paper2slides
1.0.0
使用大型語言模型(LLM)將任何Arxiv論文轉換為幻燈片!該工具對於快速掌握研究論文的主要思想很有用。
產生的幻燈片的一些例子是:Word2Vec,gan,變壓器,VIT,經過思考鏈,Star,DPO和AI科學家。在演示中查看許多其他生成幻燈片的示例。
該腳本將從Internet(ARXIV)下載文件,將信息發送到OpenAI API,然後在本地進行編譯。請謹慎對待所共享的內容和潛在風險。如果您有您感興趣的特定ARXIV ID,並且不想自己運行代碼,請在“討論”中告訴我,我很樂意將幻燈片添加到演示列表中。
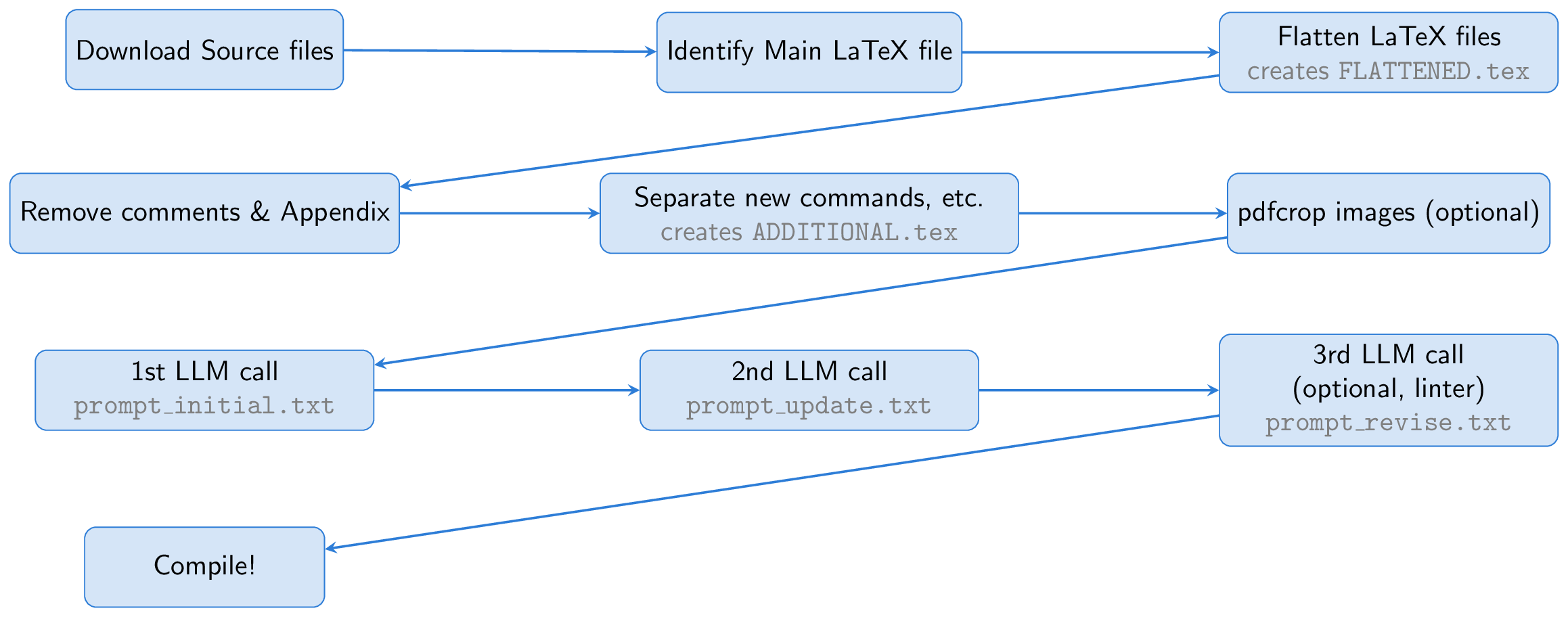
該過程首先下載Arxiv紙的源文件。識別並扁平的主乳膠文件,將所有輸入文件合併到一個文檔中( FLATTENED.tex )。我們通過刪除註釋和附錄來預處理此合併文件。此預處理文件以及創建良好幻燈片的說明構成了我們提示的基礎。
一個關鍵的想法是將Beamer用於幻燈片創建,從而使我們完全留在乳膠生態系統中。這種方法本質上將任務變成了摘要練習:將長乳膠紙轉換為簡潔的束乳膠。 LLM可以從字幕中推斷數字的內容,並將其包括在幻燈片中,從而消除了對視覺功能的需求。
為了幫助LLM,我們創建了一個名為ADDITIONAL.tex的文件,其中包含所有必要的軟件包, newCommand定義以及本文中使用的其他乳膠設置。在提示符中包含input{ADDITIONAL.tex}的該文件會縮短其並使生成幻燈片更可靠,尤其是對於具有許多自定義命令的理論論文。
LLM從乳膠源生成Beamer代碼,但是由於第一次運行可能會出現問題,因此我們要求LLM自我了解和完善輸出。選擇的是,第三步涉及使用Linter檢查生成的代碼,結果將結果饋回LLM進行進一步的校正(此linter步驟是受AI科學家的啟發)。最後,使用PDFLATEX將Beamer代碼彙編為PDF表示。
all.zsh腳本可以自動化整個過程,通常在不到幾分鐘的時間內使用GPT-4O完成一張紙。
要求是:
requests庫arxiv庫openai圖書館arxiv-latex-cleaner庫pdflatex的工作安裝安裝步驟:
克隆這個存儲庫:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slides安裝所需的Python軟件包:
