AMRICA
1.0.0
AMRICA (AMR Inspector for Cross-language Alignments) هي أداة بسيطة لمحاذاة AMRs وتمثيلها بصريًا (Banarescu, 2013)، سواء بالنسبة للسياقات ثنائية اللغة أو للاتفاق بين التعليقات التوضيحية أحادية اللغة. وهو يعتمد على نظام Smatch ويوسعه (Cai, 2012) لتحديد اتفاق المدون التوضيحي AMR.
من الممكن أيضًا استخدام AMRICA لتصور المحاذاة اليدوية التي قمت بتحريرها أو تجميعها بنفسك (راجع العلامات المشتركة).
قم بتنزيل مصدر بايثون من جيثب.
نحن نفترض أن لديك pip . لتثبيت التبعيات (بافتراض أن لديك بالفعل تبعيات graphviz المذكورة أدناه)، ما عليك سوى تشغيل:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
يتطلب pygraphviz أن يعمل graphviz. في نظام التشغيل Linux، قد يتعين عليك تثبيت graphviz libgraphviz-dev pkg-config . بالإضافة إلى ذلك، لإعداد بيانات المحاذاة ثنائية اللغة، ستحتاج إلى GIZA++ وربما JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
سيقرأ هذا الأمر AMRs في sample.amr (مفصولة بأسطر فارغة) ويضع تصورات graphviz الخاصة بها في ملفات .png الموجودة في sample_out_dir/ .
لإنشاء تصورات لمحاذاة Smatch، نحتاج إلى ملف إدخال AMR مع كل حقل ::tok أو ::snt يحتوي على جمل مميزة، وحقول ::id بمعرف جملة، وحقول ::annotator أو ::anno بمعرف معلق توضيحي. يتم سرد التعليقات التوضيحية لجملة معينة بالتسلسل، ويعتبر التعليق التوضيحي الأول هو المعيار الذهبي لأغراض التصور.
إذا كنت تريد فقط تصور التعليق التوضيحي الفردي لكل جملة دون موافقة المعلق الداخلي، فيمكنك استخدام ملف AMR مع معلق توضيحي واحد فقط. في هذه الحالة، يكون حقلا التعليق التوضيحي ومعرف الجملة اختياريين. سيكون الرسم البياني الناتج باللون الأسود بالكامل.
بالنسبة للمحاذاة ثنائية اللغة، نبدأ بملفين AMR، أحدهما يحتوي على التعليقات التوضيحية المستهدفة والآخر يحتوي على التعليقات التوضيحية للمصدر بنفس الترتيب، مع حقول ::tok و ::id لكل تعليق توضيحي. إذا أردنا محاذاة JAMR لأي من الجانبين، فإننا نقوم بتضمين تلك الموجودة في حقل ::alignments .
يجب أن تكون محاذاة الجملة في شكل ملفي .NBEST لمحاذاة GIZA++، وهدف مصدر واحد ومصدر هدف واحد. لإنشاء هذه العناصر، استخدم علامة --nbestalignments في ملف تكوين GIZA++ الخاص بك الذي تم تعيينه على عدد nbest المفضل لديك.
يمكن تعيين العلامات إما في سطر الأوامر أو في ملف التكوين. يمكن تعيين موقع ملف التكوين باستخدام -c CONF_FILE في سطر الأوامر.
بالإضافة إلى --conf_file ، هناك العديد من العلامات الأخرى التي تنطبق على النص أحادي اللغة وثنائي اللغة. --outdir DIR هو الخيار الوحيد المطلوب، ويحدد الدليل الذي سنكتب ملفات الصور إليه.
العلامات المشتركة الاختيارية هي:
--verbose لطباعة الجمل أثناء مواءمتها.--no-verbose لتجاوز الإعداد الافتراضي المطول.--json FILE.json لكتابة الرسوم البيانية للمحاذاة إلى ملف .json.--num_restarts N لتحديد عدد عمليات إعادة التشغيل العشوائية التي يجب على Smatch تنفيذها.--align_out FILE.csv لكتابة المحاذاة للملف.--align_in FILE.csv لقراءة المحاذاة من القرص بدلاً من تشغيل Smatch.--layout لتعديل معلمة التخطيط إلى graphviz.تكون ملفات المحاذاة .csv بتنسيق حيث يتم فصل كل مجموعة مطابقة للرسوم البيانية بخط فارغ، ويحتوي كل سطر داخل المجموعة إما على تعليق أو سطر يشير إلى المحاذاة. على سبيل المثال:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
الحقول المفصولة بعلامات جدولة هي فهرس عقدة الاختبار (كما تمت معالجته بواسطة Smatch)، وتسمية عقدة الاختبار، وفهرس العقدة الذهبية، وتسمية العقدة الذهبية.
