TaskMatrix
1.0.0
يقوم TaskMatrix بتوصيل ChatGPT وسلسلة من نماذج Visual Foundation لتمكين إرسال واستقبال الصور أثناء الدردشة.
راجع مقالتنا: Visual ChatGPT: التحدث والرسم والتحرير باستخدام نماذج الأساس المرئي
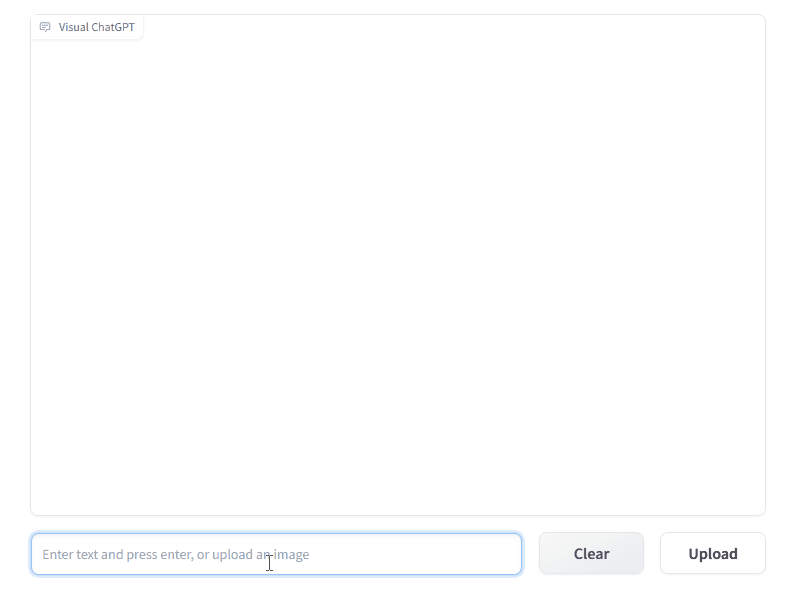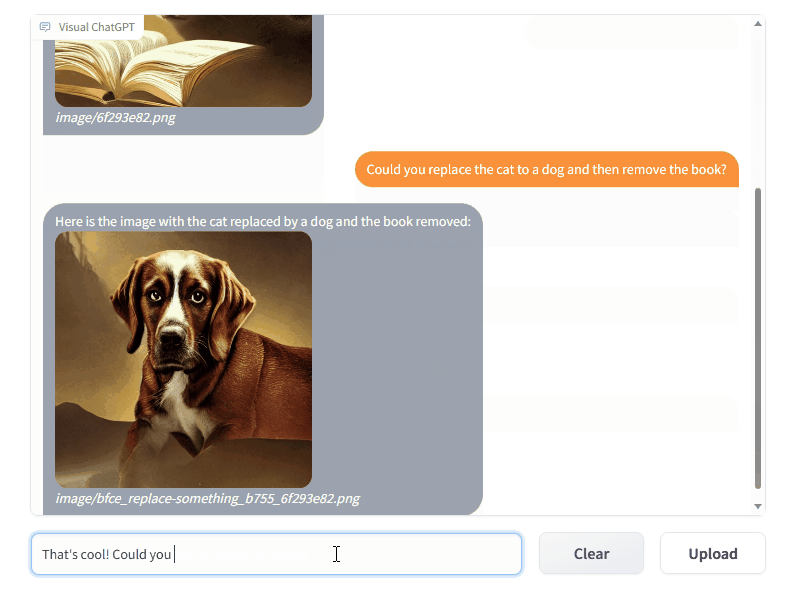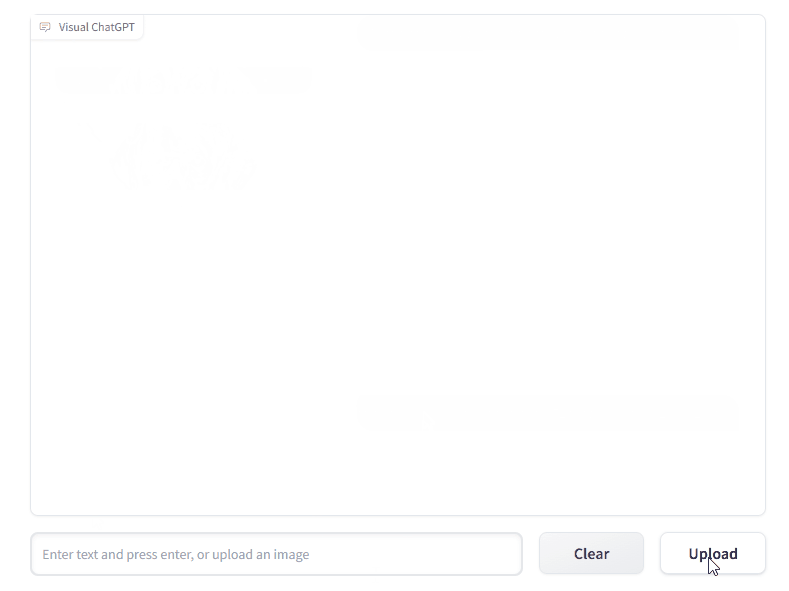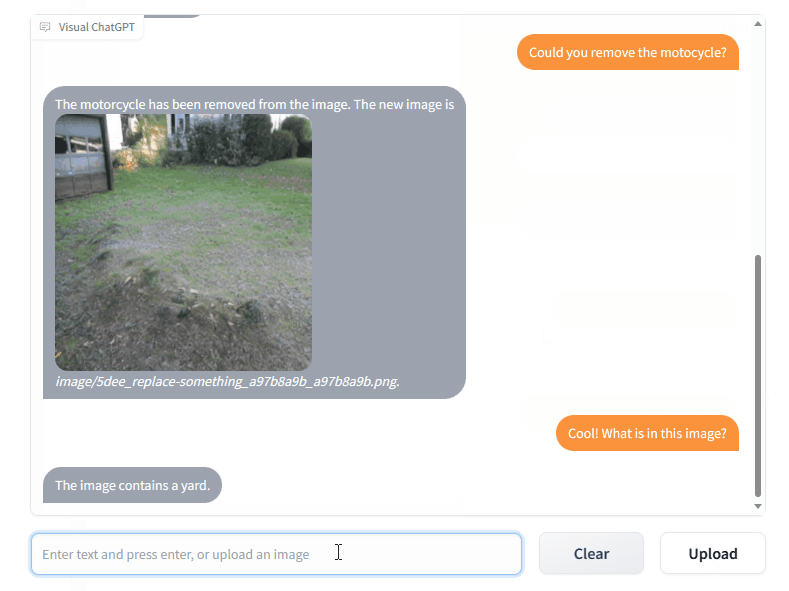
الآن تدعم TaskMatrix GroundingDINO وتقسيم أي شيء! شكرا @jordddan على جهوده. بالنسبة لحالة تحرير الصور، يتم استخدام GroundingDINO أولاً لتحديد موقع المربعات المحيطة الموجهة بواسطة نص معين، ثم يتم استخدام segment-anything لإنشاء القناع ذي الصلة، وأخيرًا يتم استخدام الانتشار المستقر في الرسم لتحرير الصورة بناءً على القناع.
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0"find xxx in the image أو segment xxx in the image . xxx هو كائن. سوف تقوم TaskMatrix بإرجاع نتيجة الكشف أو التجزئة!الآن يمكن لـ TaskMatrix دعم اللغة الصينية! شكرًا لـ @Wang-Xiaodong1899 على جهوده.
نقترح فكرة القالب في TaskMatrix!
template_model = True شكرًا لـ ShengmingYin و thebestannie لتقديم مثال لقالب في فئة InfinityOutPainting (انظر الصورة المتحركة التالية)
python visual_chatgpt.py --load "Inpainting_cuda:0,ImageCaptioning_cuda:0,VisualQuestionAnswering_cuda:0"extend the image to 2048x1024 إلى TaskMatrix!InfinityOutPainting ، يمكن لـ TaskMatrix توسيع الصور بسلاسة إلى أي حجم من خلال التعاون مع نماذج ImageCaptioning و Inpainting و VisualQuestionAnswering الحالية، دون الحاجة إلى تدريب إضافي .TaskMatrix يحتاج إلى جهد المجتمع! نحن نتطلع إلى مساهمتك لإضافة ميزات جديدة ومثيرة للاهتمام!

