GenerativeRL
v0.0.1
الإنجليزية | 简体中文(الصينية المبسطة)
GeneativeRL ، اختصار لـ Geneative Reinforcement Learning، هي مكتبة بايثون لحل مشاكل التعلم المعزز (RL) باستخدام النماذج التوليدية، مثل نماذج الانتشار ونماذج التدفق. تهدف هذه المكتبة إلى توفير إطار عمل للجمع بين قوة النماذج التوليدية وقدرات اتخاذ القرار لخوارزميات التعلم المعزز.
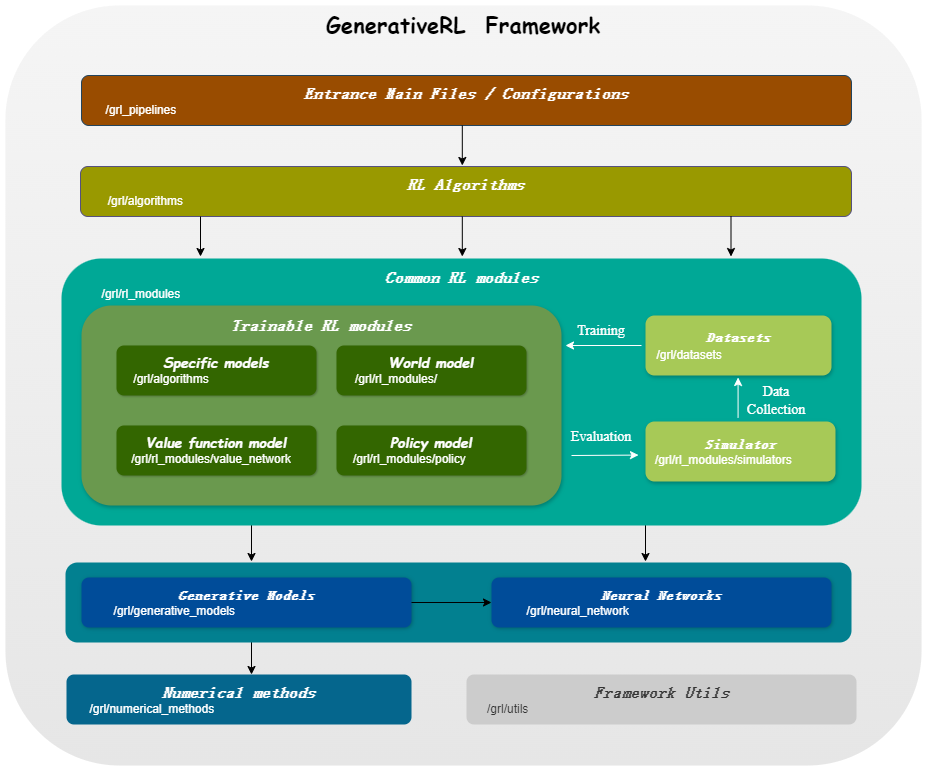
| مطابقة النتيجة | مطابقة التدفق | |
|---|---|---|
| نموذج الانتشار | ||
| نائب الرئيس الخطي SDE | ✔ | ✔ |
| المعمم نائب الرئيس SDE | ✔ | ✔ |
| SDE الخطي | ✔ | ✔ |
| نموذج التدفق | ||
| مطابقة التدفق الشرطي المستقل | ✔ | |
| مطابقة التدفق الشرطي الأمثل للنقل | ✔ |
| ألغو./نماذج | نموذج الانتشار | نموذج التدفق |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| جي إم بي جي | ✔ | ✔ |
pip install GenerativeRLأو إذا كنت تريد التثبيت من المصدر:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .أو يمكنك استخدام صورة عامل الإرساء:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashفيما يلي مثال لكيفية تدريب نموذج نشر لتحسين السياسة الموجهة Q (QGPO) في بيئة LunarLanderContinious-v2 باستخدام GeneativeRL.
تثبيت التبعيات المطلوبة:
pip install ' gym[box2d]==0.23.1 '(يمكن أن يكون إصدار الصالة الرياضية من 0.23 إلى 0.25 لبيئات box2d، ولكن يوصى باستخدام 0.23.1 للتوافق مع D4RL.)
قم بتنزيل مجموعة البيانات من هنا واحفظها باسم data.npz في الدليل الحالي.
يستخدم GeneativeRL WandB للتسجيل. سيطلب منك تسجيل الدخول إلى حسابك عند استخدامه. يمكنك تعطيله عن طريق تشغيل:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )للحصول على أمثلة ووثائق أكثر تفصيلاً، يرجى الرجوع إلى وثائق GeneativeRL.
يمكن العثور على الوثائق الكاملة لـ GeneativeRL في وثائق GeneativeRL.
نحن نقدم العديد من البرامج التعليمية للحالة لمساعدتك على فهم GeneativeRL بشكل أفضل. رؤية المزيد في الدروس.
نحن نقدم بعض التجارب الأساسية لتقييم أداء خوارزميات التعلم المعزز التوليدي. رؤية المزيد في المعيار.
نحن نرحب بالمساهمات في GeneativeRL! إذا كنت مهتمًا بالمساهمة، فيرجى الرجوع إلى دليل المساهمة.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}تم ترخيص GeneativeRL بموجب ترخيص Apache 2.0. راجع الترخيص لمزيد من التفاصيل.


