paxml
paxml release 1.4.0
Pax هو إطار عمل لتكوين تجارب التعلم الآلي وتشغيلها أعلى Jax.
نشير إلى هذه الصفحة للحصول على وثائق أكثر شمولاً حول بدء مشروع Cloud TPU. يعد الأمر التالي كافيًا لإنشاء Cloud TPU VM مع 8 مراكز من جهاز الشركة.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR إذا كنت تستخدم شرائح TPU Pod، فيرجى الرجوع إلى هذا الدليل. قم بتشغيل جميع الأوامر من جهاز محلي باستخدام gcloud مع خيار --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "تفترض أقسام التشغيل السريع التالية أنك تعمل على جهاز TPU أحادي المضيف، لذا يمكنك الاتصال بالجهاز الظاهري وتشغيل الأوامر هناك.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEبعد ssh-ing VM، يمكنك تثبيت الإصدار المستقر paxml من PyPI، أو إصدار dev من github.
لتثبيت الإصدار الثابت من PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html إذا واجهت مشكلات تتعلق بالتبعيات المتعدية وكنت تستخدم بيئة Cloud TPU VM الأصلية، فيرجى الانتقال إلى فرع الإصدار المقابل rX.YZ وتنزيل paxml/pip_package/requirements.txt . يتضمن هذا الملف الإصدارات الدقيقة لجميع التبعيات المتعدية المطلوبة في بيئة Cloud TPU VM الأصلية، والتي نقوم فيها بإنشاء/اختبار الإصدار المقابل.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtلتثبيت إصدار المطورين من github، ولسهولة تحرير التعليمات البرمجية:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=Trueيرجى زيارة مجلد المستندات الخاص بنا للحصول على الوثائق والبرامج التعليمية لـ Jupyter Notebook. يرجى مراجعة القسم التالي للحصول على تعليمات تشغيل Jupyter Notebooks على جهاز Cloud TPU VM.
يمكنك تشغيل نماذج دفاتر الملاحظات في جهاز TPU VM الذي قمت بتثبيت paxml فيه للتو. ####خطوات لتمكين جهاز كمبيوتر محمول في الإصدار v4-8
ssh في TPU VM مع إعادة توجيه المنفذ gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
قم بتثبيت دفتر jupyter على جهاز TPU vm وقم بخفض مستوى Markupsafe
pip install notebook
pip install markupsafe==2.0.1
تصدير مسار jupyter export PATH=/home/$USER/.local/bin:$PATH
scp أمثلة دفاتر الملاحظات إلى جهاز TPU VM gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
ابدأ تشغيل دفتر jupyter من جهاز TPU VM ولاحظ الرمز المميز الذي تم إنشاؤه بواسطة دفتر jupyter jupyter notebook --no-browser --port=8080
ثم في متصفحك المحلي، انتقل إلى: http://localhost:8080/ وأدخل الرمز المميز المقدم
ملاحظة: إذا كنت بحاجة إلى البدء في استخدام دفتر ملاحظات ثانٍ بينما لا يزال الكمبيوتر الدفتري الأول يشغل وحدات TPU، فيمكنك تشغيل pkill -9 python3 لتحرير وحدات TPU.
ملاحظة: أصدرت NVIDIA إصدارًا محدثًا من Pax مع دعم H100 FP8 وتحسينات واسعة النطاق في أداء وحدة معالجة الرسومات. يرجى زيارة مستودع NVIDIA Rosetta لمزيد من التفاصيل وتعليمات الاستخدام.
يقيس سير عمل مقدر زمن الوصول الموجه للملف الشخصي (PGLE) وقت التشغيل الفعلي للحوسبة والمجموعات، ويتم تغذية معلومات الملف الشخصي مرة أخرى إلى مترجم XLA لاتخاذ قرار جدولة أفضل.
يمكن استخدام مقدر زمن الاستجابة الموجه للملف الشخصي يدويًا أو تلقائيًا. في الوضع التلقائي، سيقوم JAX بجمع معلومات الملف الشخصي وإعادة ترجمة الوحدة في عملية تشغيل واحدة. بينما في الوضع اليدوي، تحتاج إلى تشغيل مهمة مرتين، المرة الأولى لجمع ملفات التعريف وحفظها والثانية لتجميع البيانات المقدمة وتشغيلها.
يمكن تشغيل PGLE التلقائي عن طريق ضبط متغيرات البيئة التالية:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
أو في JAX يمكن ضبط ذلك على النحو التالي:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
يمكنك التحكم في مقدار عمليات إعادة التشغيل المستخدمة لجمع بيانات الملف الشخصي عن طريق تغيير JAX_PGLE_PROFILING_RUNS . قد تؤدي زيادة هذه المعلمة إلى معلومات أفضل للملف الشخصي، ولكنها ستؤدي أيضًا إلى زيادة مقدار خطوات التدريب غير المحسنة.
تسمح معلمات JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY باستخدام ردود اتصال المضيف مع PGLE التلقائي.
قد يساعد تقليل المعلمة JAX_PGLE_AGGREGATION_PERCENTILE في حالة ما إذا كان الأداء بين الخطوات صاخبًا جدًا بحيث لا يمكن تصفية المقاييس غير ذات الصلة.
انتبه: لا يعمل Auto PGLE مع الوحدات المترجمة مسبقًا. نظرًا لأن JAX بحاجة إلى إعادة ترجمة الوحدة أثناء التنفيذ، فإن PGLE التلقائي لن يعمل لا مع AoT ولا في الحالة التالية:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
إذا كنت لا تزال ترغب في استخدام أداة تقدير وقت الاستجابة اليدوية لملف التعريف، فإن سير العمل في XLA/GPU هو:
يمكنك القيام بذلك عن طريق الإعداد:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) بعد هذه الخطوة، سوف تحصل على ملف profile.pb ضمن rundir المطبوع في الكود.
