llmjudge
1.0.0
يعد تقييم LLMs في سيناريو مفتوح أمرًا صعبًا، وهناك إجماع متزايد على عدم وجود معايير حالية ويفضل الممارسون المتمرسون التحقق من النماذج بأنفسهم. لقد لجأت إلى التقييمات القصصية من المطورين والباحثين الذين أثق بهم، مع كون Chatbot Arena مكملاً ممتازًا. الدافع وراء هذا الريبو هو الطريقة الشائعة بشكل متزايد لاستخدام حاملي شهادة الماجستير في القانون (LLM) كحكم للنماذج. كانت هذه الطريقة موجودة منذ بضعة أشهر، مع نماذج مثل JudgeLM، ومؤخرًا MT-Bench.
ربما تكون قد شاهدت هذا الموضوع أو لم تشاهده. وفقًا لمؤلفي التغريدة في Arize AI، فإن استخدام LLMs-as-a-قاضي يستدعي الحذر من الخادم، خاصة فيما يتعلق باستخدام تقييمات النتائج الرقمية. يبدو أن طلاب LLM سيئون جدًا في التعامل مع النطاقات المستمرة، وهو ما يصبح واضحًا بشكل صارخ عند مطالبتهم بتقييم X من 1 إلى 10. يعد هذا الريبو بمثابة وثيقة حية للتجارب التي تحاول فهم الحدود الخشنة لهذه المشكلة والتقاطها. لقد أثبت العمل الأخير وجود علاقة قوية بين MT-Bench والحكم البشري (Arena Elo) ، مما يعني أن حاملي الماجستير في القانون قادرون على أن يكونوا قضاة، فما الذي يحدث هنا؟
وفيما يلي التفاصيل الكاملة والنتائج.
نظرًا لقيود التكلفة، سأركز في البداية على مهمة الإملاء/الأخطاء الإملائية الموضحة في التغريدات. أنا قلق بعض الشيء من أن X الكمي لهذه المهمة سوف يلوث رؤى هذه التجربة، لكننا سنرى. إنني أرحب بإجراء تحليل أكثر شمولاً لهذه الظاهرة، ويجب أن تؤخذ نتائجي بحذر نظرًا للتجربة المحدودة
لقد قمت بإنشاء مجموعة بيانات تحتوي على أخطاء إملائية أو إملائية، ولست متأكدًا من الاسم الأكثر ملاءمة، من مقالات بول جراهام. كان هذا الاختيار في الغالب غير ملائم لأنني استخدمت مجموعة البيانات من قبل عند نوافذ سياق اختبار الضغط. لقد استخرجت سياقًا مكونًا من 3000 كلمة من المقالات وأدخلت أخطاء إملائية في كلمات عشوائية بناءً على نسبة الأخطاء الإملائية المطلوبة. في الكود الزائف:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
الكود الكامل متاح بسهولة كدفتر ملاحظات.
نظرًا لمجموعة البيانات التي تم إنشاؤها، فإننا نطالب LLMs بتقييم كمية الكلمات التي بها أخطاء إملائية في سياق باستخدام قوالب تسجيل مختلفة. نحن نستخدم واجهات برمجة التطبيقات التالية
جي بي تي-4: gpt-4-0125-preview
جي بي تي-3.5: gpt-3.5-turbo-1106
عند درجة حرارة = 0
الاختبار 1. دعونا نؤكد أن LLMs يكافحون من أجل التعامل مع النطاقات الرقمية في بيئة الصفر. نحن نطالب GPT-3.5 وGPT-4 باستخدام قالب تسجيل رقمي، يتراوح من النتيجة 0 إلى النتيجة 10.
