open_llama
1.0.0
TL;DR : نحن نصدر معاينتنا العامة لـ OpenLLaMA، وهي نسخة مفتوحة المصدر مرخصة بشكل مسموح لـ LLaMA الخاصة بـ Meta AI. نحن نصدر سلسلة من النماذج 3B و7B و13B المدربة على مجموعات مختلفة من البيانات. يمكن أن تكون أوزان النماذج الخاصة بنا بمثابة انخفاض في استبدال LLaMA في التطبيقات الحالية.
في هذا الريبو، نقدم نسخة مفتوحة المصدر مرخصة بشكل مسموح لنموذج اللغة الكبير LLaMA الخاص بـ Meta AI. نحن نصدر سلسلة من النماذج 3B و7B و13B المدربة على رموز 1T. نحن نقدم أوزان PyTorch وJAX لنماذج OpenLLaMA المدربة مسبقًا، بالإضافة إلى نتائج التقييم والمقارنة مع نماذج LLaMA الأصلية. يعد نموذج v2 أفضل من نموذج v1 القديم الذي تم تدريبه على خليط بيانات مختلف.
نحن نصدر نموذج OpenLLaMA 3Bv3، وهو نموذج 3B تم تدريبه على رموز 1T على نفس خليط مجموعة البيانات مثل نموذج 7Bv2.
يسعدنا إطلاق نموذج OpenLLaMA 7Bv2، الذي تم تدريبه على مزيج من مجموعة بيانات الويب المكررة من Falcon، والممزوجة بمجموعة بيانات Starcoder، وويكيبيديا، وarxiv، والكتب وتبادل المكدس من RedPajama.
يسعدنا إطلاق إصدارنا النهائي من رمز 1T من OpenLLaMA 13B. لقد قمنا بتحديث نتائج التقييم. بالنسبة للإصدار الحالي من نماذج OpenLLaMA، تم تدريب برنامج الرمز المميز الخاص بنا على دمج عدة مساحات فارغة في مساحة واحدة قبل إنشاء الرمز المميز، على غرار رمز T5 المميز. ولهذا السبب، لن يعمل برنامج الرمز المميز الخاص بنا مع مهام إنشاء التعليمات البرمجية (مثل HumanEval) نظرًا لأن التعليمات البرمجية تتضمن العديد من المساحات الفارغة. بالنسبة للمهام المتعلقة بالرمز، يرجى استخدام نماذج v2.
يسعدنا إطلاق إصدارنا النهائي من رمز 1T من OpenLLaMA 3B و7B. لقد قمنا بتحديث نتائج التقييم. يسعدنا أيضًا إصدار معاينة رمزية بحجم 600 مليار لنموذج 13B، والتي تم تدريبها بالتعاون مع Stability AI.
يسعدنا إطلاق نقطة تفتيش الرمز المميز 700B الخاصة بنا لنموذج OpenLLaMA 7B ونقطة تفتيش الرمز المميز 600B للنموذج 3B. لقد قمنا أيضًا بتحديث نتائج التقييم. نتوقع أن ينتهي التدريب الكامل لرمز 1T في نهاية هذا الأسبوع.
بعد تلقي تعليقات من المجتمع، اكتشفنا أن برنامج الرمز المميز لإصدار نقطة التفتيش السابق الخاص بنا قد تم تكوينه بشكل غير صحيح بحيث لا يتم الحفاظ على الخطوط الجديدة. لإصلاح هذه المشكلة، قمنا بإعادة تدريب برنامج الرمز المميز الخاص بنا وأعدنا تشغيل تدريب النموذج. لقد لاحظنا أيضًا انخفاضًا في فقدان التدريب باستخدام هذا الرمز المميز الجديد.
نقوم بإصدار الأوزان بتنسيقين: تنسيق EasyLM لاستخدامه مع إطار عمل EasyLM الخاص بنا، وتنسيق PyTorch لاستخدامه مع مكتبة محولات Hugging Face. تم ترخيص كل من إطار التدريب EasyLM الخاص بنا وأوزان نقاط التفتيش بشكل مسموح بموجب ترخيص Apache 2.0.
يمكن تحميل نقاط فحص المعاينة مباشرة من Hugging Face Hub. يرجى ملاحظة أنه يُنصح بتجنب استخدام برنامج Hugging Face السريع للرمز المميز في الوقت الحالي، حيث لاحظنا أن برنامج الرمز المميز السريع الذي تم تحويله تلقائيًا يعطي أحيانًا رموزًا مميزة غير صحيحة . يمكن تحقيق ذلك عن طريق استخدام فئة LlamaTokenizer مباشرة، أو تمرير خيار use_fast=False لفئة AutoTokenizer . انظر المثال التالي للاستخدام.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))لمزيد من الاستخدام المتقدم، يرجى اتباع وثائق LLaMA الخاصة بالمحولات.