تحتاج إلى تمرير ملف profile.pb إلى علامة --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " لتمكين تسجيل الدخول إلى XLA والتحقق مما إذا كان ملف التعريف جيدًا، قم بتعيين مستوى التسجيل ليشمل INFO :
export TF_CPP_MIN_LOG_LEVEL=0قم بتشغيل سير العمل الحقيقي، إذا وجدت عمليات التسجيل هذه في السجل الجاري تشغيله، فهذا يعني أنه تم استخدام ملف التعريف في برنامج جدولة إخفاء زمن الوصول:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
يعمل Pax على Jax، ويمكنك العثور على تفاصيل حول تشغيل وظائف Jax على Cloud TPU هنا، كما يمكنك العثور على تفاصيل حول تشغيل مهام Jax على حاوية Cloud TPU هنا
إذا واجهت أخطاء التبعية، فيرجى الرجوع إلى ملف requirements.txt في الفرع المقابل للإصدار الثابت الذي تقوم بتثبيته. على سبيل المثال، بالنسبة للإصدار المستقر 0.4.0، استخدم الفرع r0.4.0 وارجع إلى ملف Requirements.txt لمعرفة الإصدارات الدقيقة من التبعيات المستخدمة للإصدار المستقر.
فيما يلي بعض نماذج التقارب التي يتم تشغيلها على مجموعة بيانات c4.
يمكنك تشغيل نموذج معلمات 1B على مجموعة بيانات c4 على TPU v4-8 باستخدام التكوين C4Spmd1BAdam4Replicas من c4.py كما يلي:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > يمكنك ملاحظة منحنى الخسارة والرسم البياني log perplexity على النحو التالي:
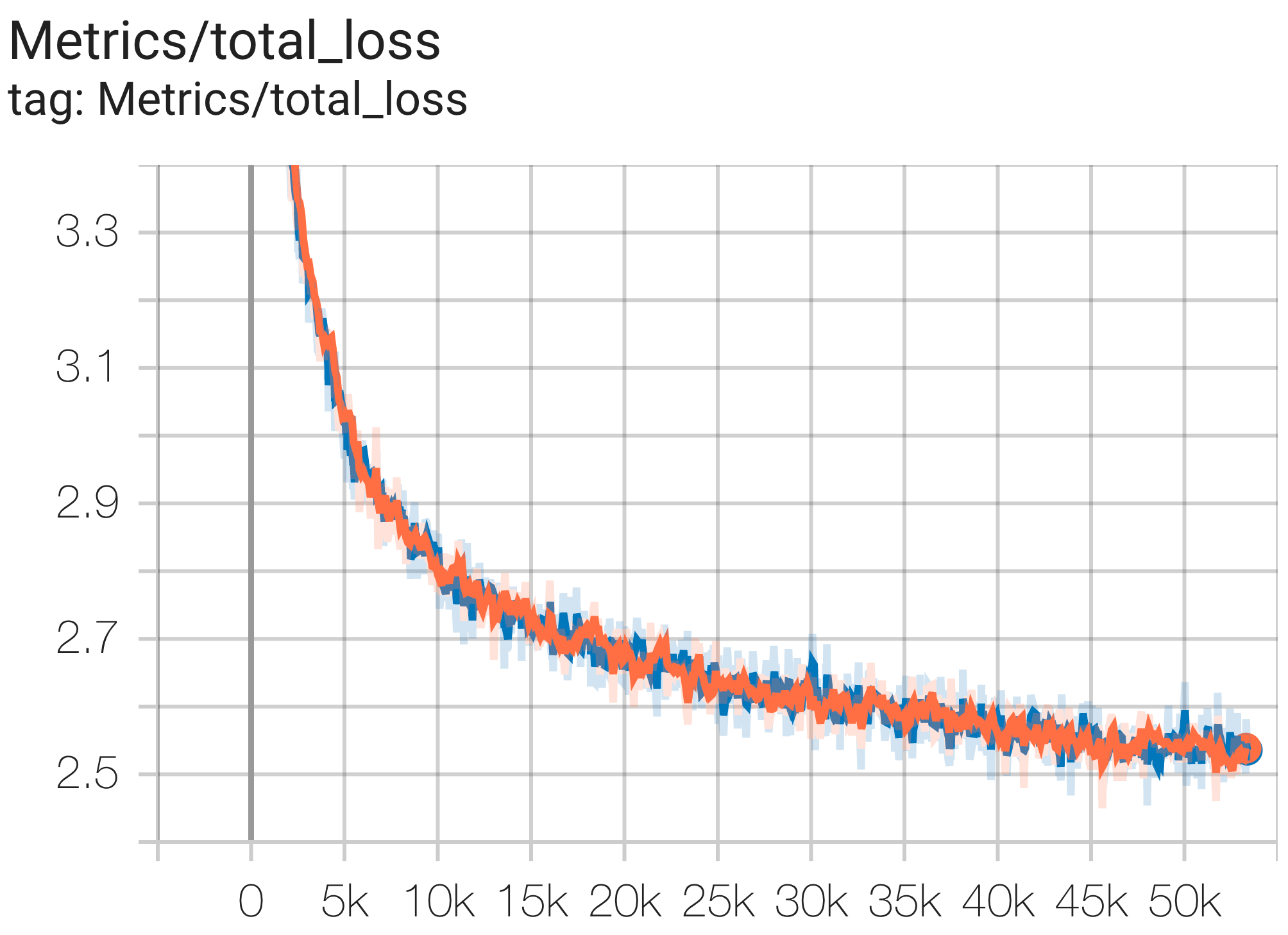
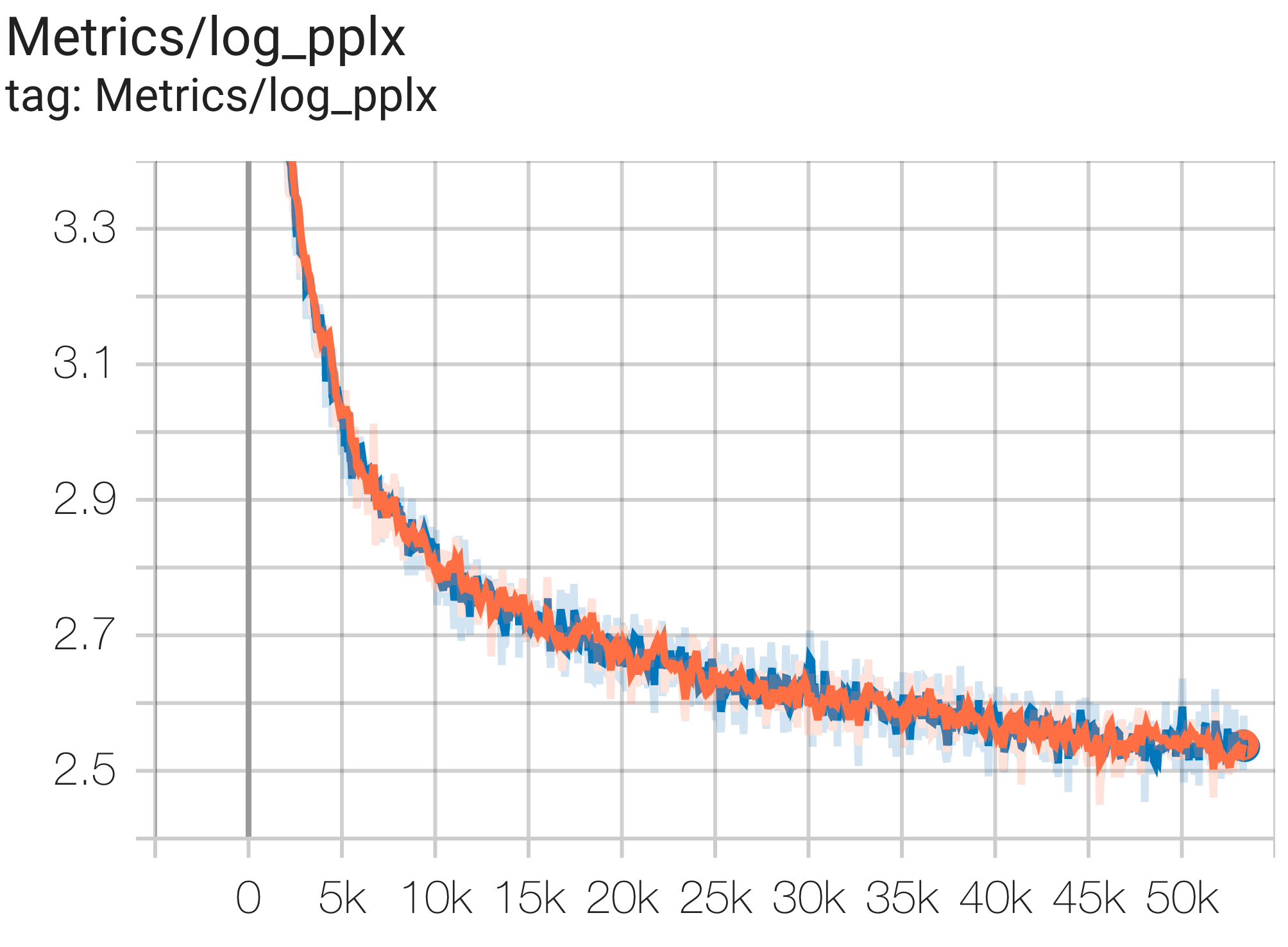
يمكنك تشغيل نموذج معلمات 16B على مجموعة بيانات c4 على TPU v4-64 باستخدام التكوين C4Spmd16BAdam32Replicas من c4.py كما يلي:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > يمكنك ملاحظة منحنى الخسارة والرسم البياني log perplexity على النحو التالي:
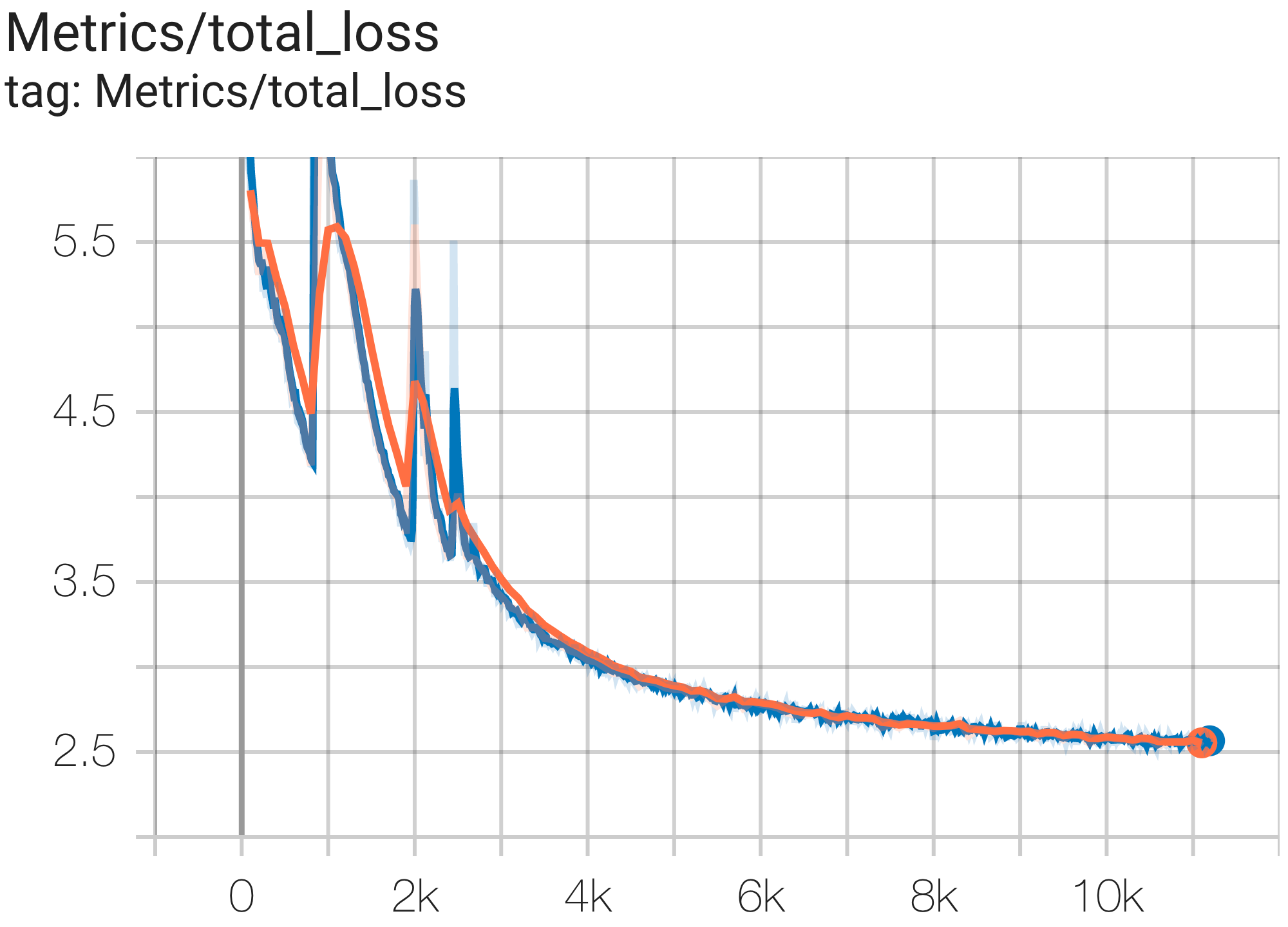
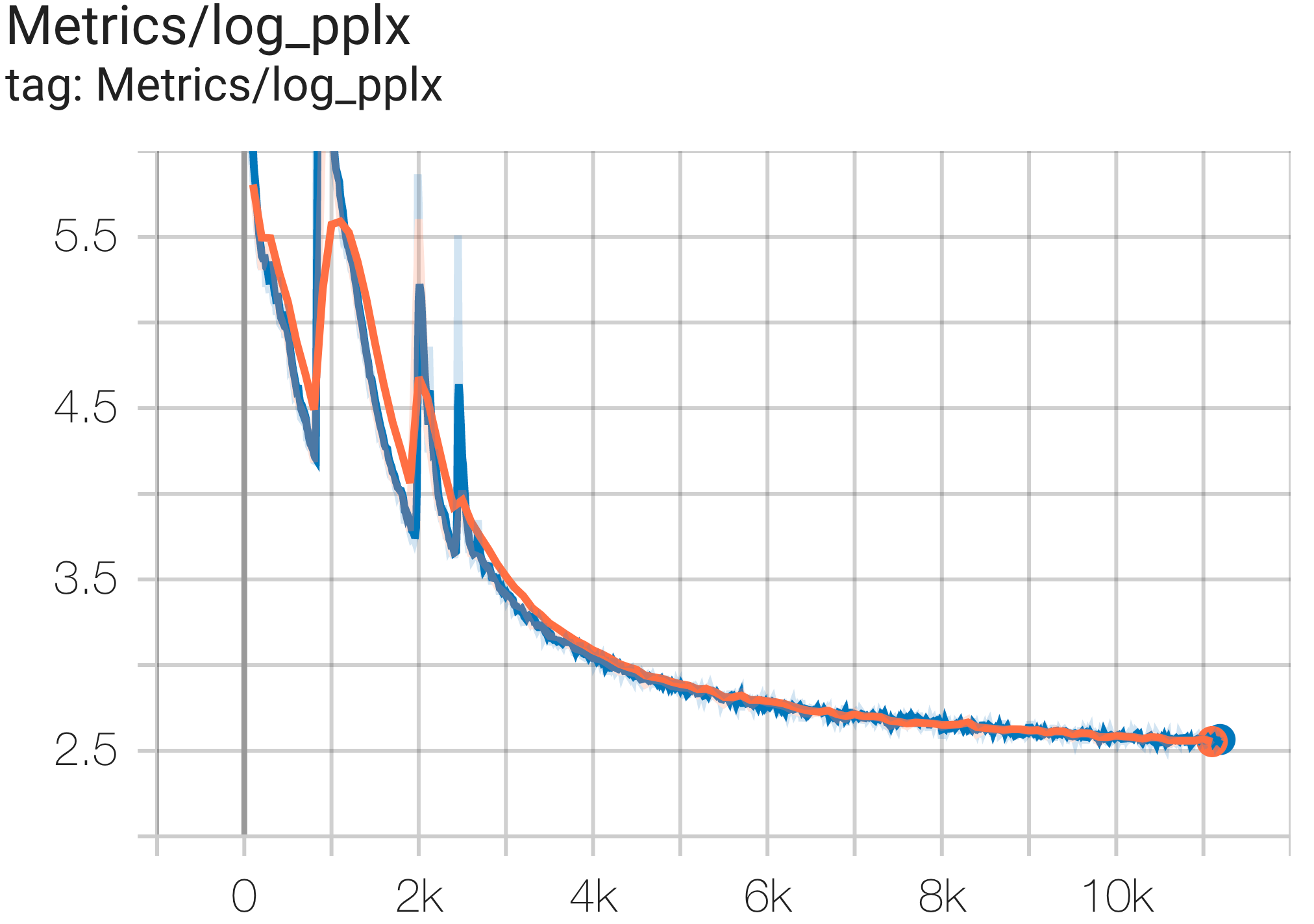