pip install requests arxiv openai arxiv-latex-cleaner確保安裝pdflatex並在系統路徑中可用。 (可選)檢查是否可以通過pdflatex test.tex編譯樣品test.tex 。檢查test.pdf是否正確。可選地檢查chktex和pdfcrop正在工作。
設置您的OpenAI API密鑰:
export OPENAI_API_KEY= ' your-api-key ' all.sh腳本該腳本可自動下載Arxiv紙,處理並將其轉換為Beamer演示文稿的過程。
bash all.sh < arxiv_id >用所需的Arxiv紙張ID替換<arxiv_id> 。可以從URL識別ID: https://arxiv.org/abs/xxxx.xxxx的ID是xxxx.xxxx 。
您還可以單獨運行Python腳本以獲得更多控制。
下載並處理Arxiv源文件
python arxiv2tex.py < arxiv_id >該腳本下載指定的Arxiv紙的源文件,提取它們,然後處理主乳膠文件。結果將保存在source/<arxiv_id>/FLATTENED.tex和source/<arxiv_id>/ADDITIONAL.tex中。
將乳膠轉換為Beamer
python tex2beamer.py --arxiv_id < arxiv_id >該腳本讀取已處理的乳膠文件並準備Beamer幻燈片。這是我們使用OpenAI API的地方。我們撥打兩次,首先生成Beamer代碼,然後自我了解Beamer代碼。 (可選)使用以下標誌: --use_linter和--use_pdfcrop 。發送到LLM的提示將保存在tex2beamer.log中。 Linter日誌將保存在source/<arxiv_id>/linter.log中。
將Beamer轉換為PDF
python beamer2pdf.py < arxiv_id >該腳本將Beamer文件編譯為PDF演示文稿。
提示將保存在prompt_initial.txt , prompt_update.txt和prompt_revise.txt中,但隨時可以根據您的需求進行調整。它們包含一個稱為佔位符的佔位PLACEHOLDER_FOR_FIGURE_PATHS 。這將被紙張中使用的圖路徑替換。我們要確保路徑在Beamer代碼中正確使用。 LLM通常會犯錯誤,因此我們將其明確包含在提示中。
成功率在我的經驗中約為90%(編譯可能失敗或圖像路徑在某些情況下可能是錯誤的)。如果您遇到任何問題或有任何改進建議,請隨時讓我知道!