يمكن تقييم النموذج باستخدام lm-eval-harness. ومع ذلك، نظرًا لمشكلة الرمز المميز المذكورة أعلاه، نحتاج إلى تجنب استخدام الرمز المميز السريع للحصول على النتائج الصحيحة. يمكن تحقيق ذلك عن طريق تمرير use_fast=False إلى هذا الجزء من lm-eval-harness، كما هو موضح في المثال أدناه:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)لاستخدام الأوزان في إطار عمل EasyLM الخاص بنا، يرجى الرجوع إلى وثائق LLaMA الخاصة بـ EasyLM. لاحظ أنه على عكس نموذج LLaMA الأصلي، تم تدريب رمز OpenLLAMA وأوزانه بالكامل من الصفر، لذلك لم تعد هناك حاجة للحصول على رمز LLaMA الأصلي وأوزانه.
يتم تدريب نماذج v1 على مجموعة بيانات RedPajama. يتم تدريب نماذج الإصدار الثاني على مزيج من مجموعة بيانات Falcon على الويب ومجموعة بيانات StarCoder وجزء wikipedia وarxiv وbook وstackexchange من مجموعة بيانات RedPajama. نحن نتبع بالضبط نفس خطوات المعالجة المسبقة ومعلمات التدريب الفائقة مثل ورقة LLaMA الأصلية، بما في ذلك بنية النموذج وطول السياق وخطوات التدريب وجدول معدل التعلم والمحسن. الفرق الوحيد بين إعدادنا والإعداد الأصلي هو مجموعة البيانات المستخدمة: يستخدم OpenLLaMA مجموعات بيانات مفتوحة بدلاً من تلك التي يستخدمها LLaMA الأصلي.
نقوم بتدريب النماذج على السحابة TPU-v4s باستخدام EasyLM، وهو مسار تدريب قائم على JAX قمنا بتطويره لتدريب نماذج اللغات الكبيرة وضبطها بشكل دقيق. نحن نستخدم مزيجًا من توازي البيانات العادية وتوازي البيانات المجزأة بالكامل (المعروف أيضًا باسم المرحلة 3 من الصفر) لتحقيق التوازن بين إنتاجية التدريب واستخدام الذاكرة. بشكل عام، وصلنا إلى إنتاجية تزيد عن 2200 رمز مميز / ثانية / شريحة TPU-v4 لطراز 7B الخاص بنا. يمكن رؤية فقدان التدريب في الشكل أدناه.
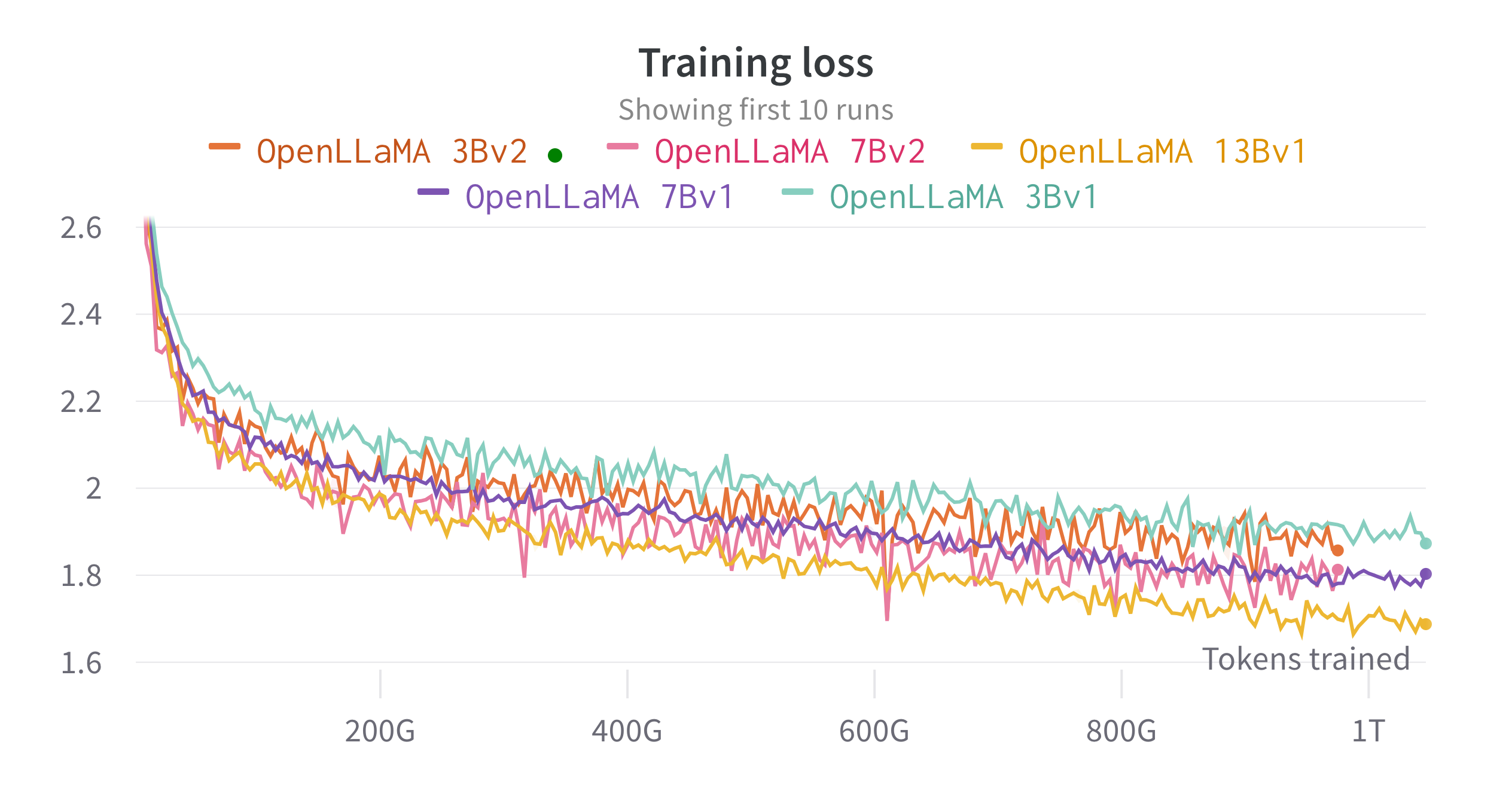
قمنا بتقييم OpenLLaMA على مجموعة واسعة من المهام باستخدام أداة تقييم lm. يتم إنشاء نتائج LLaMA عن طريق تشغيل نموذج LLaMA الأصلي على نفس مقاييس التقييم. نلاحظ أن نتائجنا لنموذج LLaMA تختلف قليلاً عن ورقة LLaMA الأصلية، والتي نعتقد أنها نتيجة لبروتوكولات تقييم مختلفة. تم الإبلاغ عن اختلافات مماثلة في هذا الإصدار من أداة تقييم lm. بالإضافة إلى ذلك، نقدم نتائج GPT-J، وهو نموذج معلمة 6B تم تدريبه على مجموعة بيانات Pile بواسطة EleutherAI.
تم تدريب نموذج LLaMA الأصلي على 1 تريليون رمز، وتم تدريب GPT-J على 500 مليار رمز. ونعرض النتائج في الجدول أدناه. يُظهر OpenLLaMA أداءً مشابهًا لـ LLaMA وGPT-J الأصليين عبر غالبية المهام، ويتفوق عليهما في بعض المهام.
