化問題很常見。請參閱此比較,表明您可以通過Llama3獲得良好的性能,但是使用錯誤的量化會損害性能。要進行填充,請使用BitsandBytes NF4提高準確性。對於GGUF,請盡可能使用i版本。
長上下文模型:長上下文模型受過良好的訓練。他們只是將繩索伸展,有時沒有任何培訓,然後在怪異的串聯數據集上訓練以使其成為長數據集。這種方法無法正常工作。如果從8K到1M上下文長度縮放,則平穩,連續的長上下文縮放會更好。
為了解決其中一些問題,請使用不塞來進行固定的乳白色3。
在微調以作者風格釋義的語言模型時,評估產生的釋義的質量和有效性很重要。
以下評估指標可用於評估模型的性能:
BLEU(雙語評估研究):
sacrebleu庫。from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge(以召回的研究為目標評估):
rouge庫。from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)困惑:
perplexity = model.perplexity(generated_paraphrases)造型測量指標:
stylometry學庫。from stylometry import extract_features; features = extract_features(generated_paraphrases)要將這些評估指標集成到您的Axolotl管道中,請執行以下步驟:
通過創建目標作者作品的段落數據集並將其分為培訓和驗證集來準備培訓數據。
按照前面討論的方法,使用培訓集對您的語言模型進行微調。
使用微型模型為驗證集中的段落生成釋義。
使用相應的庫( sacrebleu , rouge , stylometry )實現評估指標,併計算每個生成的釋義的分數。
通過收集人類評估者的評分和反饋來進行人類評估。
分析評估結果,以評估產生的釋義的質量和样式,並做出明智的決定以改善您的微調過程。
這是如何將這些指標集成到管道中的示例:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )請記住要安裝必要的庫(Sacrebleu,Rouge,樣式測定法),並調整代碼以適合您的Axolotl或類似實現。
在此實驗中,我探討了各種AI模型之間根據詳細提示生成1500字文本的功能和差異。我從https://chat.lmsys.org/,Chatgpt4,Claude 3 Opus和LM Studio中的一些本地型號測試了模型。每個模型都生成文本三次,以觀察其輸出的可變性。我還創建了一個單獨的提示,以評估每個模型的第一次迭代的寫作,並詢問Chatgpt 4和Claude Opus 3提供反饋。
通過此過程,我觀察到某些模型在執行之間表現出更高的可變性,而另一些模型傾向於使用相似的措辭。每種模型產生的單詞數量以及對話,描述和段落的數量也存在顯著差異。評估反饋表明,Chatgpt提出了更“精緻”的散文,而Claude建議較少的紫色散文。根據這些發現,我編制了一系列外賣列表,以將其納入下一個提示中,重點介紹精確的,多樣化的句子結構,強大的動詞,獨特的幻想,幻想主題,一致的語氣,獨特的敘述者聲音和引人入勝的節奏。要考慮的另一種技術是尋求反饋,然後根據反饋重寫文本。
我願意與他人合作,以進一步調整每個模型的提示,並探索他們在創意寫作任務中的能力。
模型具有固有的格式偏差。有些型號更喜歡列表的連字符,而另一些則喜歡星號。使用這些模型時,有助於反映其偏好以獲得一致的輸出。
格式傾向:
Llama 3更喜歡用大膽的標題和星號列表。
示例:大膽的標題案例標題
在兩個新線後列出帶有星號的項目
列出由一個newline隔開的項目
下一個列表
更多列表項目
ETC...
幾個示例:
系統及時依從性:
上下文窗口:
審查制度:
智力:
一致性:
列表和格式:
聊天設置:
管道設置:
Llama 3具有靈活且聰明,但具有上下文和引用局限性。相應地調整提示方法。
歡迎所有評論。如果您找到任何錯誤或有改進的建議,請打開問題或發送拉請請求。
該項目的許可在:屬性- 非商業- 諾迪德劑(by-nc-nd)許可證中,請參見:https://creativecommons.org/licenses/by-nc-nc-nc-nd/4.0 /deed.en


