rlcard
RLCard 1.0.7
中文文檔
RLCARD是紙牌遊戲中加固學習(RL)的工具包。它支持多個卡環境,並具有易於使用的接口,用於實現各種強化學習和搜索算法。 RLCARD的目標是橋接加強學習和不完美的信息遊戲。 RLCARD由賴斯和德克薩斯A&M大學的數據實驗室和社區貢獻者開發。
社區:
消息:
以下游戲主要由社區貢獻者開發和維護。謝謝你!
感謝所有貢獻者!




























如果您發現此倉庫有用,則可以引用:
Zha,Daochen等。 “ RLCARD:紙牌遊戲中加固學習的平台。” ijcai。 2020。
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
}確保您的Python 3.6+並安裝了PIP 。我們建議使用pip安裝穩定版本的rlcard :
pip3 install rlcard
默認安裝僅包括卡環境。要使用培訓算法的Pytorch實現,請運行
pip3 install rlcard[torch]
如果您在中國,上面的命令太慢,則可以使用Tsinghua University提供的鏡子:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
另外,您可以與最新版本一起使用(如果您在中國,而Github很慢,則可以在Gitee中使用鏡子):
git clone https://github.com/datamllab/rlcard.git
或僅克隆一個分支以使其更快:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
然後安裝
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
我們還提供Conda安裝方法:
conda install -c toubun rlcard
Conda安裝僅提供卡環境,您需要根據需求手動安裝Pytorch。
一個簡短的例子如下。
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCARD可以靈活地連接到各種算法。請參閱以下示例:
運行examples/human/leduc_holdem_human.py播放預先訓練的leduc Hold'em模型。 Leduc Hold'em是德克薩斯州Hold'em的簡化版本。規則可以在這裡找到。
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
