descript audio codec
1.0.0
該存儲庫包含描述音頻編解碼器(.DAC)的培訓和推理腳本,這是一個高保真一般的神經音頻編解碼器,在題為“高保真音頻壓縮”的論文中介紹了改進的RVQGAN 。
ARXIV紙:高保真音頻壓縮,改進了RVQGAN
?演示網站
⚙模型權重
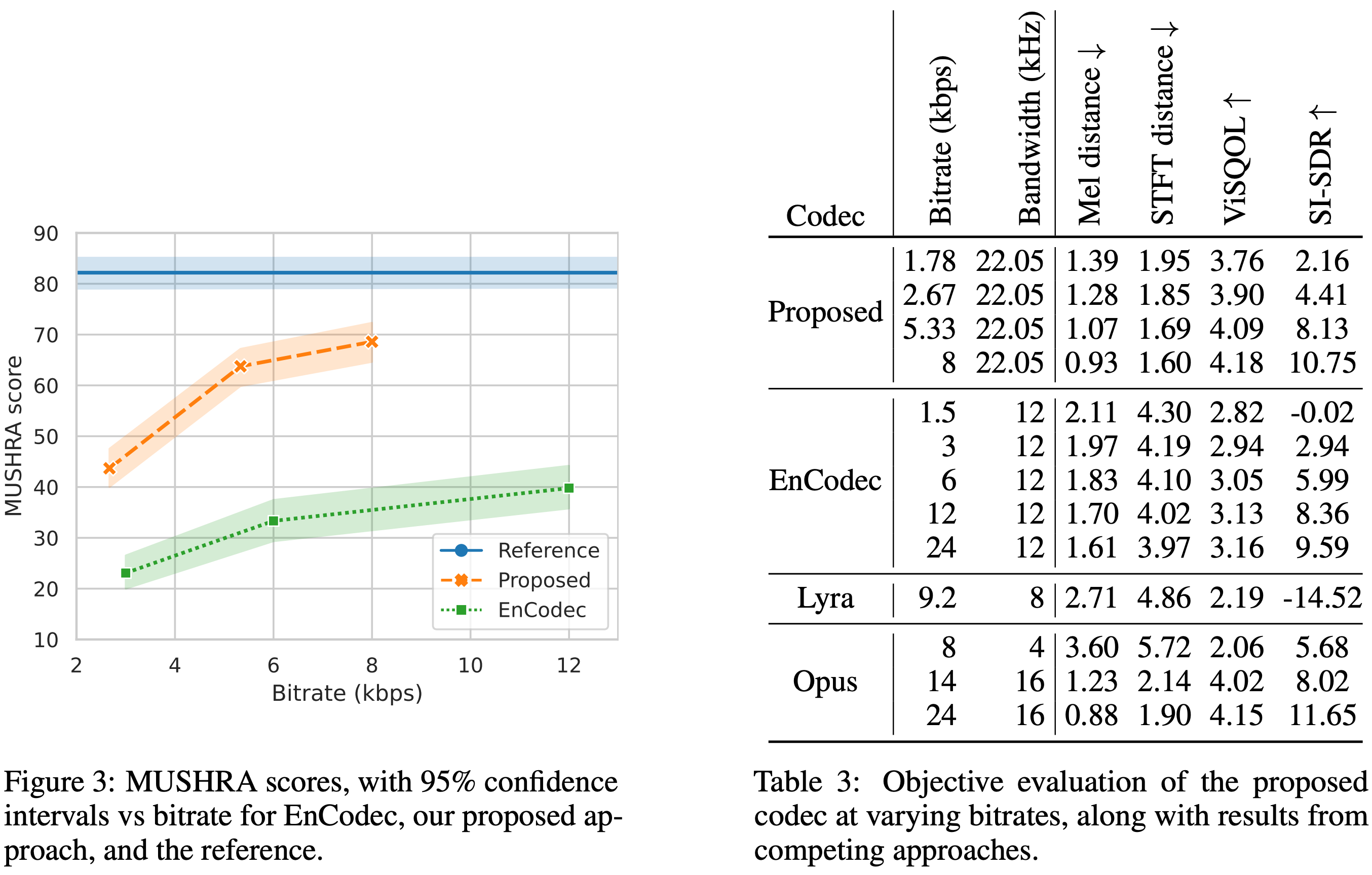
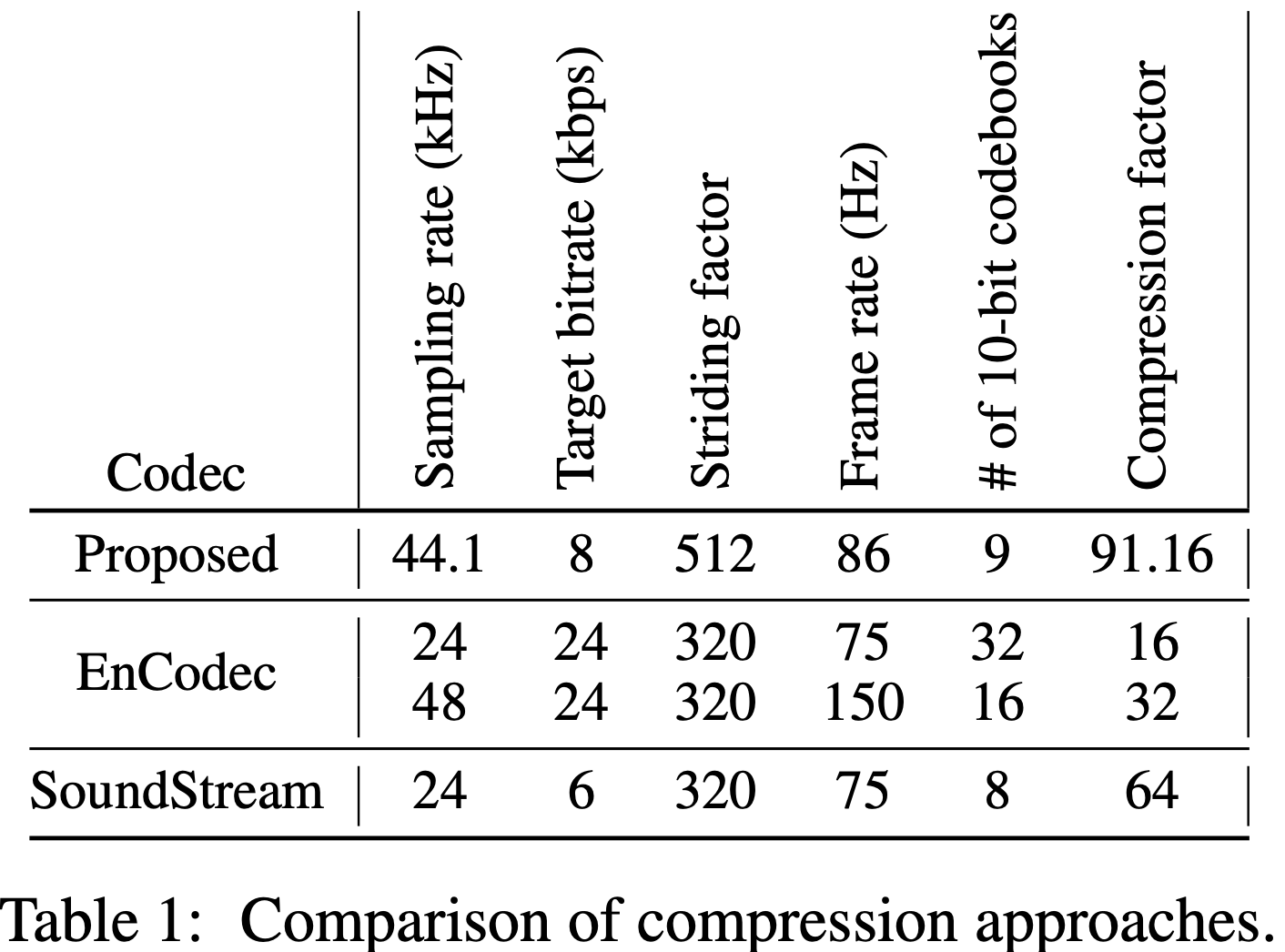
使用描述音頻編解碼器,您可以將44.1 kHz音頻壓縮為8 kbps比特率的離散代碼。
?這是約90倍的壓縮,同時保持出色的保真度並最大程度地減少偽像。
?我們的通用模型在所有域(語音,環境,音樂等)上都起作用,使其廣泛適用於所有音頻的生成建模。
?它可以用作所有音頻語言建模應用程序(例如Audiolms,Musiclms,Musicgen等)的concodec的替換。
pip install descript-audio-codec
或者
pip install git+https://github.com/descriptinc/descript-audio-codec
根據MIT許可證,權重作為此存儲庫的一部分發布。我們釋放可以原始支持16 kHz,24kHz和44.1kHz採樣率的模型的權重。首次運行encode或decode命令時,權重自動下載。您可以使用以下命令之一來緩存它們
python3 -m dac download # downloads the default 44kHz variant
python3 -m dac download --model_type 44khz # downloads the 44kHz variant
python3 -m dac download --model_type 24khz # downloads the 24kHz variant
python3 -m dac download --model_type 16khz # downloads the 16kHz variant我們提供了一個碼頭文件,該碼頭安裝了所有必需的依賴項,以編碼和解碼。構建過程緩存了圖像內部的默認模型權重。這允許在沒有Internet連接的情況下使用圖像。請參閱下面的說明。