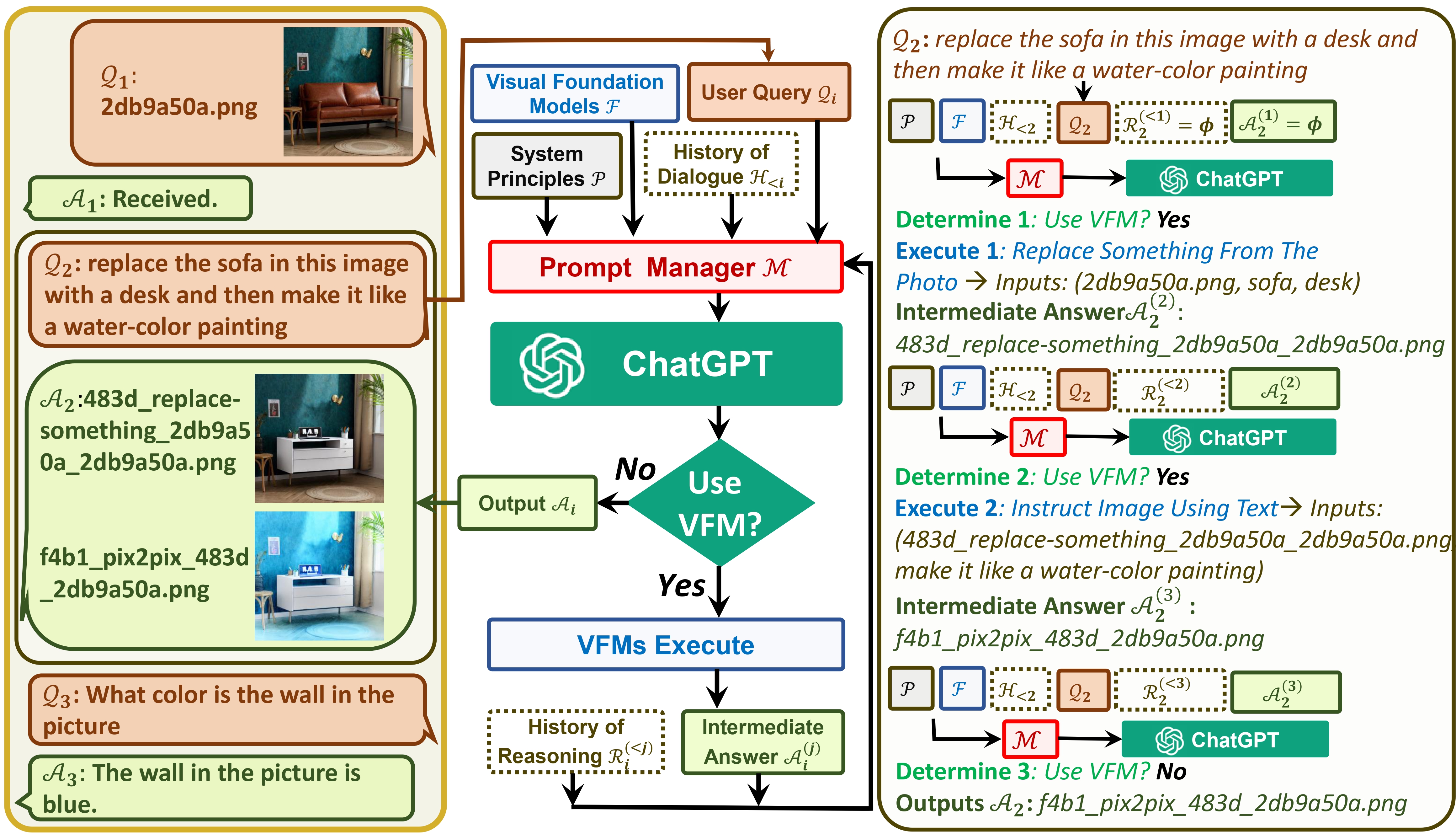
من ناحية، يعمل ChatGPT (أو LLMs) كواجهة عامة توفر فهمًا واسعًا ومتنوعًا لمجموعة واسعة من المواضيع. من ناحية أخرى، تعمل مؤسسة Foundation Models كخبراء في المجال من خلال توفير المعرفة العميقة في مجالات محددة. من خلال الاستفادة من المعرفة العامة والعميقة ، نهدف إلى بناء ذكاء اصطناعي قادر على التعامل مع المهام المختلفة.
