StableDiffusionEndToEndGuide
1.0.0
لقد أصبحت مهتمًا باستخدام SD لإنشاء صور للتطبيقات العسكرية. يتم أخذ معظم الموارد من لوحات NSFW الخاصة بـ 4chan، حيث يستخدم المجهولون SD لصنع الهنتاي. ومن المثير للاهتمام أن واجهة SD WebUI الأساسية تحتوي على وظائف مدمجة مع لوحات صور الأنمي/الهنتاي... كانت إحدى حالات استخدام SD الأولى بعد DALL-E مباشرة هي إنشاء فتيات الأنيمي، لذا فإن الانتقال إلى الهنتاي ليس مفاجئًا.
على أية حال، فإن تقنيات هؤلاء غريبي الأطوار قابلة للتطبيق على مجموعة متنوعة من التطبيقات، وعلى الأخص LoRAs، والتي تشبه نماذج الضبط الدقيق. تتمثل الفكرة في العمل مع LoRAs محددة (مثل المركبات العسكرية والطائرات والأسلحة وما إلى ذلك) لإنشاء بيانات صور تركيبية لنماذج الرؤية التدريبية. يعد تدريب LoRAs الجديدة والمفيدة أمرًا مهمًا أيضًا. قد تتضمن الأشياء اللاحقة طلاءًا داخليًا للاضطراب.
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
ما الذي يمكنك فعله فعليًا باستخدام SD؟ لدى Huggingface والبعض الآخر بعض التطبيقات في المتصفح لك. العب معهم لترى القوة! ما سنفعله في هذا الدليل هو الحصول على واجهة WebUI الكاملة والقابلة للتوسيع للسماح لنا بفعل أي شيء نريده.
من الصعب إلى حد ما الخوض في هذا الأمر... لكن القنوات الأربعة قامت بعمل جيد في جعل هذا الأمر سهل الوصول إليه. فيما يلي الخطوات التي اتخذتها، بأبسط العبارات. هدفك هو تشغيل Stable Diffusion WebUI (المُصمم باستخدام Gradio) محليًا حتى تتمكن من البدء في المطالبة بالصور وإنشاءها.