python3 -m dac encode /path/to/input --output /path/to/output/codes
此命令將創建具有與輸入文件相同名稱的.dac文件。它還將保留相對於輸入根目錄結構並將其重新創建在輸出目錄中。請使用python -m dac encode --help以獲取更多選項。
python3 -m dac decode /path/to/output/codes --output /path/to/reconstructed_input
此命令將創建與輸入文件相同名稱的.wav文件。它還將保留相對於輸入根目錄結構並將其重新創建在輸出目錄中。請使用python -m dac decode --help以獲取更多選項。
import dac
from audiotools import AudioSignal
# Download a model
model_path = dac . utils . download ( model_type = "44khz" )
model = dac . DAC . load ( model_path )
model . to ( 'cuda' )
# Load audio signal file
signal = AudioSignal ( 'input.wav' )
# Encode audio signal as one long file
# (may run out of GPU memory on long files)
signal . to ( model . device )
x = model . preprocess ( signal . audio_data , signal . sample_rate )
z , codes , latents , _ , _ = model . encode ( x )
# Decode audio signal
y = model . decode ( z )
# Alternatively, use the `compress` and `decompress` functions
# to compress long files.
signal = signal . cpu ()
x = model . compress ( signal )
# Save and load to and from disk
x . save ( "compressed.dac" )
