datalens
1.0.0
هذه تجربة شخصية تستخدم LLMs لتصنيف بيانات الوظائف غير المنظمة بناءً على معايير يحددها المستخدم. تعتمد منصات البحث عن الوظائف التقليدية على أنظمة تصفية صارمة، لكن العديد من المستخدمين يفتقرون إلى مثل هذه المعايير الملموسة. يتيح لك Datalens تحديد تفضيلاتك بطريقة أكثر طبيعية ومن ثم تقييم كل منشور وظيفي بناءً على مدى ملاءمته.
قد تكون بعض المعايير أكثر أهمية من غيرها، لذلك يتم ترجيح "المعايير الواجبة" بمقدار ضعف المعايير العادية.
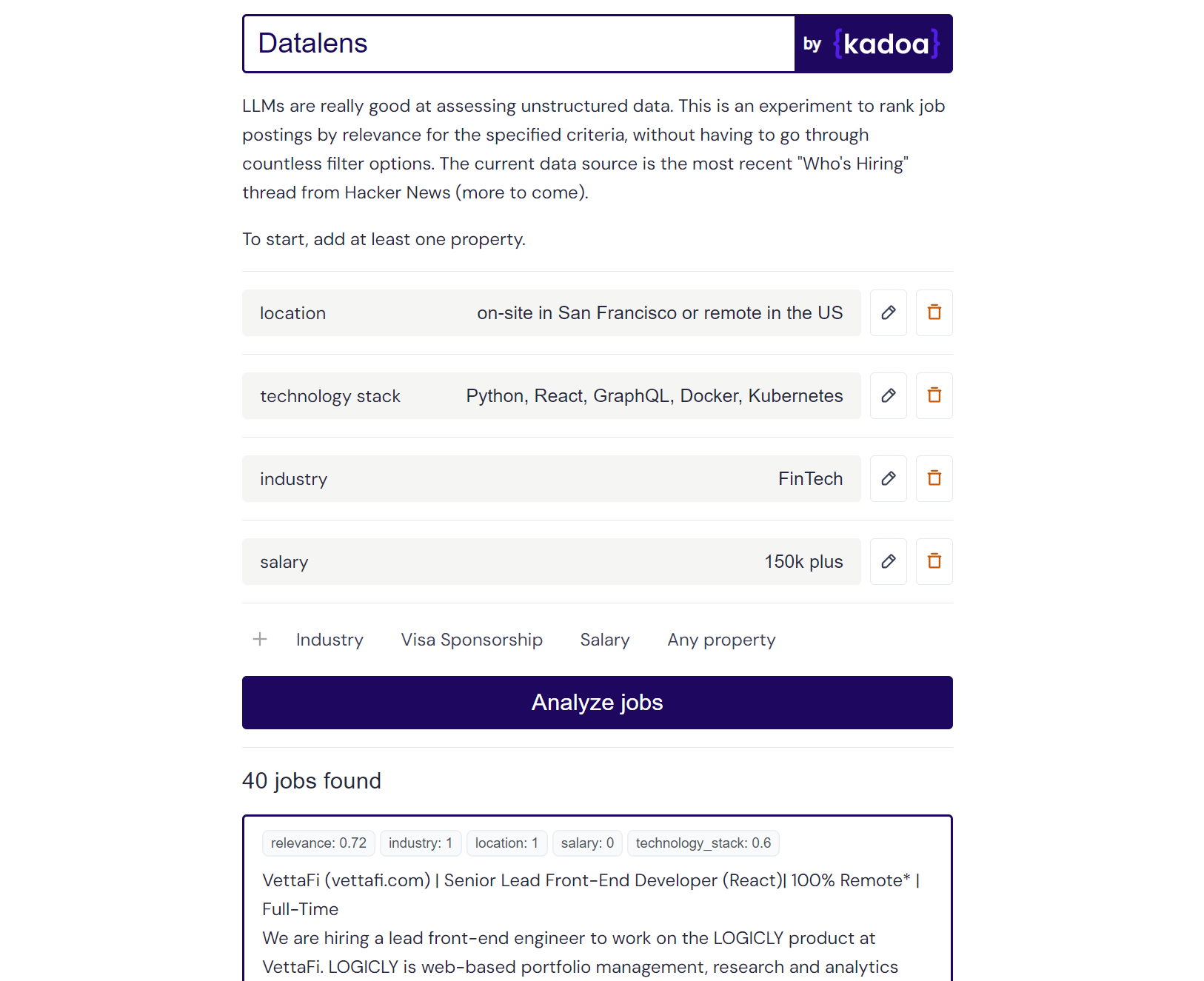
نتيجة مثال كلود 2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
يمكنك إضافة أي مصدر بيانات وظيفي تريده. لقد قمت بتكوينه مسبقًا باستخدام أحدث سلسلة رسائل بعنوان "Who's Hiring" من Hacker News، ولكن يمكنك إضافة مصادرك الخاصة.
أضف مصادر وظائف جديدة عن طريق تحديث Resources_config.json. مثال:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
لقد استخدمت أداتي الخاصة Kadoa لجلب بيانات الوظائف من صفحات الشركة، ولكن يمكنك استخدام أي طريقة تقليدية أخرى للاستخراج.
فيما يلي بعض نقاط النهاية العامة الجاهزة للحصول على جميع إعلانات الوظائف من هذه الشركات (يتم تحديثها يوميًا):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
اسمحوا لي أن أعرف إذا كان ينبغي إضافة أي شركات أخرى. ويسعدنا أيضًا أن نمنحك إمكانية الوصول التجريبي إلى Kadoa.
تعمل نقاط الملاءمة بشكل أفضل مع gpt-4-0613 الذي يُرجع درجات تفصيلية بين 0-1. يعمل claude-2 جيدًا أيضًا إذا كان بإمكانك الوصول إليه. يمكن استخدام gpt-3.5-turbo-0613 ، لكنه غالبًا ما يُرجع درجات ثنائية تبلغ 0 أو 1 للمعايير، ويفتقر إلى الفروق الدقيقة للتمييز بين التطابقات الجزئية والكاملة.
النموذج الافتراضي هو gpt-3.5-turbo-0613 لأسباب تتعلق بالتكلفة. يمكنك التبديل من GPT إلى Claude عن طريق استبدال use_claude بـ use_openai .
يمكن أن يؤدي تشغيل هذا البرنامج النصي بشكل مستمر إلى زيادة استخدام واجهة برمجة التطبيقات (API)، لذا يرجى استخدامه بمسؤولية. أقوم بتسجيل التكلفة لكل مكالمة GPT.
لتشغيل التطبيق، تحتاج إلى:
انسخ ملف .env.example واملأه.
قم بتشغيل خادم Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
انتقل إلى دليل العميل وقم بتثبيت تبعيات Node:
cd client
npm install
قم بتشغيل عميل Next.js:
cd client
npm run dev


