Darwin
1.0.0
المنظمة: جامعة نيو ساوث ويلز (UNSW) AI4Science & GreenDynamics AI
داروين هو مشروع مفتوح المصدر مخصص للتدريب المسبق وضبط نموذج LLaMA على الأدبيات العلمية ومجموعات البيانات. تم تصميم داروين خصيصًا للمجال العلمي مع التركيز على علوم المواد والكيمياء والفيزياء، وهو يدمج المعرفة العلمية المنظمة وغير المنظمة لتعزيز فعالية نماذج اللغة في البحث العلمي.
إشعارات الاستخدام والترخيص : داروين مرخص ومخصص للاستخدام البحثي فقط. تم ترخيص مجموعة البيانات بموجب CC BY NC 4.0، مما يسمح بالاستخدام غير التجاري. لا ينبغي استخدام النماذج التي تم تدريبها باستخدام مجموعة البيانات هذه خارج أغراض البحث. فرق الوزن أيضًا بموجب ترخيص CC BY NC 4.0
[2024.11.20]
الإنجازات الرئيسية
رؤى أداء النموذج
استراتيجيات البيانات والرؤى
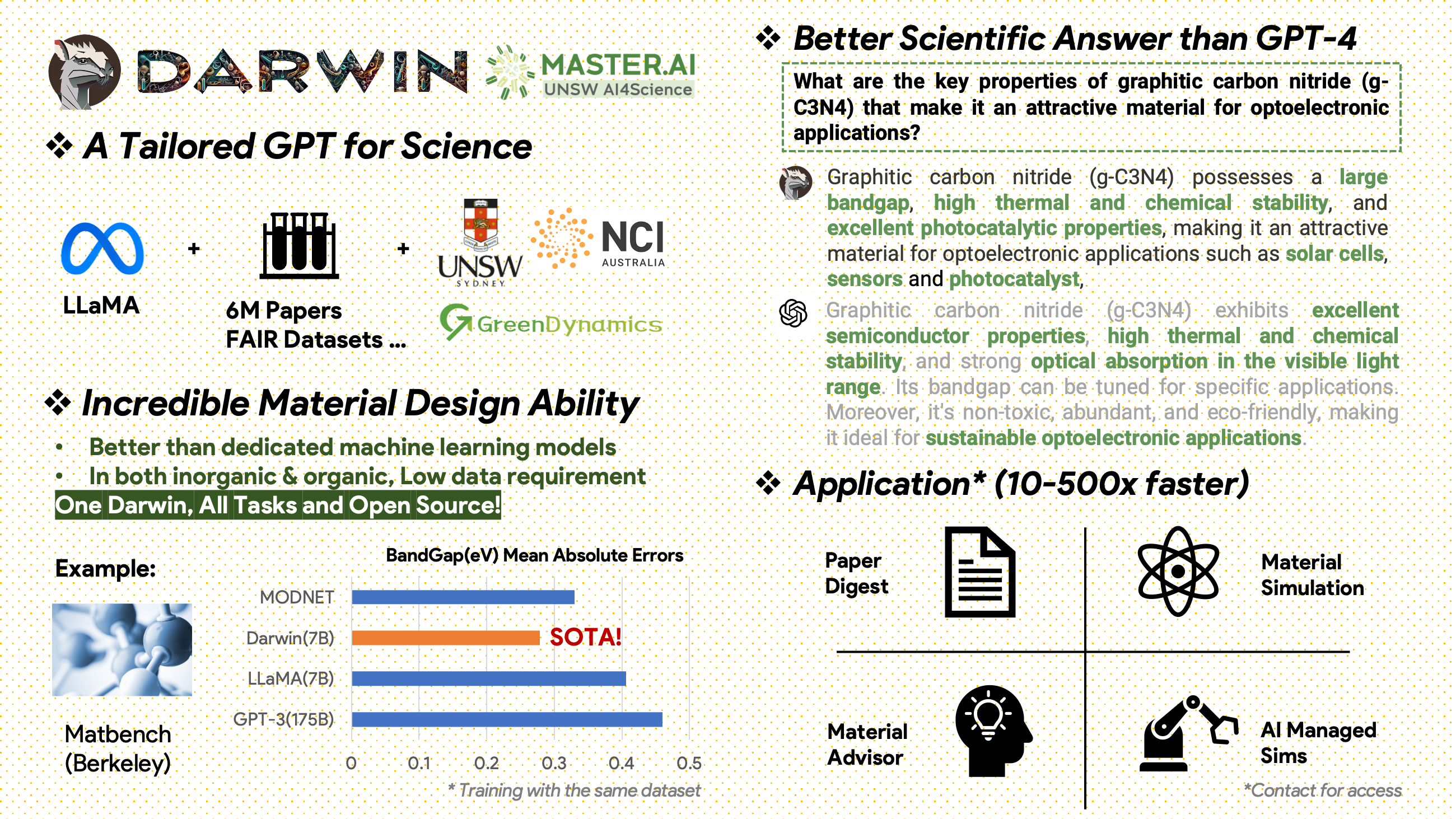
[2024.02.15] SOTA في MatBench بواسطة Material Projects: DARWIN هو نموذج SOTA في مهام التنبؤ بفجوة النطاق التجريبية ومهام تصنيف المعادن، وهو أفضل من نماذج GPT3.5 المضبوطة بدقة ونماذج ML المخصصة. https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15] يتوفر إصدار Google Colab: جرب DARWIN الخاص بنا مع Google Colab: inference.ipynb
تم تدريب داروين، استنادًا إلى نموذج 7B LLaMA، على أكثر من 100000 نقطة بيانات تتبع التعليمات التي تم إنشاؤها بواسطة مولد داروين للتعليمات العلمية (SIG) من مجموعات بيانات FAIR العلمية المختلفة ومجموعة الأدبيات. من خلال التركيز على الصحة الواقعية لاستجابات النموذج، يمثل داروين خطوة كبيرة نحو الاستفادة من النماذج اللغوية الكبيرة (LLMs) للاكتشافات العلمية. تشير التقييمات البشرية الأولية إلى أن داروين 7 بي يتفوق على GPT-4 في الأسئلة والأجوبة العلمية وGPT-3 المضبوط بدقة في حل مشاكل الكيمياء (مثل gptChem).
