distrifuser
v0.0.1beta0
[29 يوليو 2024] يتم دعم DistriFusion في ColossalAI!
[4 أبريل 2024] تم اختيار DistriFusion كملصق مميز في CVPR 2024!
[29 فبراير 2024] تم قبول DistriFusion بواسطة CVPR 2024! الكود الخاص بنا متاح للعامة!
 نحن نقدم DistriFusion، وهي خوارزمية خالية من التدريب لتسخير وحدات معالجة الرسومات المتعددة لتسريع استنتاج نموذج الانتشار دون التضحية بجودة الصورة. يعاني Naïve Patch (نظرة عامة (ب)) من مشكلة التجزئة بسبب قلة تفاعل التصحيح. يتم إنشاء الأمثلة المقدمة باستخدام SDXL باستخدام جهاز أخذ عينات Euler من 50 خطوة بدقة 1280×1920، ويتم قياس زمن الوصول على وحدات معالجة الرسومات A100.
نحن نقدم DistriFusion، وهي خوارزمية خالية من التدريب لتسخير وحدات معالجة الرسومات المتعددة لتسريع استنتاج نموذج الانتشار دون التضحية بجودة الصورة. يعاني Naïve Patch (نظرة عامة (ب)) من مشكلة التجزئة بسبب قلة تفاعل التصحيح. يتم إنشاء الأمثلة المقدمة باستخدام SDXL باستخدام جهاز أخذ عينات Euler من 50 خطوة بدقة 1280×1920، ويتم قياس زمن الوصول على وحدات معالجة الرسومات A100.
التوزيع: الاستدلال الموازي الموزع لنماذج الانتشار عالية الدقة
مويانغ لي*، تيانلي كاي*، جياكسين كاو، تشينشينغ تشانغ، هان كاي، جونجي باي، يانغ تشينغ جيا، مينغ يو ليو، كاي لي، وسونغ هان
معهد ماساتشوستس للتكنولوجيا، برينستون، ليبتون AI، ونفيديا
في CVPR 2024.
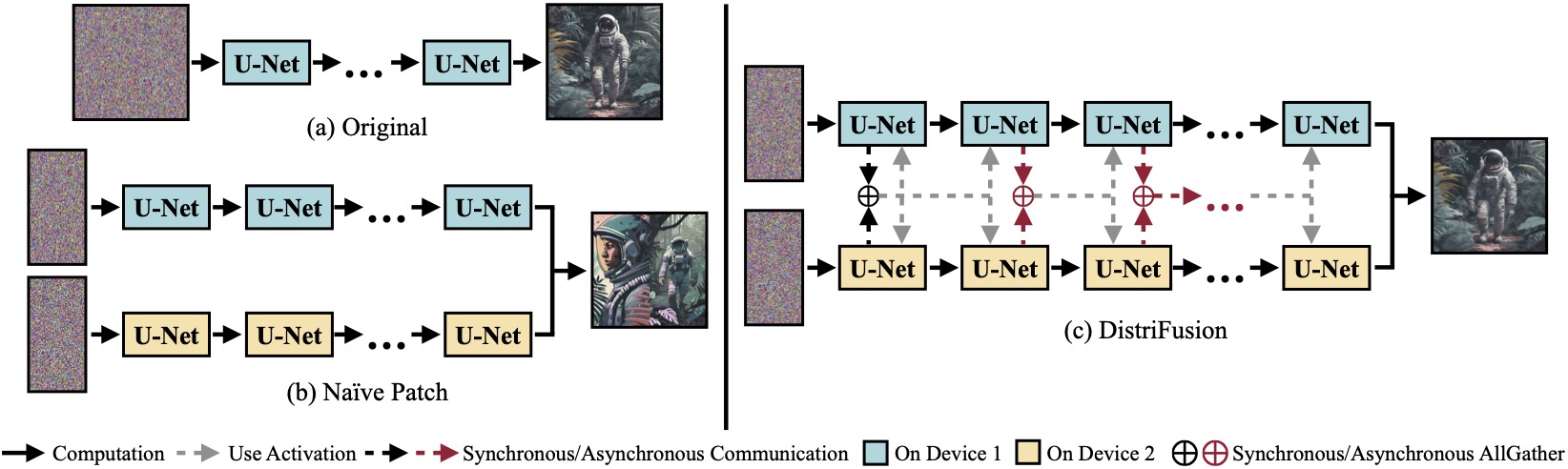 (أ) نموذج الانتشار الأصلي الذي يعمل على جهاز واحد. (ب) إن تقسيم الصورة بسذاجة إلى رقعتين عبر وحدتي معالجة رسوميات له خط واضح عند الحدود بسبب غياب التفاعل عبر الرقع. (ج) يستخدم DistriFusion الخاص بنا الاتصال المتزامن لتفاعل التصحيح في الخطوة الأولى. بعد ذلك، نعيد استخدام التنشيطات من الخطوة السابقة عبر الاتصال غير المتزامن. بهذه الطريقة، يمكن إخفاء عبء الاتصالات في مسار الحساب.