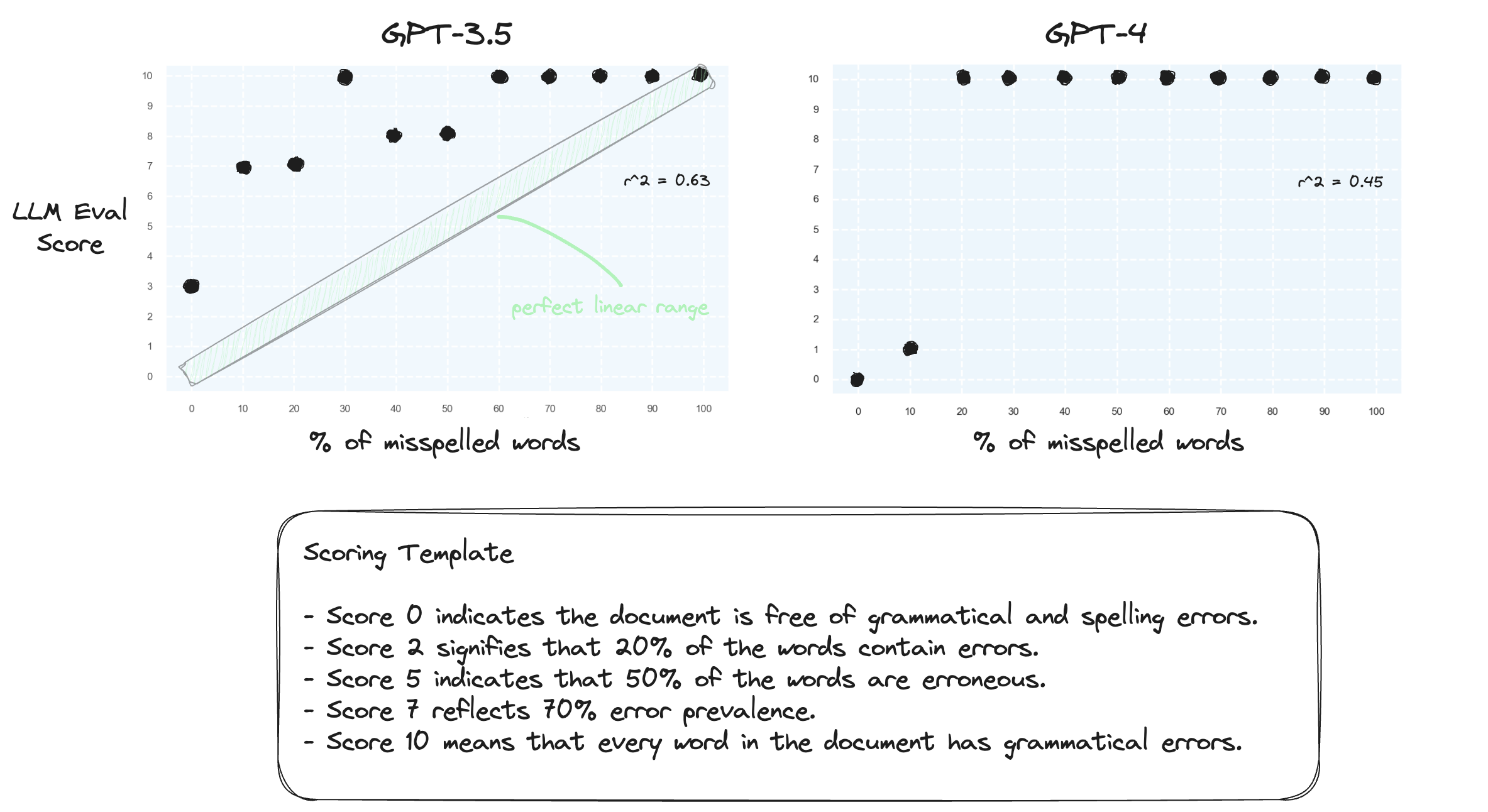
وكما هو متوقع، كلاهما أخطأ في الحكم بشدة.
الاختبار 2. ماذا يحدث إذا قمنا بعكس نطاق التسجيل؟ الآن، تمثل الدرجة 10 مستندًا مكتوبًا بشكل مثالي.
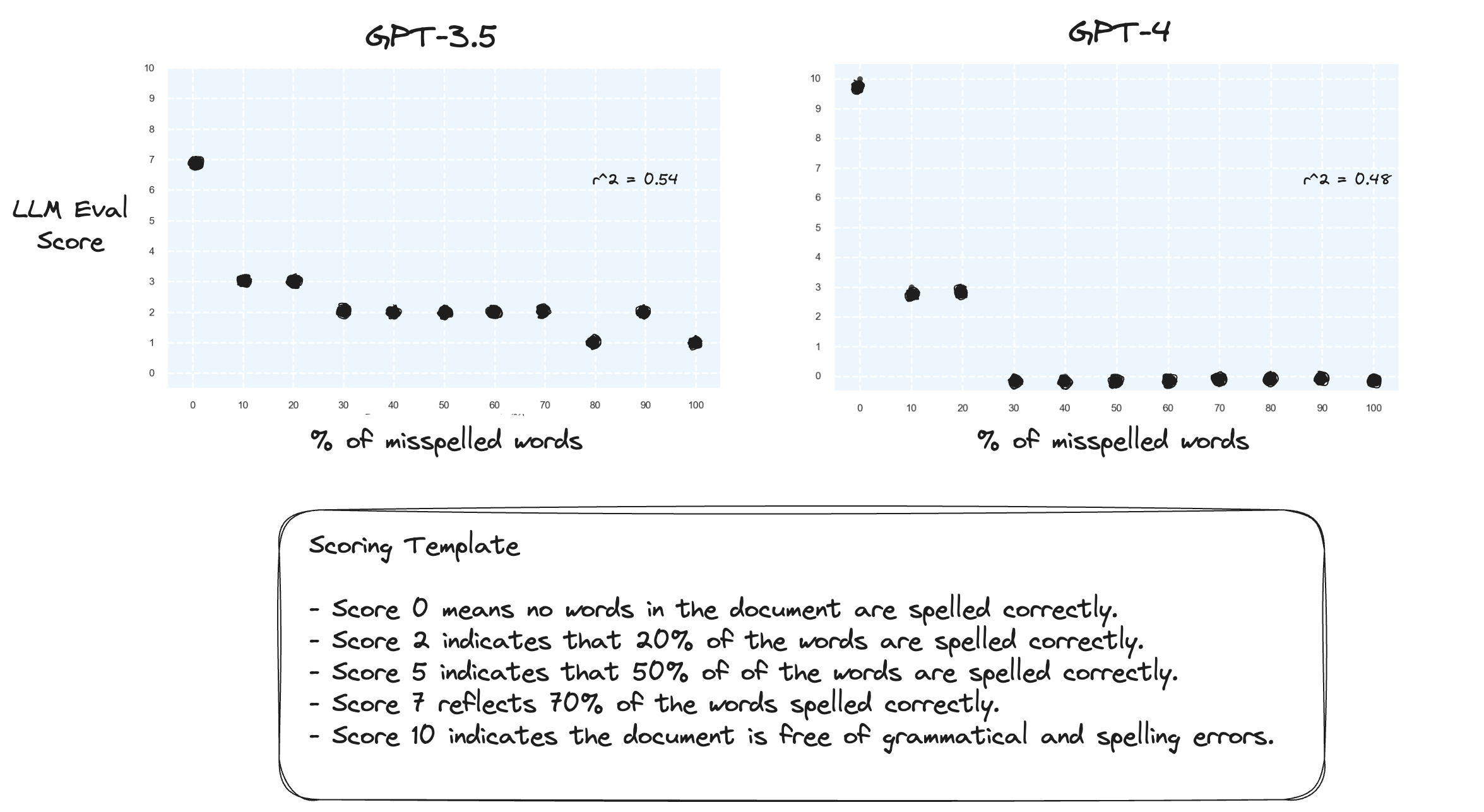
لا يبدو أن هذا يحدث فرقًا كبيرًا.
الاختبار 3. إذا كنا نصدق فرضية Arize، فقد نرى تحسينات إذا تجنبنا نموذج تقييم النقاط واستخدمنا بدلاً من ذلك "الدرجات المُصنفة". في هذه الحالة قررت الانتقال إلى مقياس الدرجات المكون من 5 نقاط.
