SwiftInfer
1.0.0
Streaming-LLM هي تقنية لدعم طول الإدخال اللانهائي لاستدلال LLM. إنه يعزز الانتباه لمنع انهيار النموذج عندما تتغير نافذة الانتباه. تم تنفيذ العمل الأصلي في PyTorch، ونحن نقدم SwiftInfer ، وهو تطبيق TensorRT لجعل StreamingLLM أكثر درجة إنتاجية. تم تنفيذ تطبيقنا بناءً على مشروع TensorRT-LLM الذي تم إصداره مؤخرًا.
نستخدم واجهة برمجة التطبيقات (API) في TensorRT-LLM لبناء النموذج وتشغيل الاستدلال. نظرًا لأن واجهة برمجة التطبيقات الخاصة بـ TensorRT-LLM ليست مستقرة وتتغير بسرعة، فإننا نربط تنفيذنا بالتزام 42af740db51d6f11442fd5509ef745a4c043ce51 الذي إصداره v0.6.0 . قد نقوم بترقية هذا المستودع عندما تصبح واجهات برمجة التطبيقات الخاصة بـ TensorRT-LLM أكثر استقرارًا.
إذا كان لديك الإصدار TensorRT-LLM V0.6.0 ، فما عليك سوى تشغيل:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .بخلاف ذلك، يجب عليك تثبيت TensorRT-LLM أولاً.
في حالة استخدام عامل الإرساء، يمكنك متابعة تثبيت TensorRT-LLM لتثبيت TensorRT-LLM V0.6.0 .
باستخدام عامل الإرساء، يمكنك تثبيت SwiftInfer ببساطة عن طريق تشغيل:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . في حالة عدم استخدام عامل الإرساء، فإننا نقدم برنامجًا نصيًا لتثبيت TensorRT-LLM تلقائيًا.
المتطلبات الأساسية
الرجاء التأكد من تثبيت الحزم التالية:
تأكد من أن إصدار TensorRT >= 9.1.0 ومجموعة أدوات CUDA >= 12.2.
لتثبيت Tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )لتنزيل nccl، اتبع صفحة تنزيل NCCL.
لتنزيل cudnn، اتبع صفحة تنزيل cuDNN.
الأوامر
قبل تشغيل الأوامر التالية، يرجى التأكد من أنك قمت بتعيين nvcc بشكل صحيح. للتحقق من ذلك، قم بتشغيل:
nvcc --versionلتثبيت TensorRT-LLM وSwiftInfer، قم بتشغيل:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . لتشغيل مثال Llama، تحتاج أولاً إلى استنساخ مستودع Hugging Face لنموذج meta-llama/Llama-2-7b-chat-hf أو المتغيرات الأخرى المستندة إلى Llama مثل lmsys/vicuna-7b-v1.3. بعد ذلك، يمكنك تشغيل الأمر التالي لإنشاء محرك TensorRT. أنت بحاجة إلى استبدال <model-dir> بالمسار الفعلي لنموذج Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1بعد ذلك، تحتاج إلى تنزيل بيانات MT-Bench المقدمة من LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlأخيرًا، أنت جاهز لتشغيل مثال Llama باستخدام الأمر التالي.