سنقوم بإعداد Google Colab Pro لاحقًا، حتى نتمكن من تشغيل SD على أي جهاز في أي مكان نريده؛ ولكن للبدء، دعونا نحصل على إعداد WebUI على جهاز الكمبيوتر. أنت بحاجة إلى ذاكرة وصول عشوائي (RAM) سعة 16 جيجابايت، ووحدة معالجة رسومات (GPU) مزودة بذاكرة فيديو (VRAM) سعة 2 جيجابايت، ونظام التشغيل Windows 7+ ومساحة قرص تبلغ 20+ جيجابايت.
127.0.0.1:7860 ( لا تستخدم Ctrl + C لأن هذا الأمر يمكنه إغلاق واجهة سطر الأوامر)stable-diffusion-webuioutputstxt2img-images<date>git pull 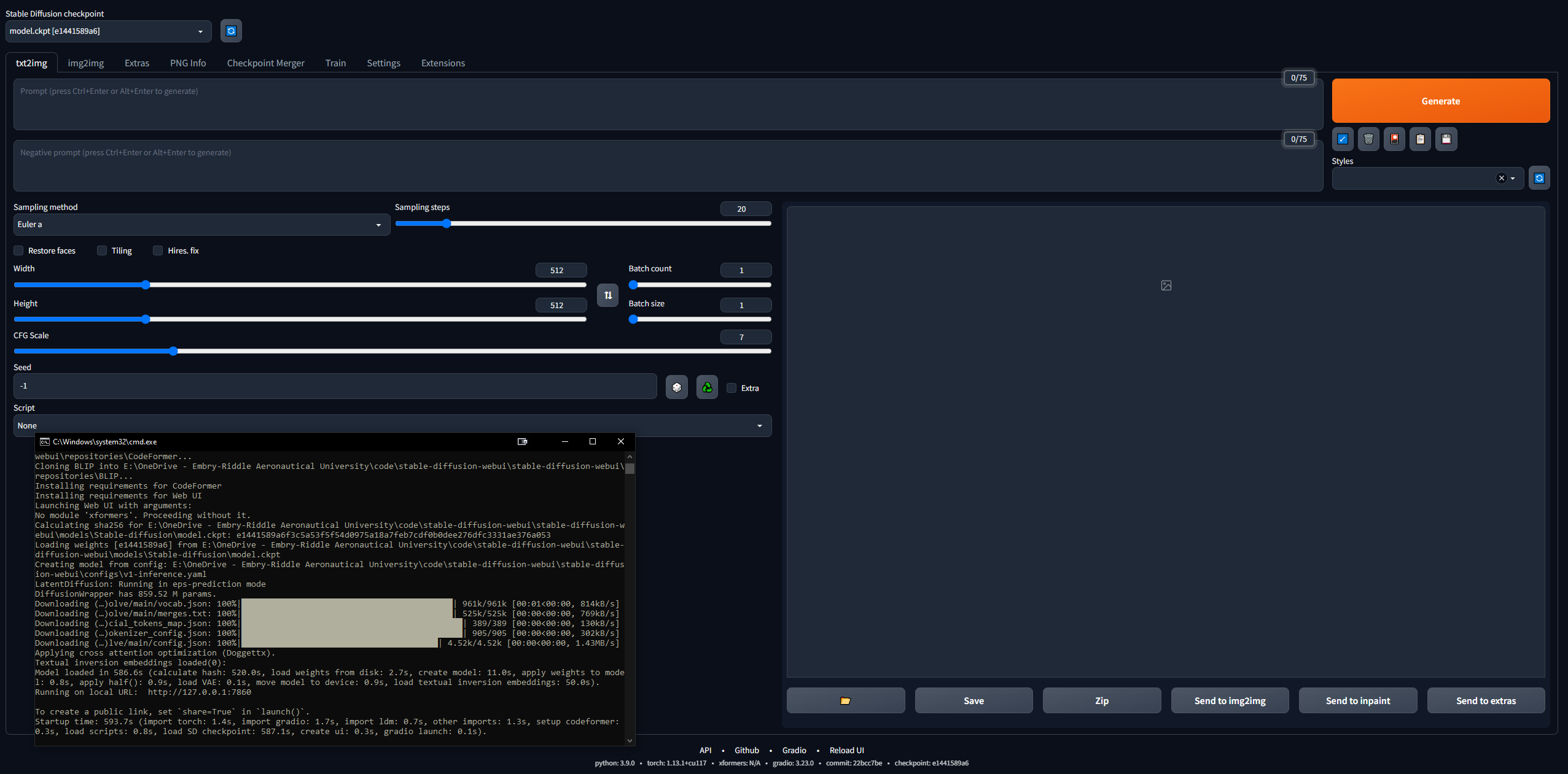
تجاهل هذا تمامًا إذا كان لديك نظام Windows. لقد تمكنت من تشغيله على Linux أيضًا، على الرغم من أنه أكثر تعقيدًا بعض الشيء. لقد بدأت باتباع هذا الدليل، ولكنه مكتوب بشكل سيء إلى حد ما، لذا فيما يلي الخطوات التي اتخذتها لتشغيله على Linux. كنت أستخدم Linux Mint 20، وهو توزيع Ubuntu 20.
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui/models/Stable-diffusionsudo apt install python3 python3-pip python3-virtualenv wget git wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create --name sdwebui python=3.10.6conda activate sdwebui./webui.sh sudo apt update
sudo apt purge *nvidia*
sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get updatesudo apt-get install nvidia-driver-530nvidia-smi ؛ إذا نجحت، يجب طباعة جدول؛ إذا لم يكن الأمر كذلك، فسوف يظهر شيئًا مثل "تعذر الاتصال بوحدة معالجة الرسومات؛ يرجى التأكد من تثبيت أحدث برنامج تشغيل" sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
python3 -c 'import venv'
python3 -m venv venv/
ثم انتقل إلى المجلد /stable-diffusion-webui وقم بتشغيل:
rm -rf venv/
python3 -m venv venv/
بعد ذلك، عملت بالنسبة لي.