我們還提供了一個輕鬆調試的GUI。請在這裡檢查。一些演示:
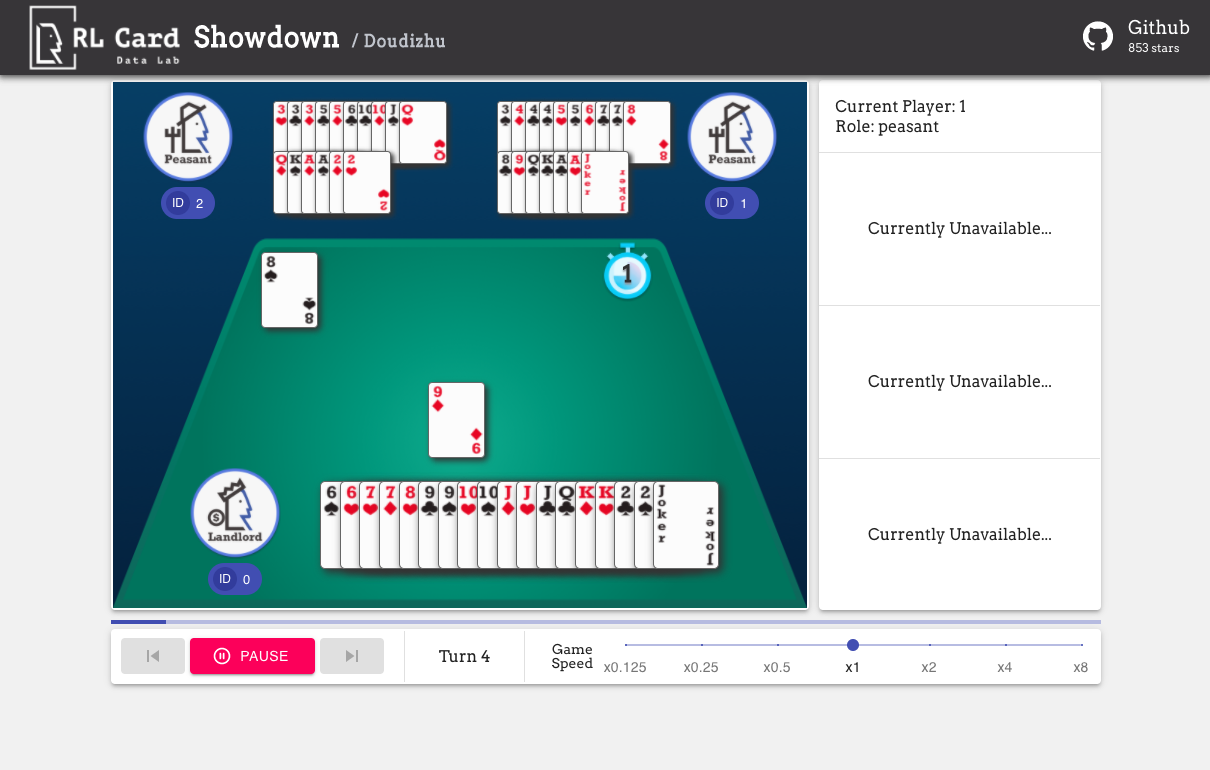
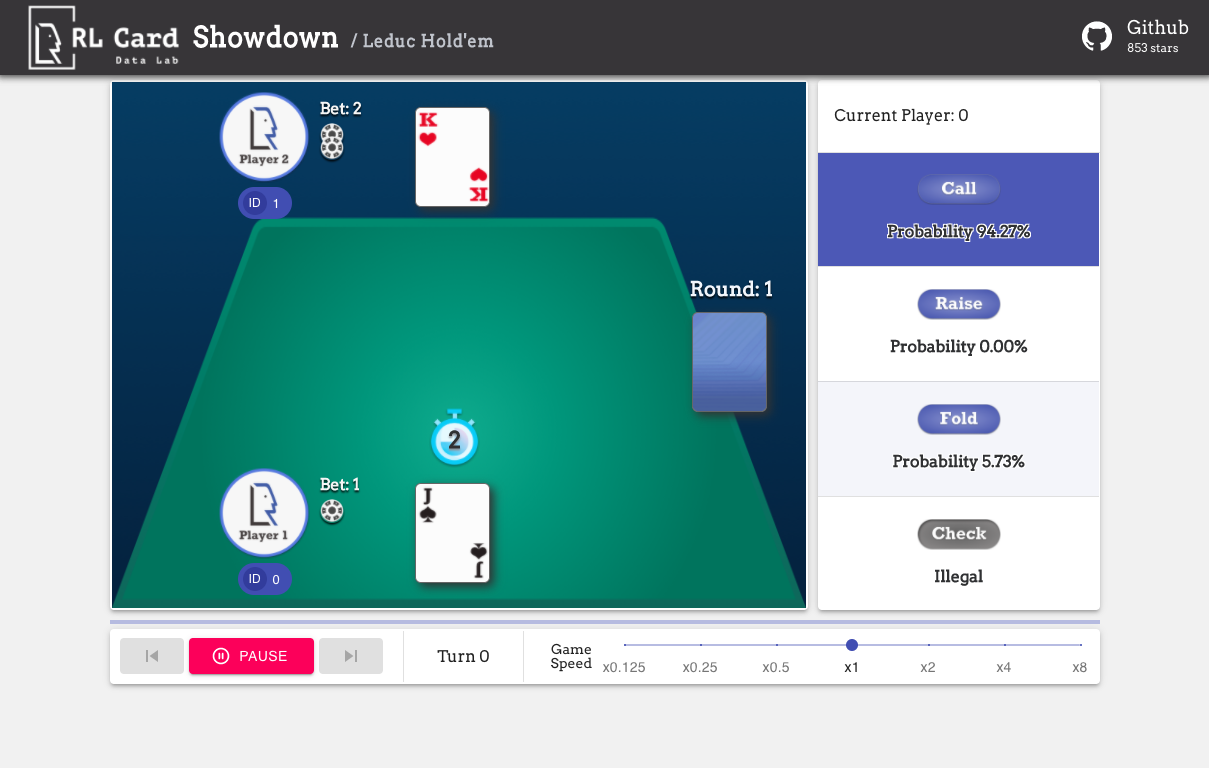
我們在幾個方面為遊戲提供了複雜的估計。 Infoset編號:信息集的數量;信息集大小:單個信息集中的平均狀態數;動作大小:動作空間的大小。名稱:應該傳遞給rlcard.make創建遊戲環境的名稱。我們還提供了指向文檔和隨機示例的鏈接。
| 遊戲 | 信息編號 | 信息尺寸 | 動作大小 | 姓名 | 用法 |
|---|---|---|---|---|---|
| 二十一點(Wiki,Baike) | 10^3 | 10^1 | 10^0 | 二十一點 | DOC,示例 |
| Leduc Hold'em(紙) | 10^2 | 10^2 | 10^0 | Leduc-Holdem | DOC,示例 |
| 限制德克薩斯州Hold'em(Wiki,Baike) | 10^14 | 10^3 | 10^0 | 限制 | DOC,示例 |
| Dou Dizhu(Wiki,Baike) | 10^53〜10^83 | 10^23 | 10^4 | Doudizhu | DOC,示例 |
| Mahjong(Wiki,Baike) | 10^121 | 10^48 | 10^2 | 馬翁 | DOC,示例 |
| 無限制的德克薩斯州Hold'em(Wiki,Baike) | 10^162 | 10^3 | 10^4 | 無限制 | DOC,示例 |
| UNO(Wiki,Baike) | 10^163 | 10^10 | 10^1 | UNO | DOC,示例 |
| 杜松子酒(Wiki,Baike) | 10^52 | - | - | 杜松子酒 | DOC,示例 |
| 橋樑(Wiki,Baike) | - | - | 橋 | DOC,示例 |
| 演算法 | 例子 | 參考 |
|---|---|---|
| 深蒙特卡洛(DMC) | 示例/run_dmc.py | [紙] |
| 深Q學習(DQN) | 示例/run_rl.py | [紙] |
| 神經虛擬的自我遊戲(NFSP) | 示例/run_rl.py | [紙] |
| 反事實遺憾最小化(CFR) | 示例/run_cfr.py | [紙] |
我們提供模型動物園作為基準。
| 模型 | 解釋 |
|---|---|
| leduc-holdem-cfr | Leduc Hold'em上的預訓練的CFR(機會抽樣)模型 |