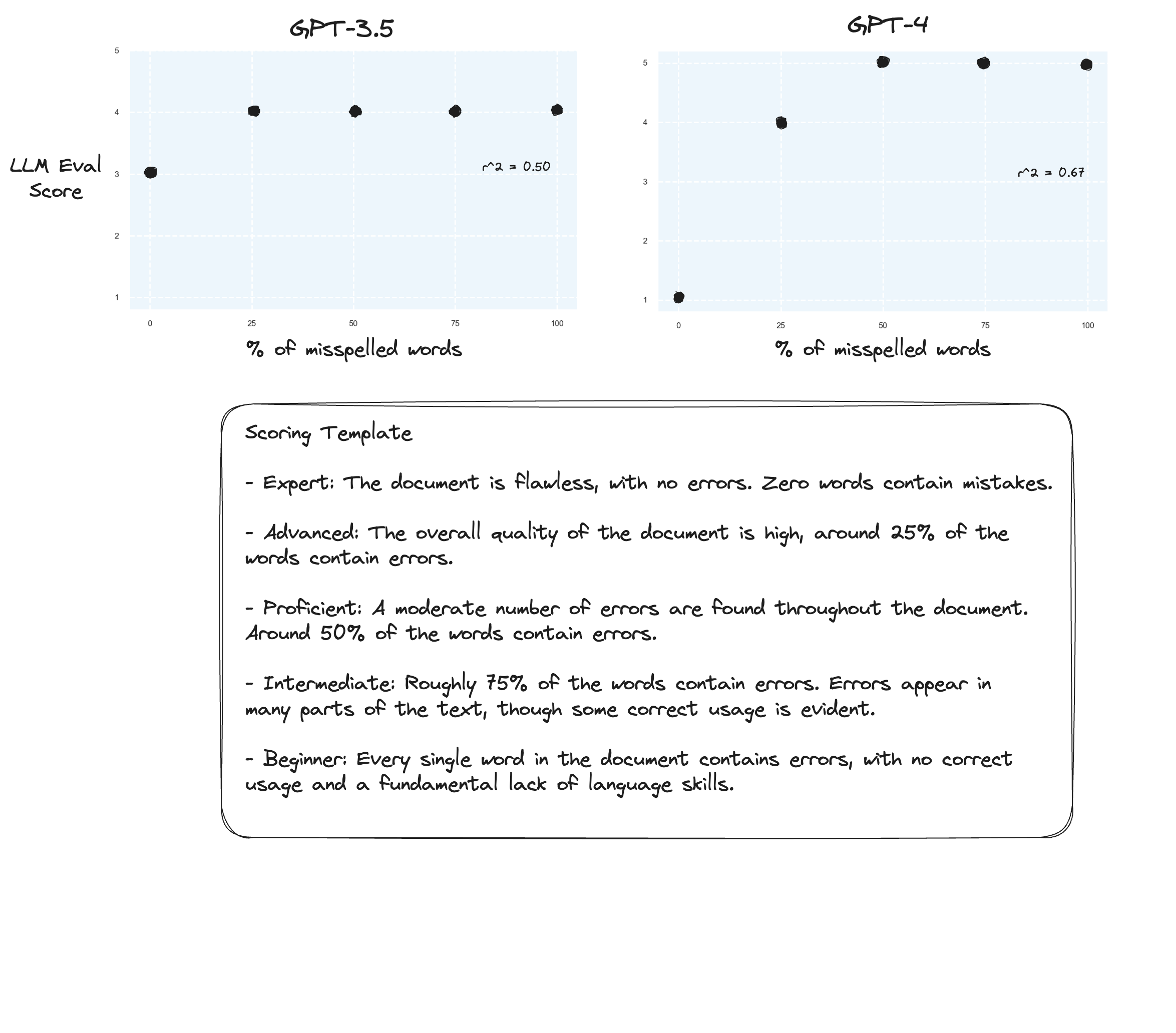
ربما تحسينات طفيفة؟ من الصعب أن أقول بصراحة. أنا لست معجبا.
الاختبار 4. ماذا عن سلسلة الأفكار الصفرية؟

gpt-3.5 تطورت إلى رطانة لاثنين من المطالبات. كما هو متوقع، يشهد gpt-4 تحسنًا عندما يُطلب منه التفكير بصوت عالٍ. لاحظ كيف أصبح مترددًا جدًا في تحديد درجة 10.
اختبار 5. كما اقترح مؤلف بروميثيوس؛ من المحتمل أن يؤدي تعيين كل درجة مع تفسيرها الخاص إلى تحسين قدرة LLM على التقييم عبر النطاق الرقمي بأكمله. يؤدي هذا، جنبًا إلى جنب مع CoT، إلى:

التحسينات المستمرة لgpt-4. لا يزال من المتردد جدًا تعيين درجات الحدود 0 و10.
الاختبار 6. بعد قراءة المزيد عن MT Bench، قررت اختبار نهج بديل، باستخدام المقارنات الزوجية بدلاً من التسجيل المعزول. الآن، عادةً ما يتطلب هذا مقارنات O(n * log N)، ولكن نظرًا لأننا نعرف الترتيب بالفعل، اعتقدت أننا سنختبر أصعب الحالات فقط: مقارنة 0% خطأ إملائي مقابل 10% خطأ إملائي، و10% مقابل 20% وما إلى ذلك. ليصبح المجموع 10 مقارنات. لاحظ أنني استخدمت CoT بدون طلقة أيضًا.