ترتيب الكلمات في الموجه له تأثير: الكلمات السابقة لها الأسبقية. الهيكل العام للموجه الجيد، من هنا:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
ودليل جيد آخر يقول أن الموجه يجب أن يتبع هذا الهيكل:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
ورقة بحثية حول نماذج txt2img الهندسية السريعة، هنا. المصدر النهائي لطلبات LLM، هنا.
مهما طلبت، حاول اتباع نوع من البنية حتى تكون عمليتك قابلة للتكرار. فيما يلي عناصر بناء الجملة الضرورية:
1girl standing on grass in front of castle AND castle in background النموذج الافتراضي أنيق جدًا، ولكن، كما هو الحال عادةً في التاريخ، فإن الجنس هو الذي يحرك معظم الأشياء. كانت NovelAI (NAI) عبارة عن خدمة إنشاء محتوى SD تركز على الرسوم المتحركة وتم تسريب نموذجها الرئيسي. معظم الصور التي تم إنشاؤها بواسطة SD لرجال ونساء الأنمي الذين تراهم (NSFW أم لا) تأتي من هذا النموذج المسرب.
على أية حال، إنها جيدة حقًا في توليد الأشخاص ومعظم النماذج أو LoRAs التي ستلعب بها من خلال الدمج متوافقة معها لأنها مدربة على صور الأنيمي. أيضًا، يقدم البشر حالة استخدام جيدة للبدء في ضبط LoRAs التي تريد استخدامها للأغراض المهنية. سوف تقوم باستكشاف الأخطاء وإصلاحها كثيرًا ومعظم الأدلة المتوفرة مخصصة لصور النساء. سنتحدث لاحقًا عن أجهزة التشفير التلقائي المتغيرة (VAEs)، مما يضفي الواقعية الحقيقية على النموذج.
stable-diffusion-webuimodelsStable-diffusion ، وتحديد النموذج هناك، يجب أن تضطر إلى الانتظار بضع دقائق بينما يقوم CLI بتحميل أوزان VAEيسمح التكيف ذو الرتبة المنخفضة (LoRA) بالضبط الدقيق لنموذج معين. مزيد من المعلومات حول LoRAs هنا. في WebUI، يمكنك إضافة LoRAs إلى نموذج مثل تزيين الكعكة. يعد تدريب LoRAs الجديد أمرًا سهلاً أيضًا. هناك وسائل أخرى "موروثة" للضبط الدقيق (على سبيل المثال، عكس النص والشبكات الفائقة)، ولكن LoRAs هي أحدث ما توصلت إليه التكنولوجيا.
سأستخدم خزان LoRA في جميع أنحاء الدليل. يرجى ملاحظة أن هذا ليس LoRA جيدًا جدًا، لأنه مخصص للصور ذات نمط الرسوم المتحركة، ولكن من الجيد اللعب به.