(أ) نموذج الانتشار الأصلي الذي يعمل على جهاز واحد. (ب) إن تقسيم الصورة بسذاجة إلى رقعتين عبر وحدتي معالجة رسوميات له خط واضح عند الحدود بسبب غياب التفاعل عبر الرقع. (ج) يستخدم DistriFusion الخاص بنا الاتصال المتزامن لتفاعل التصحيح في الخطوة الأولى. بعد ذلك، نعيد استخدام التنشيطات من الخطوة السابقة عبر الاتصال غير المتزامن. بهذه الطريقة، يمكن إخفاء عبء الاتصالات في مسار الحساب.
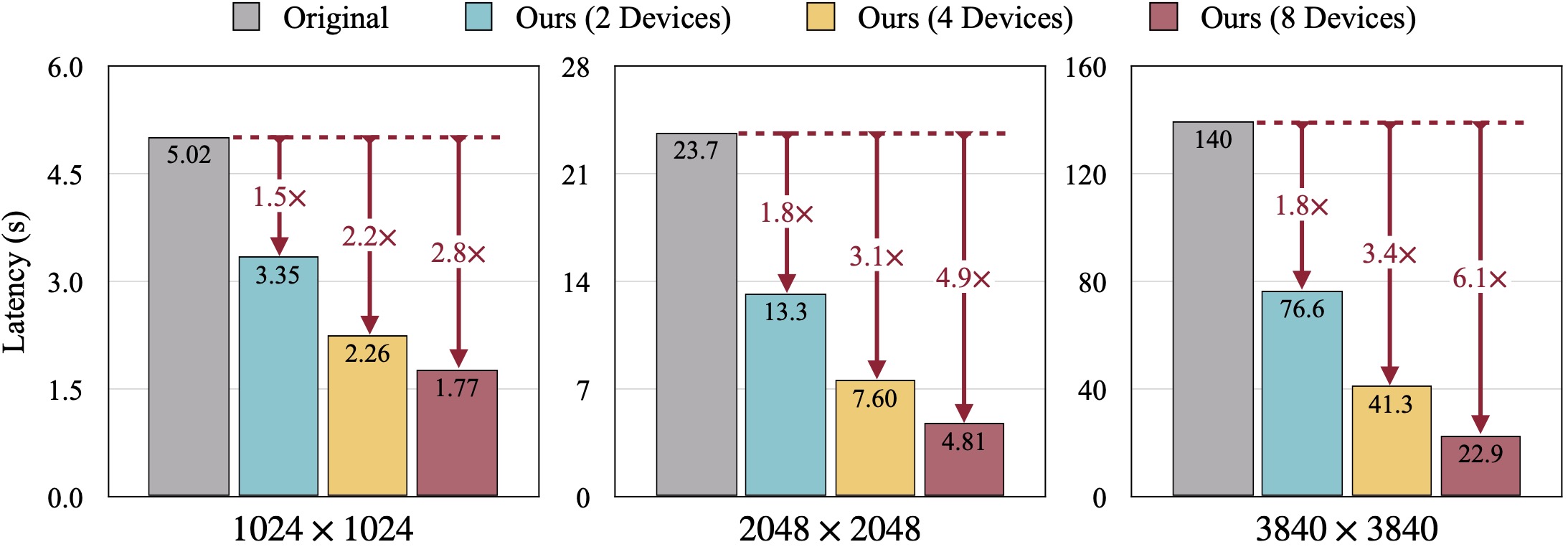
 النتائج النوعية لSDXL. يتم حساب FID مقابل صور الحقيقة الأرضية. يمكن لـ DistriFusion الخاص بنا تقليل زمن الوصول وفقًا لعدد الأجهزة المستخدمة مع الحفاظ على الدقة البصرية.
النتائج النوعية لSDXL. يتم حساب FID مقابل صور الحقيقة الأرضية. يمكن لـ DistriFusion الخاص بنا تقليل زمن الوصول وفقًا لعدد الأجهزة المستخدمة مع الحفاظ على الدقة البصرية.
مراجع:
بعد تثبيت PyTorch، يجب أن تكون قادرًا على تثبيت distrifuser باستخدام PyPI
pip install distrifuserأو عبر جيثب:
pip install git+https://github.com/mit-han-lab/distrifuser.gitأو محليا من أجل التنمية
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . في scripts/sdxl_example.py ، نوفر برنامجًا نصيًا بسيطًا لتشغيل SDXL مع DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) على وجه التحديد، يشترك distrifuser الخاص بنا في نفس واجهات برمجة التطبيقات مثل الموزعات ويمكن استخدامه بطريقة مماثلة. كل ما عليك فعله هو تحديد DistriConfig واستخدام DistriSDXLPipeline المغلف لتحميل نموذج SDXL المُدرب مسبقًا. بعد ذلك، يمكننا إنشاء الصورة مثل StableDiffusionXLPipeline في الناشرات. أمر التشغيل هو
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py حيث $N_GPUS هو عدد وحدات معالجة الرسومات التي تريد استخدامها.