x = dac . DACFile . load ( "compressed.dac" )
# Decompress it back to an AudioSignal
y = model . decompress ( x )
# Write to file
y . write ( 'output.wav' )我們提供一個Dockerfile來構建具有所有必要依賴性的Docker映像。
構建圖像。
docker build -t dac .
使用圖像。
在CPU上使用:
docker run dac <command>
在GPU上使用:
docker run --gpus=all dac <command>
<command>可以是上面列出的壓縮和重建命令之一。例如,如果要運行壓縮,
docker run --gpus=all dac python3 -m dac encode ...
可以使用以下命令對基線模型配置進行訓練。
請安裝正確的依賴項
pip install -e ".[dev]"
我們提供了一個Dockerfile和Docker組成的設置,使運行實驗變得容易。
構建Docker映像確實:
docker compose build
然後,要啟動一個容器,請:
docker compose run -p 8888:8888 -p 6006:6006 dev
端口參數( -p )是可選的,但如果要在容器中啟動jupyter和張板實例,則有用。 jupyter的默認密碼是password ,並且當前目錄已安裝到/u/home/src ,這也成為工作目錄。
然後,運行您的培訓命令。
export CUDA_VISIBLE_DEVICES=0
python scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
export CUDA_VISIBLE_DEVICES=0,1
torchrun --nproc_per_node gpu scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
我們提供兩個測試腳本來測試CLI +培訓功能。在啟動這些測試之前,請確保滿足Trainig先決條件。要啟動這些測試,請運行
python -m pytest tests