# clone the repo
git clone https://github.com/microsoft/TaskMatrix.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
pip install git+https://github.com/IDEA-Research/GroundingDINO.git
pip install git+https://github.com/facebookresearch/segment-anything.git
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start TaskMatrix !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are separated by underline '_', the different models are separated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,
Inpainting_cuda:0,ImageCaptioning_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
ندرج هنا استخدام ذاكرة وحدة معالجة الرسومات لكل نموذج أساسي مرئي، ويمكنك تحديد النموذج الذي تفضله:
| نموذج الأساس | ذاكرة وحدة معالجة الرسومات (ميجابايت) |
|---|---|
| تحرير الصور | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| تسمية توضيحية للصورة | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Image2Line | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Image2Seg | 919 |
| SegText2Image | 3529 |
| Image2Depth | 0 |
| DepthText2Image | 3531 |
| Image2عادي | 0 |
| NormalText2Image | 3529 |
| إجابة الأسئلة المرئية | 1495 |
نحن نقدر المصدر المفتوح للمشاريع التالية:
معانقة الوجه LangChain التحكم في الانتشار المستقرNet InstructPix2Pix CLIPSeg BLIP
للحصول على مساعدة أو مشاكل في استخدام TaskMatrix، يرجى إرسال مشكلة GitHub.
بالنسبة للاتصالات الأخرى، يرجى الاتصال بـ Chenfei WU ([email protected]) أو Nan DUAN ([email protected]).
العلامات التجارية قد يحتوي هذا المشروع على علامات تجارية أو شعارات للمشاريع أو المنتجات أو الخدمات. يخضع الاستخدام المصرح به للعلامات التجارية أو الشعارات الخاصة بشركة Microsoft ويجب أن يتبع إرشادات العلامة التجارية والعلامات التجارية الخاصة بشركة Microsoft. يجب ألا يتسبب استخدام العلامات التجارية أو الشعارات الخاصة بشركة Microsoft في الإصدارات المعدلة من هذا المشروع في حدوث ارتباك أو الإشارة ضمنًا إلى رعاية Microsoft. ويخضع أي استخدام لعلامات تجارية أو شعارات تابعة لجهات خارجية لسياسات تلك الجهات الخارجية.
النماذج الموصى بها في هذا الريبو هي مجرد أمثلة، تُستخدم للبحث العلمي الذي يستكشف مفهوم أتمتة المهام وقياس الأداء من خلال الورقة المنشورة في Visual ChatGPT: التحدث والرسم والتحرير باستخدام نماذج الأساس المرئي. يمكن للمستخدمين استبدال النماذج الموجودة في هذا الريبو وفقًا لاحتياجاتهم البحثية. عند استخدام النماذج الموصى بها في هذا الريبو، يتعين عليك الالتزام بتراخيص هذه النماذج على التوالي. لن تتحمل Microsoft المسؤولية عن أي انتهاك لحقوق الطرف الثالث الناتج عن استخدامك لهذا الريبو. يوافق المستخدمون على الدفاع عن Microsoft وتعويضها وحمايتها من جميع الأضرار والتكاليف وأتعاب المحاماة فيما يتعلق بأي مطالبات تنشأ عن اتفاقية إعادة الشراء هذه. إذا كان أي شخص يعتقد أن هذا الريبو ينتهك حقوقك، فيرجى إبلاغ البريد الإلكتروني لمالك المشروع.