❗️❗️❗️ قبل ذلك يرجى ملاحظة ما يلي:
only_n_first للتحكم في عدد العينات التي سيتم تقييمها. إذا كنت تريد تقييم كافة العينات، الرجاء إزالة هذه الوسيطة. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
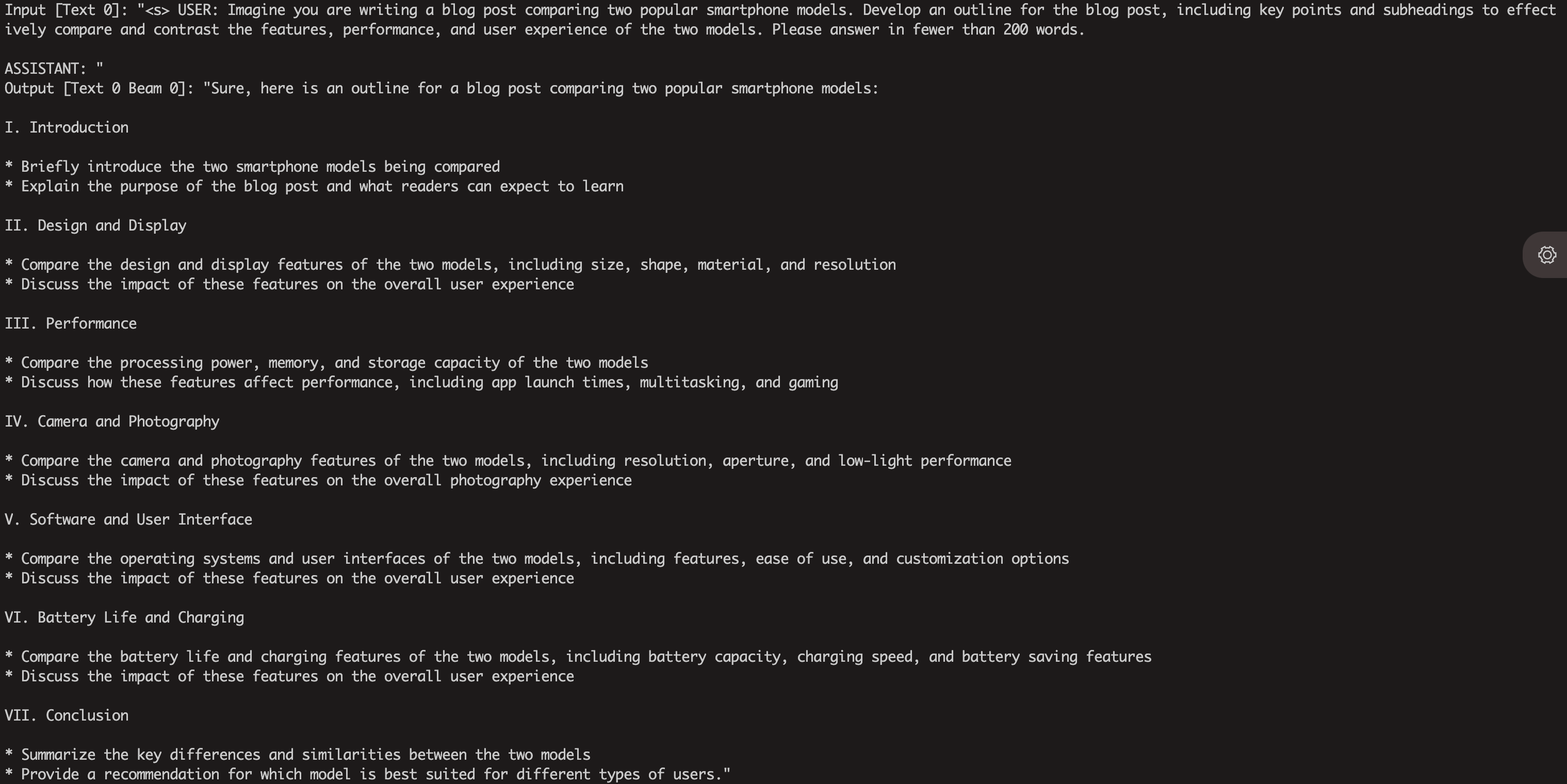
--only_n_first 5يجب أن تتوقع رؤية الجيل على النحو التالي:
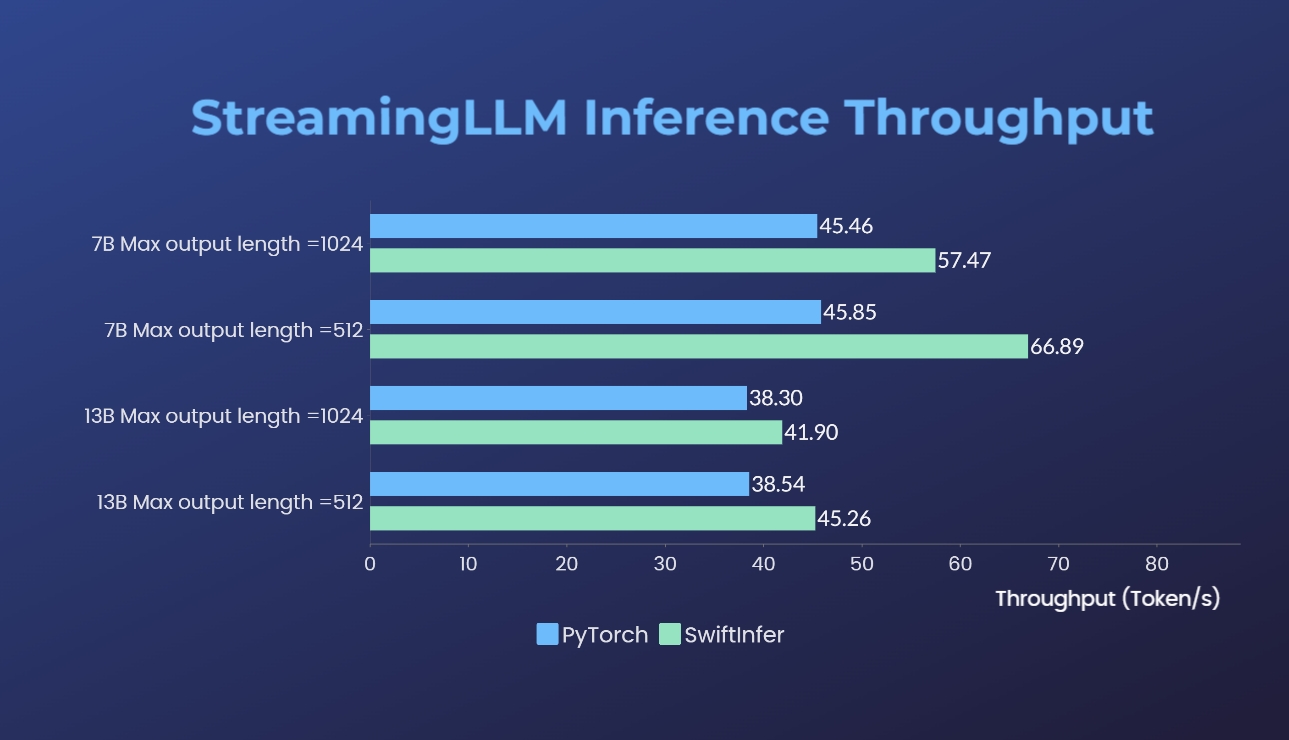
لقد قمنا بقياس تطبيقاتنا لـ Streaming-LLM مع إصدار PyTorch الأصلي. يتم تقديم الأمر المعياري لتطبيقنا في قسم مثال Run Llama بينما يتم تقديم ذلك الخاص بتطبيق PyTorch الأصلي في مجلد torch_streamingllm. الأجهزة المستخدمة مدرجة أدناه:
النتائج (20 جولة من المحادثات) هي:
ما زلنا نعمل على تحسين الأداء والتكيف مع واجهات برمجة التطبيقات TensorRT V0.7.1. نلاحظ أيضًا أن TensorRT-LLM قامت بدمج StreamingLLM في مثالهم ولكن يبدو أنها أكثر ملاءمة لإنشاء نص واحد بدلاً من المحادثات متعددة الجولات.
هذا العمل مستوحى من Streaming-LLM لجعله قابلاً للاستخدام في الإنتاج. طوال عملية التطوير، قمنا بالإشارة إلى المواد التالية ونرغب في الاعتراف بجهودهم ومساهمتهم في مجتمع المصادر المفتوحة والأوساط الأكاديمية.
إذا وجدت أن تطبيق StreamingLLM وتطبيق TensorRT الخاص بنا مفيد، فيرجى التكرم بالاستشهاد بمستودعنا والعمل الأصلي الذي اقترحه Xiao et al. من معهد ماساتشوستس للتكنولوجيا هان لاب.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