| leduc-holdem-rule-v1 | Leduc Holdem的基於規則的模型,V1 |
| leduc-holdem-rule-v2 | Leduc Holdem的基於規則的模型V2 |
| UNO-RULE-V1 | 基於規則的UNO模型V1 |
| 限制 - 固定-rule-v1 | 基於規則的限制德克薩斯州Hold'em的模型,V1 |
| doudizhu-rule-v1 | Dou Dizhu的基於規則的模型,V1 |
| 杜松子酒 - 刺激性 - 諾維斯規則 | 杜松子酒新手規則模型 |
您可以使用以下接口來製作環境。您可以選擇使用字典指定一些配置。
env_id是環境的字符串; config是一個詞典,它指定了某些環境配置,如下所示。seed :默認None 。設置環境局部隨機種子以重現結果。allow_step_back :默認False 。如果True step_back函數在樹中向後遍歷。game_開頭。目前,我們僅支持二十一點中的game_num_players 。一旦製作了環境,我們就可以訪問遊戲的一些信息。
狀態是Python詞典。它由觀察state['obs'] , state['legal_actions'] ,原始觀察state['raw_obs']和原始法律行動state['raw_legal_actions']組成。
以下接口提供了基本用法。它易於使用,但在代理上具有假設。代理必須遵循代理模板。
agents是Agent對象的列表。列表的長度應等於遊戲中玩家的數量。set_agents之後使用該函數。如果is_training為True ,它將在代理中使用step功能來玩遊戲。如果is_training為False ,則會調用eval_step 。對於高級用法,以下接口允許在遊戲樹上靈活操作。這些接口沒有對代理的任何假設。
action可以是原始動作或整數;如果操作是原始操作(字符串),則raw_action應該是True 。allow_step_back為True時才可用。向後一步。這可以用於在遊戲樹上運行的算法,例如CFR(Chance採樣)。True 。 otherwise,返回False 。player_id狀態。主要模塊的目的列出如下:
有關更多文檔,請參閱文檔以獲取一般介紹。 API文檔可在我們的網站上找到。
非常感謝對該項目的貢獻!請為反饋/錯誤創建問題。如果您想撰寫代碼,請參閱貢獻指南。如有任何疑問,請與Daochen Zha聯繫[email protected]。
我們要感謝JJ World Network Technology Co.,Ltd的慷慨支持和社區貢獻者的所有貢獻。