تتطلب المحاذاة أحادية اللغة علامة إضافية واحدة، --infile FILE.amr ، مع تعيين FILE.amr على موقع ملف AMR.
فيما يلي مثال لملف التكوين:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
في المحاذاة ثنائية اللغة، هناك المزيد من العلامات المطلوبة.
--src_amr FILE لملف التعليق التوضيحي المصدر AMR.--tgt_amr FILE لملف AMR للتعليق التوضيحي المستهدف.--align_tgt2src FILE.A3.NBEST لملف GIZA++ .NBEST الذي يقوم بمحاذاة الهدف إلى المصدر (مع الهدف كـ vcb1)، الذي تم إنشاؤه باستخدام --nbestalignments N--align_src2tgt FILE.A3.NBEST لملف GIZA++ .NBEST الذي يقوم بمحاذاة المصدر إلى الهدف (مع المصدر كـ vcb1)، الذي تم إنشاؤه باستخدام --nbestalignments N الآن، إذا تم ضبط --nbestalignments N على >1، فيجب أن نحدده باستخدام --num_aligned_in_file . إذا أردنا أن نحسب فقط الجزء العلوي --num_align_read أيضًا.
--nbestalignments علامة صعبة الاستخدام، لأنها لن يتم إنشاؤها إلا عند تشغيل المحاذاة النهائية. لم أتمكن من تشغيله إلا مع إعدادات GIZA++ الافتراضية بنفسي.
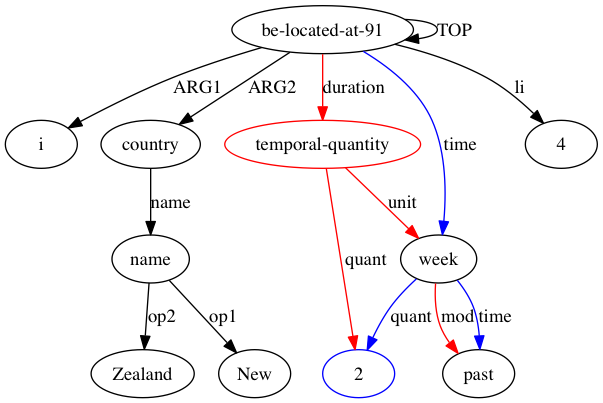
نظرًا لأن AMRICA هو شكل مختلف من Smatch، فيجب على المرء أن يبدأ بفهم Smatch. يحاول Smatch تحديد المطابقة بين العقد المتغيرة لتمثيلين AMR لنفس الجملة من أجل قياس الاتفاق بين المعلقين. يجب تحديد المطابقة لتعظيم درجة التوافق، والتي تحدد نقطة لكل حافة تظهر في كلا الرسمين البيانيين، وتنقسم إلى ثلاث فئات. تم توضيح كل فئة في التعليق التوضيحي التالي "لم يستغرق الأمر وقتًا طويلاً".
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)نظرًا لأن مشكلة العثور على المطابقة التي تزيد من نقاط Smatch هي NP كاملة، فإن Smatch يستخدم خوارزمية تسلق التل لتقريب الحل الأفضل. يتم البذور عن طريق مطابقة كل عقدة مع عقدة تشارك اسمها إن أمكن ومطابقة العقد المتبقية في الرسم البياني الأصغر (يشار إليها فيما بعد بالهدف) بشكل عشوائي. يقوم Smatch بعد ذلك بتنفيذ خطوة من خلال العثور على الإجراء الذي سيزيد النتيجة إلى أقصى حد إما عن طريق تبديل مطابقات العقدتين المستهدفتين أو نقل المطابقة من العقدة المصدر الخاصة بها إلى عقدة مصدر غير متطابقة. يكرر هذه الخطوة حتى لا تتمكن أي خطوة من زيادة نتيجة المباراة على الفور.
لتجنب الأمثلية المحلية، يتم إعادة تشغيل Smatch بشكل عام 5 مرات.
للحصول على تفاصيل فنية حول الأعمال الداخلية لـ AMRICA، قد يكون من المفيد قراءة ورقتنا التجريبية NAACL.