نوفر أيضًا الحد الأدنى من البرامج النصية لتشغيل SD1.4/2 مع DistriFusion في scripts/sd_example.py . الاستخدام هو نفسه.
تستخدم نتائجنا المعيارية PyTorch 2.2 والناشرين 0.24.0. أولاً، قد تحتاج إلى تثبيت بعض التبعيات الإضافية:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid يمكنك استخدام scripts/generate_coco.py لإنشاء صور تحتوي على تسميات توضيحية لـ COCO. الأمر هو
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
حيث $N_GPUS هو عدد وحدات معالجة الرسومات التي تريد استخدامها. افتراضيًا، سيتم تخزين النتائج التي تم إنشاؤها في results/coco . يمكنك أيضًا تخصيصه باستخدام --output_root . بعض الوسائط الإضافية التي قد ترغب في ضبطها:
--num_inference_steps : عدد خطوات الاستدلال. نحن نستخدم 50 بشكل افتراضي.--guidance_scale : مقياس التوجيه الخالي من المصنف. نحن نستخدم 5 بشكل افتراضي.--scheduler : أخذ العينات الانتشار. نحن نستخدم أداة أخذ العينات DDIM بشكل افتراضي. يمكنك أيضًا استخدام euler لأخذ عينات Euler و dpm-solver لمحلول DPM.--warmup_steps : عدد خطوات الإحماء الإضافية (4 بشكل افتراضي).--sync_mode : أوضاع مزامنة GroupNorm المختلفة. افتراضيًا، يستخدم GroupNorm غير المتزامن الذي تم تصحيحه.--parallelism : نموذج التوازي الذي تستخدمه. بشكل افتراضي، هو تصحيح التوازي. يمكنك استخدام tensor لتوازي الموتر و naive_patch للتصحيح الساذج. بعد إنشاء جميع الصور، يمكنك استخدام scripts/compute_metrics.py الخاص بنا لحساب PSNR وLPIPS وFID. الاستخدام هو
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 حيث يكون $IMAGE_ROOT0 و $IMAGE_ROOT1 عبارة عن مسارات لمجلدات الصور التي تحاول مقارنتها. إذا كان IMAGE_ROOT0 هو مجلد الحقيقة الأساسية، فيرجى إضافة علامة --is_gt لتغيير الحجم. نوفر أيضًا scripts/dump_coco.py لتفريغ صور الحقيقة الأرضية.
يمكنك استخدام scripts/run_sdxl.py لقياس زمن الاستجابة بطرقنا المختلفة. الأمر هو
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent حيث $N_GPUS هو عدد وحدات معالجة الرسومات التي تريد استخدامها. كما هو الحال مع scripts/generate_coco.py ، يمكنك أيضًا تغيير بعض الوسائط:
--num_inference_steps : عدد خطوات الاستدلال. نحن نستخدم 50 بشكل افتراضي.--image_size : حجم الصورة التي تم إنشاؤها. بشكل افتراضي، هو 1024×1024.--no_split_batch : قم بتعطيل تقسيم الدُفعات للحصول على إرشادات خالية من المصنف.--warmup_steps : عدد خطوات الإحماء الإضافية (4 بشكل افتراضي).--sync_mode : أوضاع مزامنة GroupNorm المختلفة. افتراضيًا، يستخدم GroupNorm غير المتزامن الذي تم تصحيحه.--parallelism : نموذج التوازي الذي تستخدمه. بشكل افتراضي، هو تصحيح التوازي. يمكنك استخدام tensor لتوازي الموتر و naive_patch للتصحيح الساذج.--warmup_times / --test_times : عدد مرات تشغيل الإحماء/الاختبار. بشكل افتراضي، هما 5 و 20 على التوالي. إذا كنت تستخدم هذا الرمز لبحثك، يرجى الاستشهاد بمقالتنا.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}تم تطوير الكود الخاص بنا استنادًا إلى Huggingface/diffusers وlmxyy/sige. نشكر torchprofile لقياس أجهزة MAC، والتنظيف الدقيق لحساب FID وLightning-AI/torchmetrics لـ PSNR وLPIPS.
نشكر Jun-Yan Zhu وLigeng Zhu على مناقشتهما المفيدة وملاحظاتهما القيمة. يتم دعم المشروع من قبل MIT-IBM Watson AI Lab، وأمازون، وMIT Science Hub، والمؤسسة الوطنية للعلوم.