يمكنك تشغيل نموذج GPT3-XL على مجموعة بيانات c4 على TPU v4-128 باستخدام التكوين C4SpmdPipelineGpt3SmallAdam64Replicas من c4.py كما يلي:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > يمكنك ملاحظة منحنى الخسارة والرسم البياني log perplexity على النحو التالي:
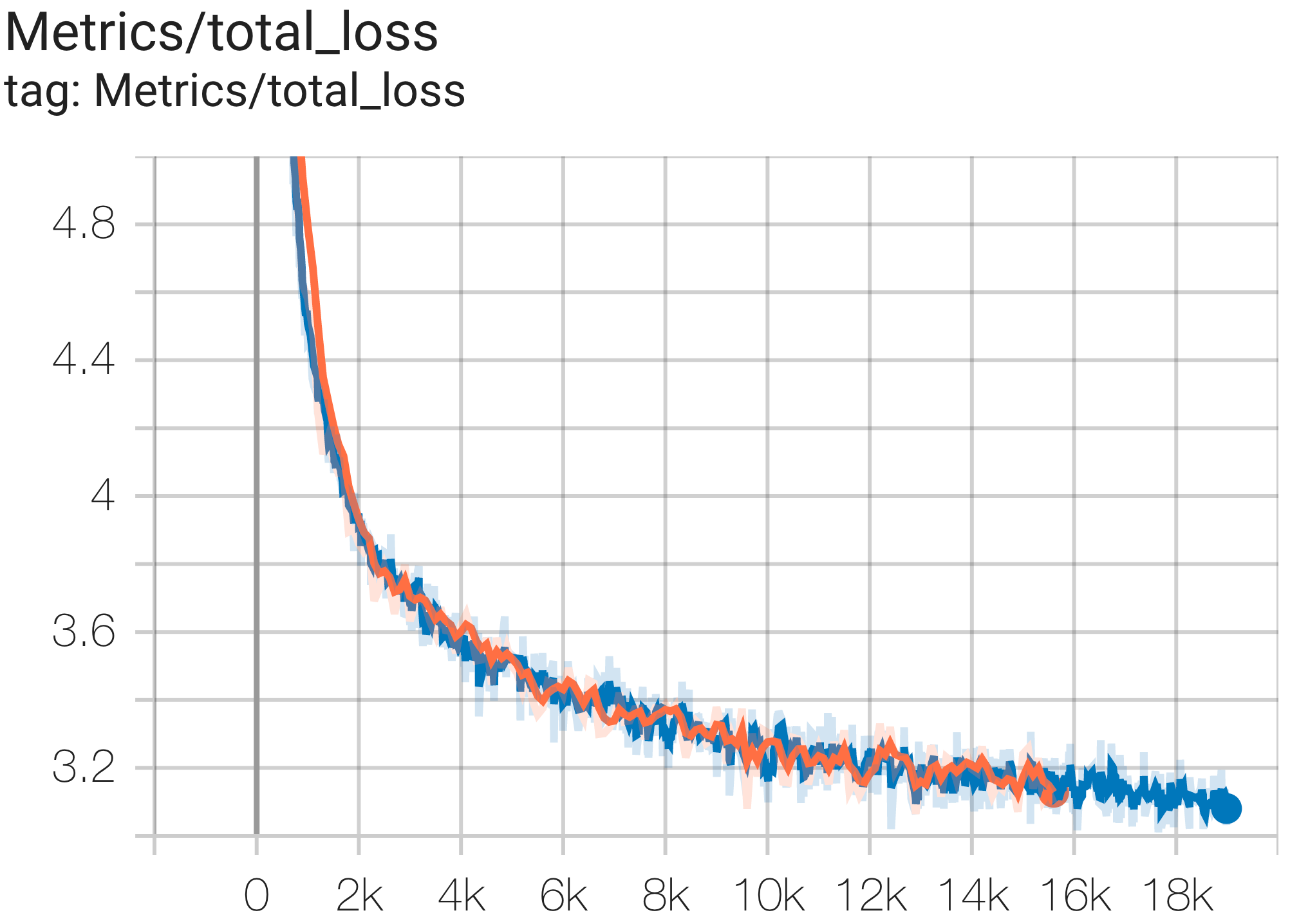
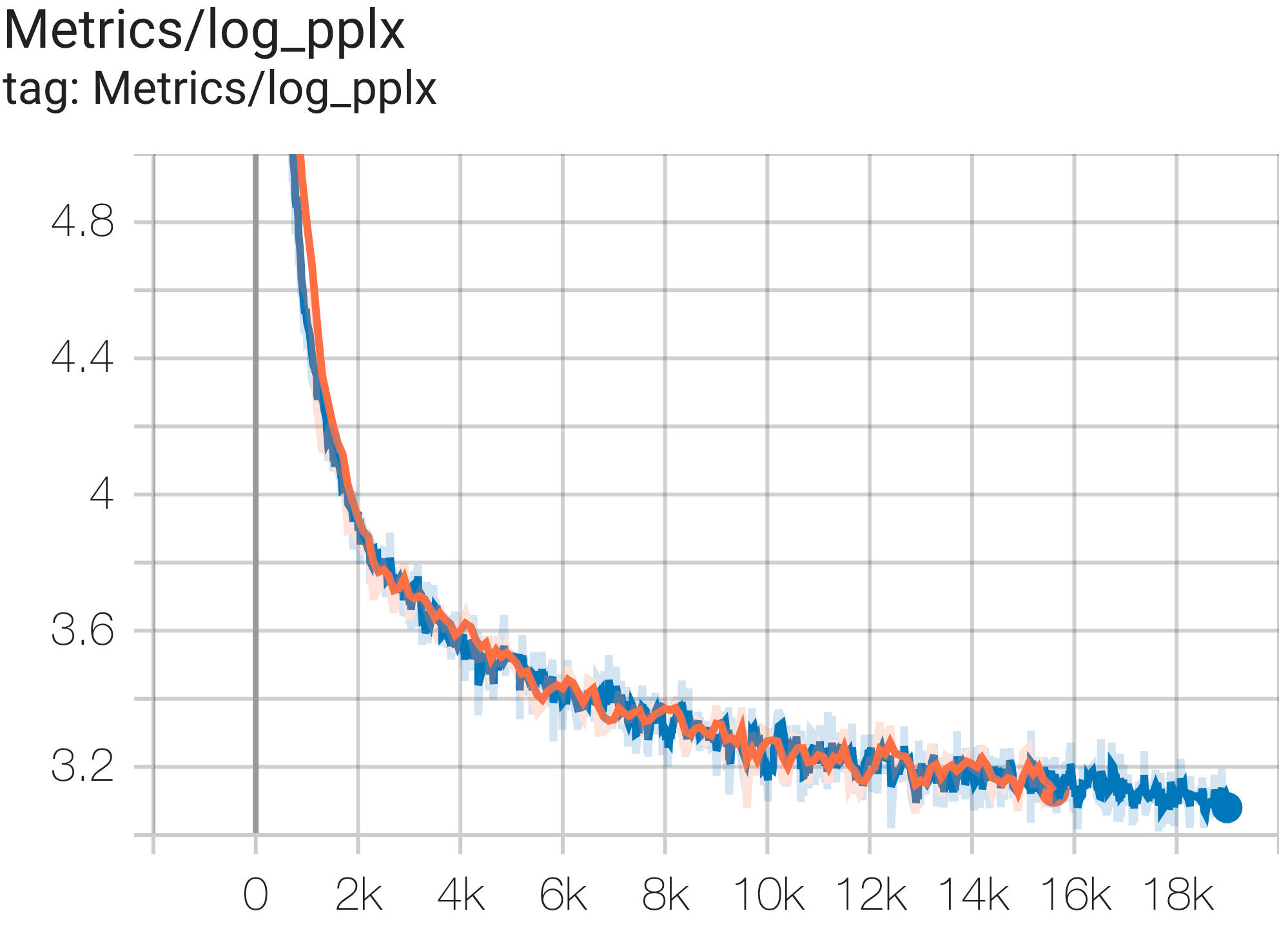
قدمت ورقة PaLM مقياسًا للكفاءة يسمى استخدام نموذج FLOPs (MFU). يتم قياس ذلك كنسبة من الإنتاجية المرصودة (على سبيل المثال، الرموز المميزة في الثانية لنموذج اللغة) إلى الحد الأقصى من الإنتاجية النظرية لنظام يستخدم 100% من ذروة FLOPs. وهو يختلف عن الطرق الأخرى لقياس استخدام الحوسبة لأنه لا يتضمن FLOPs التي تم إنفاقها على إعادة تجسيد التنشيط أثناء التمريرة الخلفية، مما يعني أن الكفاءة التي تم قياسها بواسطة MFU تترجم مباشرة إلى سرعة تدريب شاملة.
لتقييم MFU لفئة رئيسية من أعباء العمل على TPU v4 Pods مع Pax، قمنا بتنفيذ حملة قياس أداء متعمقة على سلسلة من تكوينات نموذج لغة المحولات (GPT) لوحدة فك التشفير فقط والتي تتراوح في الحجم من المليارات إلى تريليونات من المعلمات في مجموعة البيانات C4. يوضح الرسم البياني التالي كفاءة التدريب باستخدام نمط "التحجيم الضعيف" حيث قمنا بزيادة حجم النموذج بما يتناسب مع عدد الرقائق المستخدمة.
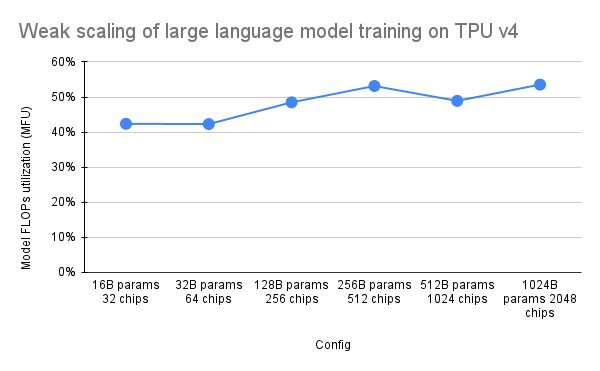
تشير تكوينات الشرائح المتعددة في هذا الريبو إلى 1. تكوينات الشريحة المفردة لبنية بناء الجملة/النموذج و2. MaxText repo لقيم التكوين.
نحن نقدم أمثلة على التشغيل ضمن c4_multislice.py` كنقطة بداية لـ Pax على multislice.
نشير إلى هذه الصفحة للحصول على وثائق أكثر شمولاً حول استخدام الموارد في قائمة الانتظار لمشروع Cloud TPU متعدد الشرائح. يوضح ما يلي الخطوات اللازمة لإعداد وحدات TPU لتشغيل أمثلة التكوينات في هذا الريبو.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run لنفترض أنه لتشغيل C4Spmd22BAdam2xv4_128 على شريحتين من الإصدار v4-128، ستحتاج إلى إعداد وحدات TPU بالطريقة التالية:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX يجب تشغيل أوامر الإعداد الموضحة سابقًا على جميع العاملين في جميع الشرائح. يمكنك 1) إدخال كل عامل وكل شريحة على حدة؛ أو 2) استخدم حلقة for مع علامة --worker=all كالأمر التالي.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done من أجل تشغيل تكوينات الشرائح المتعددة، افتح نفس عدد المحطات الطرفية مثل $NODE_COUNT الخاص بك. لإجراء تجاربنا على شريحتين ( C4Spmd22BAdam2xv4_128 )، افتح محطتين. ثم قم بتشغيل كل من هذه الأوامر بشكل فردي من كل محطة.
من الوحدة الطرفية 0، قم بتشغيل أمر التدريب للشريحة 0 كما يلي:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "من الوحدة الطرفية 1، قم بتشغيل أمر التدريب للشريحة 1 بشكل متزامن كما يلي:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "يغطي هذا الجدول تفاصيل حول كيفية ترجمة أسماء متغيرات MaxText إلى Pax.