تبدأ AMRICA باستبدال جميع العقد الثابتة بعقد متغيرة تمثل أمثلة على تسمية الثابت. وهذا ضروري حتى نتمكن من محاذاة العقد الثابتة وكذلك المتغيرات. لذا فإن النقاط الوحيدة المضافة إلى نتيجة AMRICA ستأتي من مطابقة الحواف المتغيرة وتسميات المثيلات.
بينما يحاول Smatch مطابقة كل عقدة في الرسم البياني الأصغر مع بعض العقد في الرسم البياني الأكبر، تقوم AMRICA بإزالة المطابقات التي لا تزيد من درجة Smatch المعدلة، أو درجة AMRICA.
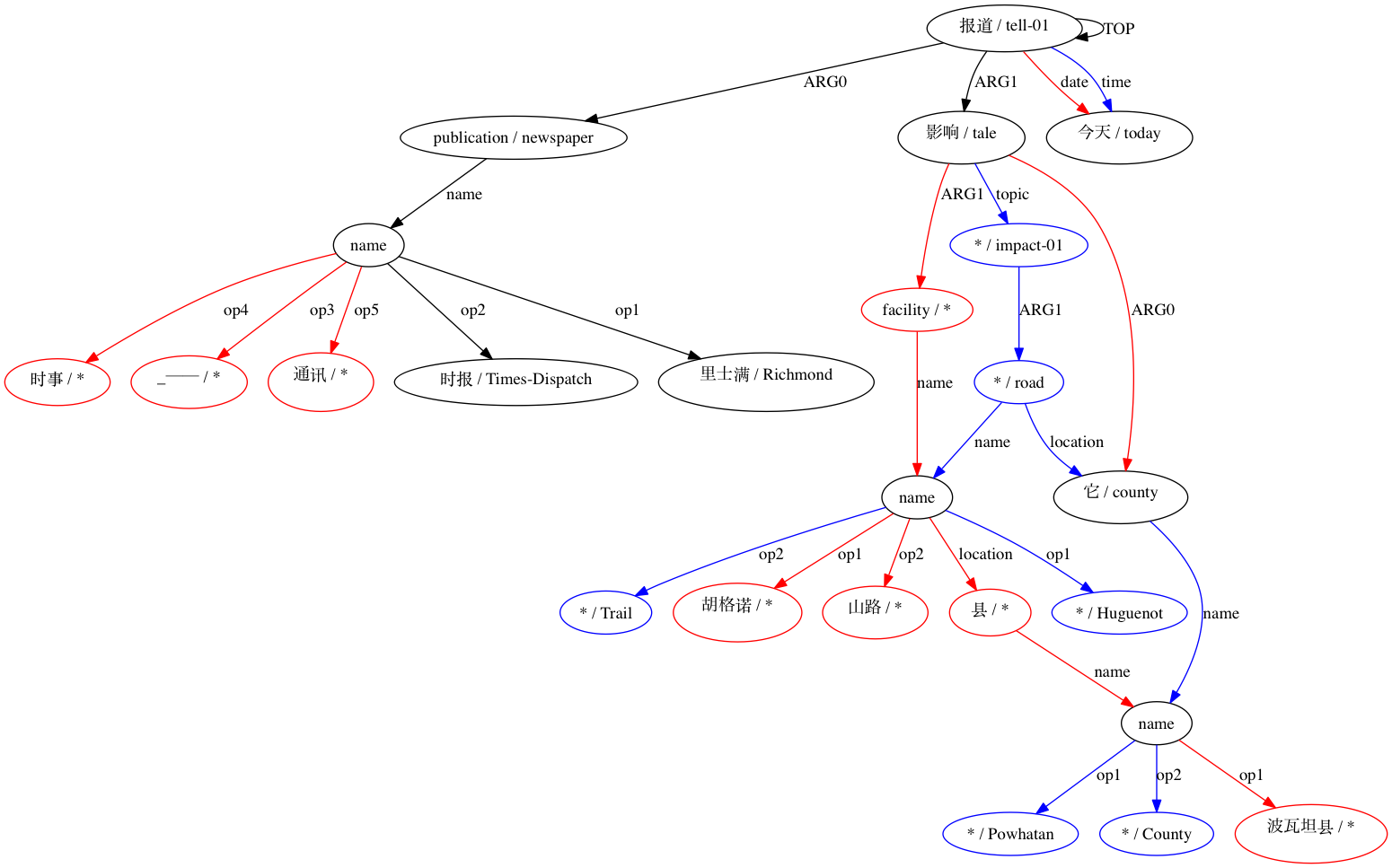
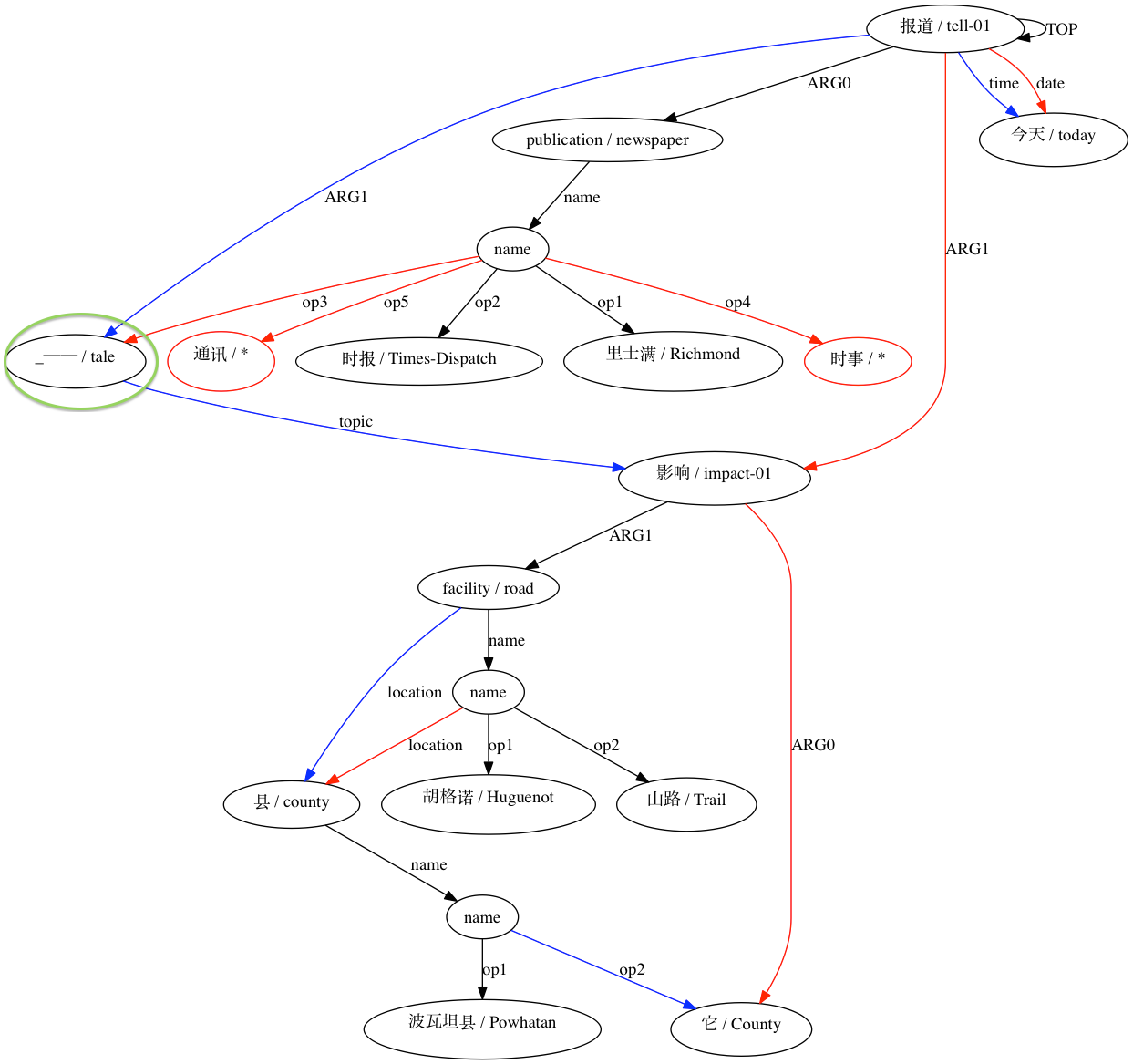
تقوم AMRICA بعد ذلك بإنشاء ملفات صور من الرسوم البيانية graphviz للمحاذاة. إذا ظهرت عقدة أو حافة فقط في البيانات الذهبية، فهي حمراء. إذا ظهرت تلك العقدة أو الحافة فقط في بيانات الاختبار، فستكون باللون الأزرق. إذا كانت العقدة أو الحافة لها مطابقة في المحاذاة النهائية لدينا، فهي سوداء.