نحن نعمل بنشاط على تطوير داروين لإجراء المزيد من تجارب المجال العلمي المتقدمة، كما نقوم أيضًا بدمج داروين مع LangChain لحل المهام العلمية الأكثر تعقيدًا (مثل مساعد بحث خاص لأجهزة الكمبيوتر الشخصية).
يرجى ملاحظة أن داروين لا يزال قيد التطوير، ويجب معالجة العديد من القيود. والأهم من ذلك، أننا لم نضبط داروين بعد لتحقيق أقصى قدر من الأمان. نحن نشجع المستخدمين على الإبلاغ عن أي سلوك مقلق للمساعدة في تحسين سلامة النموذج والاعتبارات الأخلاقية.
الرابط التجريبي
أولا تثبيت المتطلبات:
pip install -r requirements.txtقم بتنزيل نقاط التفتيش الخاصة بأوزان Darwin-7B من onedrive. بمجرد تنزيل النموذج، يمكنك تجربة العرض التوضيحي الخاص بنا:
python inference.py < your path to darwin-7b >يرجى ملاحظة أن الاستدلال يتطلب ما لا يقل عن 10 جيجابايت من ذاكرة GPU لـ Darwin 7B.
لمزيد من الضبط الدقيق لـ Darwin-7b الخاص بنا باستخدام مجموعات بيانات مختلفة، يوجد أدناه أمر يعمل على جهاز به 4 وحدات معالجة رسوميات A100 80G.
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 Falseتأتي بياناتنا من مصدرين رئيسيين:
تم نشر مجموعة من المؤلفات الأولية تحتوي على 6.0 مليون ورقة بحثية حول علوم المواد والكيمياء والفيزياء بعد عام 2000. ومن بين الناشرين ACS وRSC وSpringer Nature وWiley وElsevier. ونحن نشكرهم على دعمهم.
مجموعات بيانات FAIR - لقد جمعنا البيانات من 16 مجموعة بيانات FAIR.
قمنا بتطوير Darwin-SIG لتوليد تعليمات علمية. يمكنه حفظ النصوص الطويلة من النصوص الأدبية الكاملة (متوسط ~ 5000 كلمة) وإنشاء بيانات الأسئلة والأجوبة (Q&A) بناءً على الكلمات الرئيسية للأدب العلمي (من واجهة برمجة تطبيقات الويب للعلوم)
ملاحظة: يمكنك أيضًا استخدام GPT3.5 أو GPT-4 للإنشاء، ولكن هذه الخيارات قد تكون مكلفة.
يرجى العلم بأنه لا يمكننا مشاركة مجموعة بيانات التدريب بسبب الاتفاقيات المبرمة مع الناشرين.
هذا المشروع هو جهد تعاوني من قبل ما يلي:
جامعة نيو ساوث ويلز وGreenDynamics: تونغ شيه، شاوتشو وانغ
جامعة نيو ساوث ويلز: عمران رزاق، كودي هوانغ
مركز USYD & DARE: كلارا جرازيان
الديناميكيات الخضراء: يووي وان، ييشوان ليو
نصح برام هويكس ووينجي تشانغ من قسم الهندسة بجامعة نيو ساوث ويلز الجميع.
إذا كنت تستخدم البيانات أو التعليمات البرمجية من هذا المستودع في عملك، فيرجى الاستشهاد بها وفقًا لذلك.
DAWRIN نموذج اللغة التأسيسي الكبير والضبط الدقيق للتعليم شبه الذاتي
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GPT-3 وLLaMA المضبوطان لاكتشاف المواد (تدريب على مهمة واحدة)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
وقد أشار هذا المشروع إلى المشاريع مفتوحة المصدر التالية:
شكر خاص لشركة NCI Australia لدعمها لـ HPC.
نقوم باستمرار بتوسيع فريق تطوير داروين. انضم إلينا في هذه الرحلة المثيرة لتعزيز البحث العلمي باستخدام الذكاء الاصطناعي!
للحصول على مناصب الدكتوراه أو ما بعد الدكتوراه، يرجى التواصل مع [email protected] أو [email protected] للحصول على التفاصيل.
لشغل وظائف أخرى، يرجى زيارة www.greendynamics.com.au