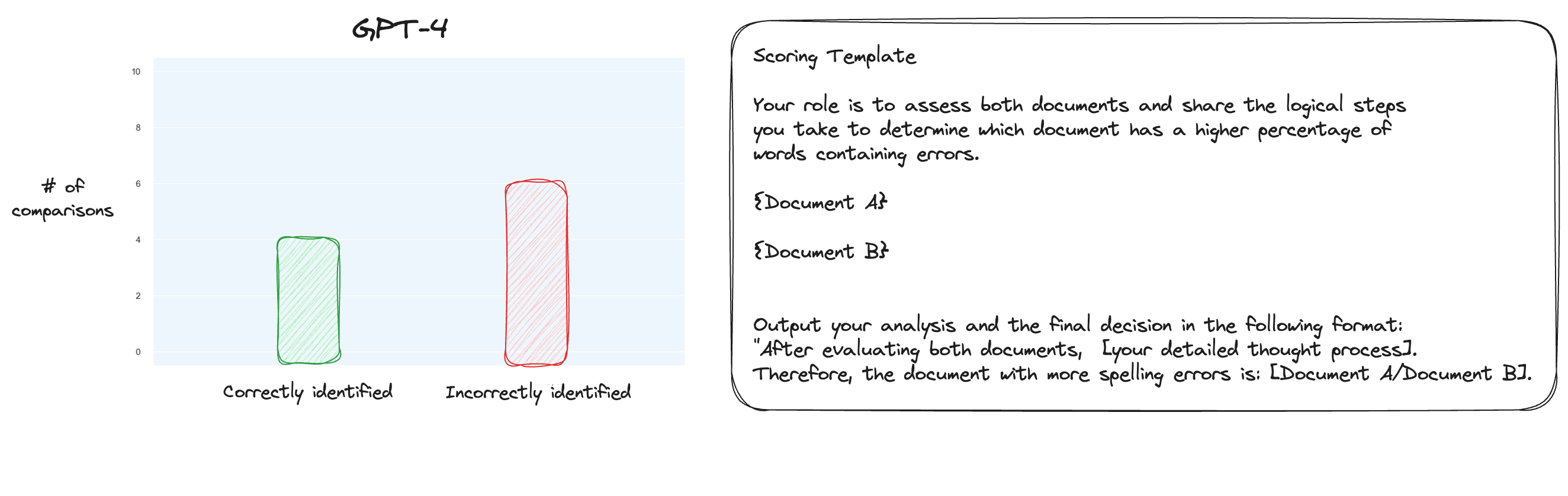
كانت فرضيتي هي أن GPT-4 كان سيتفوق في سيناريو حيث كان عليه مقارنة نصين داخل نافذة السياق الخاصة به ولكني كنت مخطئًا. لدهشتي أن هذا لم يحسن الأمور على الإطلاق. من المؤكد أن هذه هي الأصعب من بين جميع المقارنات الممكنة، ولكن في المجمل، لا تزال هذه مهمة مباشرة. ربما تكون الجوانب الكمية لهذه المهمة صعبة للغاية بطبيعتها بالنسبة لحاملي LLM. حسنًا، ربما أحتاج إلى العثور على مهمة وكيل أفضل...
(31/1) لقد قمت بمراجعة الأجزاء الداخلية لـ MT-Bench، وتفاجأت جدًا عندما وجدت أنهم ببساطة يطلبون من GPT-4 تسجيل النتائج على مقياس من 1 إلى 10. إنهم يوفرون خيارات تصنيف بديلة مثل المقارنات الزوجية مقابل خط الأساس ولكن الخيار الموصى به هو الخيار الرقمي. مطالبة الحكم أيضًا بسيطة بشكل غير متوقع:
يرجى التصرف كقاضي محايد وتقييم جودة الرد المقدم من مساعد الذكاء الاصطناعي على سؤال المستخدم الموضح أدناه. يجب أن يأخذ تقييمك في الاعتبار عوامل مثل مدى فائدة الاستجابة وملاءمتها ودقتها وعمقها وإبداعها ومستوى تفصيلها. ابدأ تقييمك بتقديم شرح قصير. كن موضوعيًا قدر الإمكان. بعد تقديم شرحك، يجب عليك تقييم الاستجابة على مقياس من 1 إلى 10 باتباع هذا التنسيق بدقة: [التصنيف]، على سبيل المثال: "التقييم: 5". [سؤال] {سؤال} [بداية إجابة المساعد] {إجابة} [نهاية إجابة المساعد]
إذا كان على المرء أن يعتقد أن هذا هو كل ما يمكن الحكم عليه في MT-Bench، فأنا أبدأ في التشكيك في استخدام مهمة الأخطاء الإملائية كمهمة وكيل...
(2/2) أنا حريص على جعل GPT-4 يحكم على النصوص التي بها أخطاء إملائية من خلال المقارنة الزوجية بدلاً من التسجيل المعزول. هذه إحدى طرق الحكم البديلة لـ MT Bench (على الرغم من أنهم يوصون بتسجيل النقاط المعزولة)، وأظن أنها أكثر ملاءمة لهذه المهمة. تعد نتائج رسم الخرائط الكاملة لـ CoT + تحسنًا بالتأكيد ولكني ما زلت أعتقد أن هناك عملًا يتعين القيام به. العيب في التسجيل الزوجي هو بالطبع أنك ستحتاج إلى المزيد من استدعاءات واجهة برمجة التطبيقات (API) بشكل ملحوظ لإنشاء الترتيب الكامل (في الممارسة العملية).