في AMRICA، بدلاً من إضافة نقطة واحدة لكل تسمية مثيل متطابقة تمامًا، نضيف نقطة بناءً على درجة الاحتمالية في محاذاة تلك التسميات. درجة الاحتمالية ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) مع مجموعة التسمية المستهدفة Lt، مجموعة تسميات المصدر Ls، الجملة المستهدفة Wt، الجملة المصدر Ws، والمحاذاة aLt,Ls[i] تعيين Lt[ i] على بعض التسميات Ls[aLt,Ls[i]]، يتم حسابها من الاحتمال الذي يتم تحديده بواسطة القواعد التالية:
بشكل عام، يبدو أن AMRICA ثنائية اللغة تتطلب عمليات إعادة تشغيل عشوائية أكثر من AMRICA أحادية اللغة لتحقيق أداء جيد. يمكن تعديل عدد إعادة التشغيل هذا باستخدام العلامة --num_restarts .
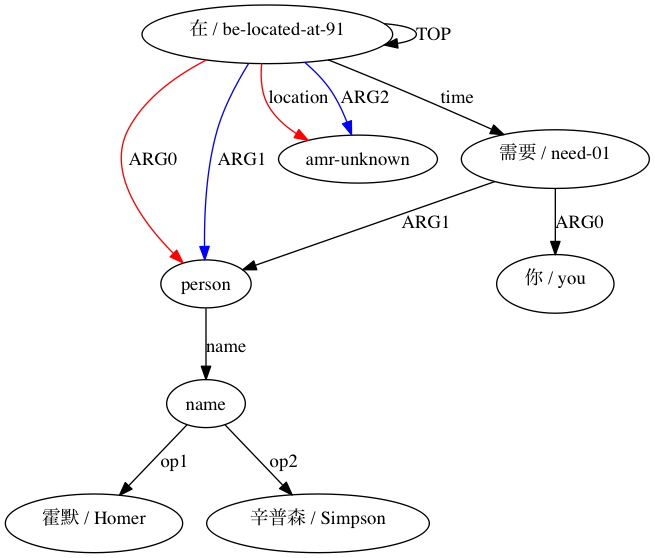
يمكننا ملاحظة الدرجة التي يؤدي بها استخدام التقديرات التقريبية المشابهة لـ Smatch (هنا، مع 20 عملية تهيئة عشوائية) إلى تحسين الدقة مقارنة باختيار التطابقات المحتملة من بيانات المحاذاة الأولية (التهيئة الذكية). تم الإعلان عن الاقتران متوافقًا هيكليًا بواسطة (Xue 2014).
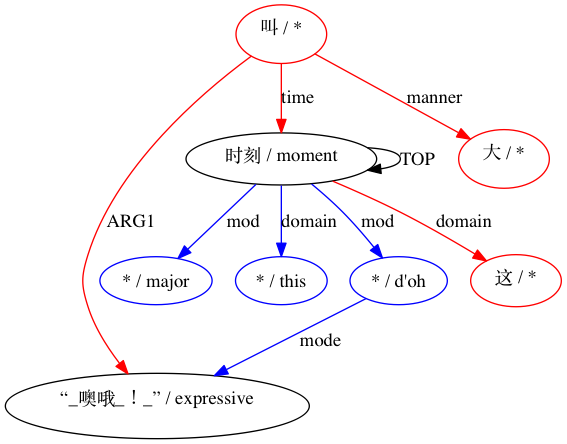
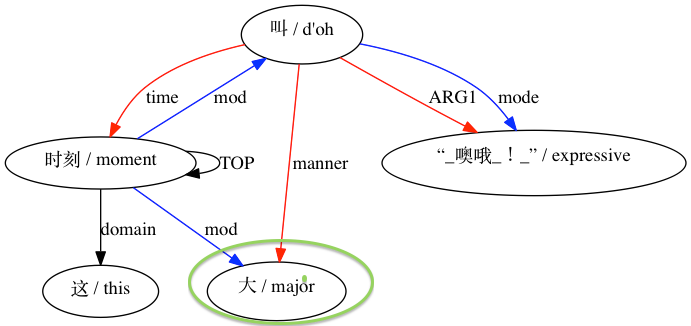
بالنسبة للاقتران الذي يعتبر غير متوافق:
تم تطوير هذا البرنامج جزئيًا بدعم من المؤسسة الوطنية للعلوم (الولايات المتحدة الأمريكية) بموجب الجوائز رقم 1349902 و0530118. جامعة إدنبرة هي هيئة خيرية، مسجلة في اسكتلندا، برقم التسجيل SC005336.


