OneForAll
1.0.0
論文:https://arxiv.org/abs/2310.00149
作者:Hao Liu,Jiarui Feng,Lecheng Kong,Ningyue Liang,Dacheng Tao,Yixin Chen,Muhan Zhang
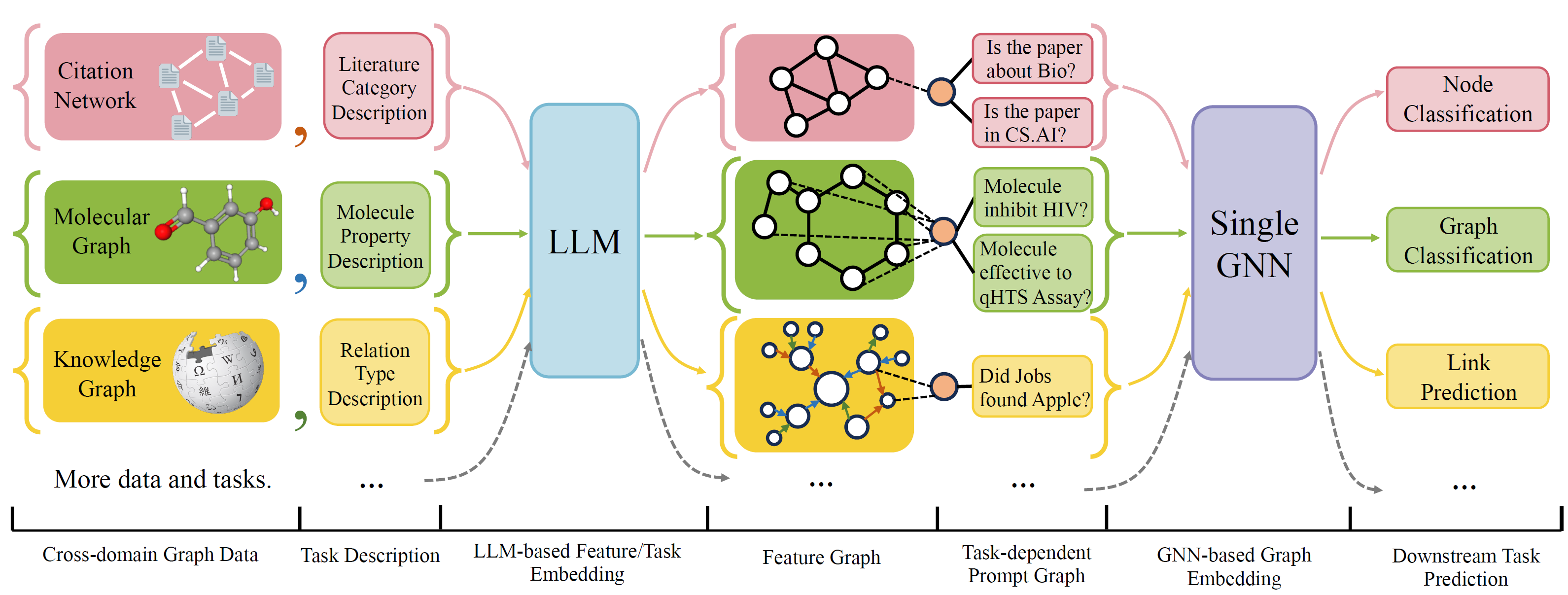
OFA是一個通用的圖形分類框架,可以使用單個模型和一組參數來解決廣泛的圖形分類任務。這些任務是跨域(例如引用網絡,分子圖,...)和交叉任務(例如,幾次,零射擊,圖形級,節點 - leve,...)
OFA使用自然語言來描述所有圖形,並使用LLM將所有描述嵌入相同的嵌入空間中,從而可以使用單個模型來實現跨域訓練。
OFA提出了一個提示的Paradiagm,將所有任務信息轉換為提示圖。因此,子序列模型能夠讀取任務信息並相應地預測Relavent Target,而無需調整模型參數和體系結構。因此,單個模型可以是交叉任務。
OFA策劃了來自不同源和域的圖形數據集列表,並用系統遞減協議描述了圖中的節點/邊緣。我們感謝以前的作品,包括OGB,Gimlet,Moleculenet,Graphllm和Villmow提供了精美的原始圖形/文本數據,使我們的工作成為可能。
Oneforall進行了重大修訂,我們清理了代碼並修復了幾個報告的錯誤。主要更新是:
如果您以前使用過我們的存儲庫,請拉並刪除舊生成的功能/文本文件並再生。帶來不便敬請諒解。
使用Conda安裝項目要求:
conda env create -f environment.yml
對於所有收集的數據集的聯合端到端實驗,請運行
python run_cdm.py --override e2e_all_config.yaml
所有參數都可以通過空間分離值(例如
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
用戶可以在./e2e_all_config.yaml中修改task_names變量以控制培訓期間包含哪些數據集。 task_names , d_multiple和d_min_ratio的長度應相同。也可以通過逗號分隔值在命令行參數中指定它們。
例如
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
可以通過
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
運行幾次射擊和零射實驗
python run_cdm.py --override lr_all_config.yaml
我們為每個任務定義配置,每個任務配置都包含幾個數據集配置。
任務配置存儲在./configs/task_config.yaml中。一個任務通常包括幾個數據集(不一定是同一數據集)。例如,常規的端到端CORA節點分類任務將使CORA數據集的火車拆分為火車數據集,CORA數據集的有效拆分是有效的數據集之一,同樣對於測試拆分。您還可以通過將CORA的火車分配為驗證/測試數據集之一來獲得更多的驗證/測試。具體來說,任務配置看起來像
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split數據集配置存儲在./configs/task_config.yaml中。數據集配置定義了數據集的構建方式。具體來說,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 如果您正在實現Cora/PubMed/arxiv之類的數據集,我們建議在Data/single_graph/$ customized_data $下添加數據$ customized_data $的目錄,並在目錄下實現gen_data.py,您可以使用data/cora/ gen_data。 PY作為一個例子。
構造數據後,您需要在此處註冊數據集名稱,並在此處實現分離器。如果您要執行零射擊/少量射擊任務,則也可以在此處構造零擊/幾次拆分。
最後,在configs/data_config.yaml中註冊配置條目。例如,用於端到端節點分類
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$process_label_func將目標標籤轉換為二進制標籤,並轉換類嵌入,如果任務為零/少數射擊,則無法修復類節點的數量。 Avalailable Process_label_func的列表在這裡。它需要所有類嵌入和正確的標籤。輸出是一個元組:(標籤,class_node_embedding,二進制/單速標籤)。
如果您想要更高的靈活性,那麼添加自定義數據集需要實現ofapygdataset的自定義子類。一個模板在這裡:
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