لاحظ أن MaxText يحتوي على "مقياس" يتم ضربه في عدة معلمات (base_num_decoder_layers، base_emb_dim، base_mlp_dim، base_num_heads) للقيم النهائية.
شيء آخر يجب ذكره هو أنه بينما يغطي Pax DCN وICN MESH_SHAPE كمصفوفة، يوجد في MaxText متغيرات منفصلة لتوازي البيانات وfsdp_parallelism وtensor_parallelism لـ DCN وICI. نظرًا لأنه تم تعيين هذه القيم على 1 افتراضيًا، يتم تسجيل المتغيرات ذات القيمة الأكبر من 1 فقط في جدول الترجمة هذا.
وهذا يعني، ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] و DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| باكس C4Spmd22BAdam2xv4_128 | ماكس نص 2xv4-128.sh | (بعد تطبيق المقياس) | ||
|---|---|---|---|---|
| مقياس (يطبق على المتغيرات الأربعة التالية) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | vocab_size | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | حقيقي | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1، 64، 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2، 1، 1] | dcn_data_parallelism | 2 |
الإدخال هو مثيل لفئة BaseInput لإدخال البيانات في نموذج للتدريب/التقييم/فك التشفير.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass يعمل مثل المكرِّر: تقوم get_next() بإرجاع NestedMap ، حيث يكون كل حقل عبارة عن مصفوفة رقمية بحجم الدُفعة باعتباره البعد الرئيسي لها.
يتم تكوين كل إدخال بواسطة فئة فرعية من BaseInput.HParams . في هذه الصفحة، نستخدم p للإشارة إلى مثيل BaseInput.Params ، ويقوم بإنشاء مثيل input .
في Pax، تكون البيانات دائمًا متعددة المضيفين: سيكون لكل عملية Jax input منفصلة ومستقلة يتم إنشاء مثيل لها. ستحتوي معلماتها على p.infeed_host_index مختلف، ويتم تعيينه تلقائيًا بواسطة Pax.
ومن ثم، فإن حجم الدُفعة المحلي الذي يظهر على كل مضيف هو p.batch_size ، وحجم الدُفعة العام هو (p.batch_size * p.num_infeed_hosts) . غالبًا ما يرى المرء p.batch_size مضبوطًا على jax.local_device_count() * PERCORE_BATCH_SIZE .
نظرًا لطبيعة المضيف المتعدد هذه، يجب تقسيم input بشكل صحيح.
بالنسبة للتدريب، يجب ألا يصدر كل input دفعات متطابقة أبدًا، وللتقييم على مجموعة بيانات محدودة، يجب أن ينتهي كل input بعد نفس العدد من الدُفعات. الحل الأفضل هو تنفيذ الإدخال بشكل صحيح لتقسيم البيانات، بحيث لا يتداخل كل input على مضيفين مختلفين. في حالة فشل ذلك، يمكن للمرء أيضًا استخدام بذور عشوائية مختلفة لتجنب الدفعات المكررة أثناء التدريب.
لا يتم استدعاء input.reset() مطلقًا في بيانات التدريب، ولكن يمكن استخدامها لتقييم (أو فك تشفير) البيانات.
لكل عملية تقييم (أو فك تشفير)، يقوم Pax بجلب N دفعات من input عن طريق استدعاء input.get_next() N مرات. يمكن أن يكون عدد الدُفعات المستخدمة، N ، رقمًا ثابتًا يحدده المستخدم، عبر p.eval_loop_num_batches ؛ أو يمكن أن يكون N ديناميكيًا ( p.eval_loop_num_batches=None ) أي أننا نسمي input.get_next() حتى نستنفد جميع بياناته (من خلال رفع StopIteration أو tf.errors.OutOfRange ).
إذا كانت p.reset_for_eval=True ، فسيتم تجاهل p.eval_loop_num_batches ويتم تحديد N ديناميكيًا كعدد الدُفعات لاستنفاد البيانات. في هذه الحالة، يجب ضبط p.repeat على False، لأن القيام بخلاف ذلك سيؤدي إلى فك التشفير/التقييم اللانهائي.
إذا كانت p.reset_for_eval=False ، فسيقوم Pax بجلب دفعات p.eval_loop_num_batches . يجب ضبط ذلك على p.repeat=True حتى لا يتم استنفاد البيانات قبل الأوان.
لاحظ أن مدخلات LingvoEvalAdaptor تتطلب p.reset_for_eval=True .
N : ثابت | N : ديناميكي | |
|---|---|---|
p.reset_for_eval=True | يستخدم كل تشغيل تقييم | حقبة واحدة لكل تشغيل تقييم. |
: : دفعات N الأولى. لا : eval_loop_num_batches : | ||
| : : معتمد حتى الآن. : يتم تجاهله. يجب الإدخال: | ||
| :: : تكون محدودة : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | يستخدم كل تشغيل تقييم | غير معتمد. |
: : غير متداخلة N : : | ||
| :: دفعات على شكل متداول :: | ||
| : : الأساس ، حسب : : | ||
:: eval_loop_num_batches :: | ||
| : : . يجب تكرار الإدخال :: | ||
| ::: إلى أجل غير مسمى :: | ||
: : ( p.repeat=True ) أو : : | ||
| :: وإلا قد يرفع :: | ||
| : : استثناء : : |
في حالة تشغيل فك التشفير/التقييم في فترة واحدة بالضبط (أي عندما تكون p.reset_for_eval=True )، يجب أن يتعامل الإدخال مع التجزئة بشكل صحيح بحيث يتم رفع كل جزء في نفس الخطوة بعد إنتاج نفس العدد من الدُفعات بالضبط. وهذا يعني عادةً أن الإدخال يجب أن يحشو بيانات التقييم. يتم ذلك تلقائيًا بواسطة SeqIOInput و LingvoEvalAdaptor (انظر المزيد أدناه).