| المهمة/المقياس | جي بي تي-ي 6 ب | لاما 7 ب | لاما 13 ب | OpenLLAMA 3Bv2 | OpenLLAMA 7Bv2 | أوبن لاما 3 ب | أوبن لاما 7 ب | أوبن لاما 13 ب |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/acc | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/acc | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| arc_challenge/acc | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| arc_easy/acc | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| boolq/acc | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| هيلاسواج/acc | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| hellaswag/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| openbookqa/acc | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 | 0.27 | 0.30 | 0.31 |
| openbookqa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| بيكا/acc | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| بيكا/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| سجل / م | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| سجل/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| rte/acc | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| Truthfulqa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| Truthfulqa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| wic/acc | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| winogrande/acc | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| متوسط | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
لقد قمنا بإزالة المهمة CB وWSC من معيارنا المعياري، نظرًا لأن أداء نموذجنا مرتفع بشكل مثير للريبة في هاتين المهمتين. نحن نفترض أنه قد يكون هناك تلوث البيانات القياسية في مجموعة التدريب.
نحن نحب أن نحصل على ردود فعل من المجتمع. إذا كان لديك أي أسئلة، يرجى فتح موضوع أو الاتصال بنا.
تم تطوير OpenLLaMA بواسطة: Xinyang Geng* وHao Liu* من Berkeley AI Research. * المساهمة المتساوية
نشكر برنامج Google TPU Research Cloud لتوفير جزء من موارد الحساب. نود أن نشكر بشكل خاص جوناثان كاتون من TPU Research Cloud لمساعدتنا في تنظيم موارد الحوسبة، ورافي ويتن من فريق Google Cloud وجيمس برادبري من فريق Google JAX لمساعدتنا في تحسين إنتاجية التدريب لدينا. نود أيضًا أن نشكر تشارلي سنيل، وجوتييه إيزاكارد، وإريك والاس، وليانمين زينج ومجتمع المستخدمين لدينا على المناقشات والتعليقات.
تم تدريب نموذج OpenLLaMA 13B v1 بالتعاون مع Stability AI، ونشكر Stability AI لتوفير موارد الحساب. نود أن نشكر بشكل خاص David Ha وShivanshu Purohit على تنسيق الخدمات اللوجستية وتقديم الدعم الهندسي.
إذا وجدت OpenLLaMA مفيدًا في بحثك أو تطبيقاتك، فيرجى الاستشهاد باستخدام BibTeX التالي:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


