rl 6 nimmt
1.0.0
6 nimmt!是一款屢獲殊榮的紙牌遊戲,適用於1994年的兩到十名球員。引用Wikipedia:
該遊戲有104張卡片,每張牌都有一個數字和一到七個公牛的頭符號,代表罰球點。一輪十回合,所有玩家都將他們選擇的一張卡放在桌子上。根據固定規則將放置的卡片排列在四行上。如果放置在已經擁有五張牌的行上,那麼玩家將收到這五張牌,這是在回合結束時總計上的罰球點。
6 nimmt!是一款不完整的信息和大量隨機性的競爭遊戲。表現良好需要相當多的計劃。同時的遊戲表現出色,使自己想到遊戲和虛張聲勢,而某些長期策略對於避免最終處於困難的最終比賽位置是必要的。
我們實施了6個NIMMT的簡化版本!作為Openai健身環境。與原始遊戲不同的是,在所有堆棧上玩的卡低於最後一張卡時,玩家無法自由選擇要替換哪種堆棧,而是總是以最小的罰款點佔用堆棧。
到目前為止,我們已經實施了以下代理:
作為第一次測試,我們進行了一個簡單的自我比賽。從五個未經訓練的代理商開始,我們總共打了4000場比賽。對於每個遊戲,我們隨機選擇兩個,三個或四個代理商進行遊戲(和學習)。每400場比賽我們都會克隆出表現最好的代理商,並踢出了一些表現較差的球員。最後,我們只是保留了每個代理類型的最佳實例。
在所有遊戲中的結果:
| 代理人 | 玩遊戲 | 平均分數 | 贏得分數 | Elo |
|---|---|---|---|---|
| alpha0.5 | 2246 | -7.79 | 0.42 | 1806年 |
| MCS | 2314 | -8.06 | 0.40 | 1745年 |
| 宏cer | 1408 | -12.28 | 0.18 | 1629年 |
| D3QN | 1151 | -13.32 | 0.17 | 1577年 |
| 隨機的 | 1382 | -13.49 | 0.19 | 1556年 |
這就是如何在比賽過程中開發的模型的性能(以ELO的測量):
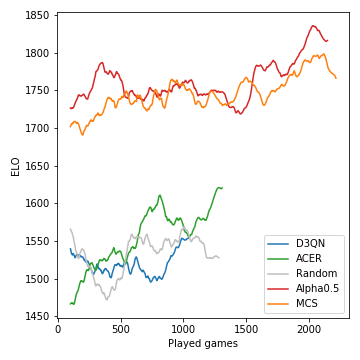
蒙特卡洛樹搜索至關重要,並導致了強大的玩家。另一方面,無模型的RL代理甚至努力清楚地表現出隨機基線的表現。由於遊戲的隨機性質,贏得概率和ELO差異並不像國際象棋那樣激烈。請注意,我們沒有調整許多超參數。
在這個自我播放階段之後,Alpha0.5代理人面對Merle,這是最好的6個NIMMT之一!我們小組的朋友參加了5場比賽。這些是分數:
| 遊戲 | 1 | 2 | 3 | 4 | 5 | 和 |
|---|---|---|---|---|---|---|
| 梅爾 | -10 | -16 | -11 | -3 | -4 | -44 |
| alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
假設您安裝了Anaconda,請與
git clone [email protected]:johannbrehmer/rl-6nimmt.git
並用
conda env create -f environment.yml
conda activate rl
simple_tournament.ipynb都展示了人類玩家和受過訓練的代理商之間的代理人自我玩法和遊戲。
由約翰·布雷默(Johann Brehmer)和馬塞爾·古施(Marcel Gutsche)組合在一起。