بالنسبة لغالبية المدخلات، فإننا نستدعي get_next() عليها فقط للحصول على دفعات من البيانات. يعد أحد أنواع بيانات التقييم استثناءً لذلك، حيث يتم أيضًا تعريف "كيفية حساب المقاييس" على كائن الإدخال أيضًا.
يتم دعم هذا فقط مع SeqIOInput الذي يحدد بعض معايير التقييم الأساسية. على وجه التحديد، يستخدم Pax predict_metric_fns و score_metric_fns() المحددين في مهمة SeqIO لحساب مقاييس التقييم (على الرغم من أن Pax لا يعتمد على مقيم SeqIO مباشرة).
عندما يستخدم النموذج مدخلات متعددة، إما بين التدريب/التقييم أو بيانات التدريب المختلفة بين التدريب المسبق/الضبط الدقيق، يجب على المستخدمين التأكد من أن الرموز المميزة التي تستخدمها المدخلات متطابقة، خاصة عند استيراد مدخلات مختلفة ينفذها الآخرون.
يمكن للمستخدمين التحقق من سلامة الرموز المميزة عن طريق فك تشفير بعض المعرفات باستخدام input.ids_to_strings() .
من الجيد دائمًا التحقق من صحة البيانات من خلال النظر في دفعات قليلة. يمكن للمستخدمين بسهولة إعادة إنتاج المعلمة في colab وفحص البيانات:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) يجب ألا تستخدم بيانات التدريب عادةً بذرة عشوائية ثابتة. وذلك لأنه إذا تم استباق مهمة التدريب، فستبدأ بيانات التدريب في تكرار نفسها. على وجه الخصوص، بالنسبة لمدخلات Lingvo، نوصي بتعيين p.input.file_random_seed = 0 لبيانات التدريب.
لاختبار ما إذا كان يتم التعامل مع التجزئة بشكل صحيح، يمكن للمستخدمين تعيين قيم مختلفة يدويًا لـ p.num_infeed_hosts, p.infeed_host_index ومعرفة ما إذا كانت المدخلات التي تم إنشاء مثيل لها تصدر دفعات مختلفة.
يدعم Pax ثلاثة أنواع من المدخلات: SeqIO، وLingvo، والمخصص.
يمكن استخدام SeqIOInput لاستيراد مجموعات البيانات.
تتعامل مدخلات SeqIO مع التقسيم الصحيح وحشو بيانات التقييم تلقائيًا.
يمكن استخدام LingvoInputAdaptor لاستيراد مجموعات البيانات.
يتم تفويض الإدخال بالكامل إلى تطبيق Lingvo، والذي قد يتعامل أو لا يتعامل مع التجزئة تلقائيًا.
بالنسبة لتنفيذ إدخال Lingvo القائم على GenericInput باستخدام packing_factor الثابت، نوصي باستخدام LingvoInputAdaptorNewBatchSize لتحديد حجم دفعة أكبر لإدخال Lingvo الداخلي ووضع حجم الدفعة المرغوب فيه (أصغر كثيرًا عادةً) على p.batch_size .
بالنسبة لبيانات التقييم، نوصي باستخدام LingvoEvalAdaptor للتعامل مع التجزئة والحشوة لتشغيل التقييم على مدى فترة واحدة.
فئة فرعية مخصصة من BaseInput . يقوم المستخدمون بتنفيذ الفئة الفرعية الخاصة بهم، عادةً باستخدام tf.data أو SeqIO.
يمكن للمستخدمين أيضًا وراثة فئة إدخال موجودة لتخصيص المعالجة اللاحقة للدُفعات فقط. على سبيل المثال:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchتعد المعلمات الفائقة جزءًا مهمًا من تحديد النماذج وتكوين التجارب.
للتكامل بشكل أفضل مع أدوات Python، يستخدم Pax/Praxis نمط تكوين قائم على فئة بيانات Python للمعلمات الفائقة.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0من الممكن أيضًا تداخل فئات بيانات HParams، في المثال أدناه، تكون السمة Linear_tpl عبارة عن Linear.HParams متداخلة.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )تمثل الطبقة وظيفة عشوائية ربما تحتوي على معلمات قابلة للتدريب. يمكن أن تحتوي الطبقة على طبقات أخرى كأبناء. الطبقات هي اللبنات الأساسية للنماذج. ترث الطبقات من الكتان nn.Module.
عادةً ما تحدد الطبقات طريقتين:
تقوم هذه الطريقة بإنشاء أوزان قابلة للتدريب وطبقات فرعية.
تحدد هذه الطريقة وظيفة الانتشار الأمامي، وتحسب بعض المخرجات بناءً على المدخلات. بالإضافة إلى ذلك، قد يضيف fprop ملخصات أو يتتبع الخسائر المساعدة.
Fiddle هي مكتبة تكوين Python-first مفتوحة المصدر مصممة لتطبيقات ML. يدعم Pax/Praxis إمكانية التشغيل التفاعلي مع Fiddle Config/Partial(s) وبعض الميزات المتقدمة مثل التحقق من الأخطاء والمعلمات المشتركة.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )باستخدام Fiddle، يمكن تكوين الطبقات ليتم مشاركتها (على سبيل المثال: إنشاء مثيل لها مرة واحدة فقط باستخدام الأوزان المشتركة القابلة للتدريب).
يحدد النموذج الشبكة فقط، وعادة ما تكون عبارة عن مجموعة من الطبقات ويحدد واجهات للتفاعل مع النموذج مثل فك التشفير، وما إلى ذلك.
تتضمن بعض الأمثلة على النماذج الأساسية ما يلي:
تحتوي المهمة على نموذج إضافي ومُحسّن/متعلم. أبسط فئة فرعية للمهام هي SingleTask والتي تتطلب Hparams التالية:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| نسخة باي بي آي | يقترف |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