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora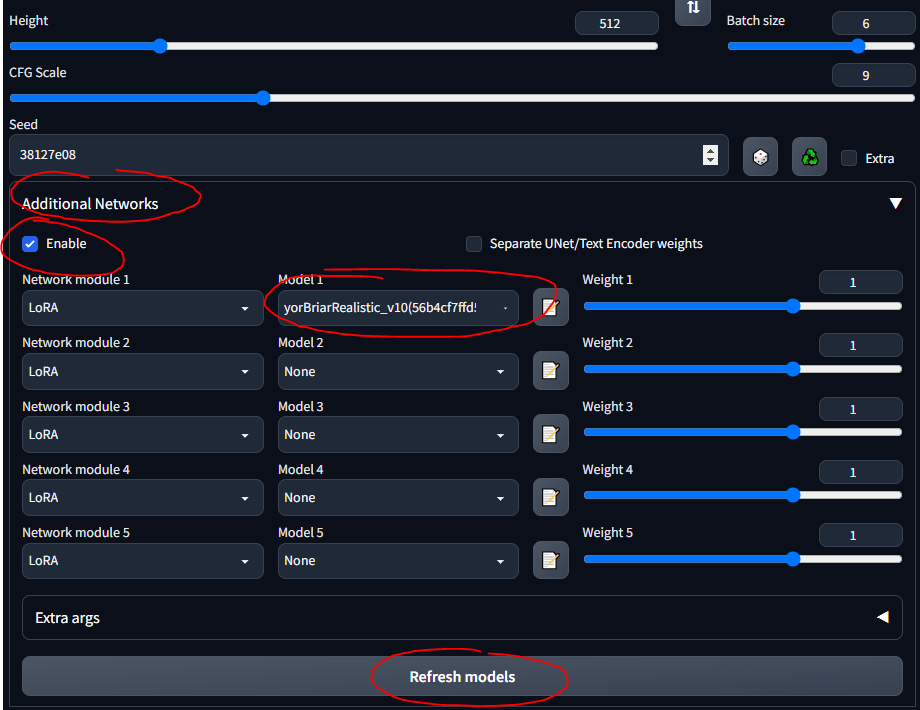
بناءً على القسم السابق... تحتوي النماذج المختلفة على بيانات تدريب وكلمات رئيسية مختلفة للتدريب... لذا فإن استخدام علامات booru في بعض النماذج لا يعمل بشكل جيد. فيما يلي بعض النماذج التي لعبت بها و"التعليمات" الخاصة بها.
نموذج SDG Motherload، يُستخدم للحصول على معظم النماذج، أنا فقط أقوم بتلخيص التعليمات هنا كمرجع سريع؛ معظم العارضات مخصصات للإباحية الحرفية، لكني ركزت على العارضات الواقعيات. اتبع الروابط للاطلاع على أمثلة للمطالبات والصور والملاحظات التفصيلية حول استخدام كل منها.
تم استخدام CivitAI للحصول على جميع الآخرين. يتعين عليك إنشاء حساب وإلا فلن تتمكن من رؤية أشياء NSFW، بما في ذلك الأسلحة والمعدات العسكرية. في CivitAI، تتضمن بعض النماذج (نقاط التفتيش) VAEs؛ إذا ذكر ذلك، قم بتنزيله أيضًا وضعه بجانب النموذج.
تعمل أجهزة التشفير التلقائي المتغيرة على جعل الصور تبدو أفضل وأكثر وضوحًا وأقل تشويشًا. يقوم البعض أيضًا بإصلاح الأيدي والوجوه. لكنها في الغالب شيء التشبع والتظليل. تم شرحه هنا وهنا (NSFW). يتم استخدام NovelAI / Anything VAE بشكل شائع. إنها في الأساس إضافة إلى النموذج الخاص بك، تمامًا مثل LoRA.
ابحث عن VAEs في قائمة VAE:
stable-diffusion-webuimodelsVAEفيما يلي بعض الملاحظات العامة والأشياء المفيدة التي تعلمتها على طول الطريق والتي لا تتناسب بالضرورة مع التدفق الزمني لهذا الدليل.
إحدى الطرق الجيدة للتعلم هي تصفح الصور الرائعة على CivitAI أو AIbooru أو مواقع SD الأخرى (4chan وReddit وما إلى ذلك)، وفتح ما تريد ونسخ معلمات الإنشاء إلى WebUI. الكشف الكامل: إعادة إنشاء الصورة تمامًا ليس ممكنًا دائمًا، كما هو موضح هنا. ولكن يمكنك عمومًا أن تكون قريبًا جدًا. للتلاعب حقًا، قم بخفض مستوى CFG حتى يصبح النموذج أكثر إبداعًا. جرب الدفعات وابتعد عن الكمبيوتر لتعود إلى الكثير لتختاره.
العملية العامة لسير عمل WebUI هي:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
في بعض الأحيان تريد العودة إلى المطالبات دون لصق الصور أو كتابتها من الصفر. يمكنك حفظ المطالبات لإعادة استخدامها في WebUI.
يعد هذا القسم تقريبًا ملخصًا لمعلومات هذا الدليل.
للعمل من صورة تم إنشاؤها بواسطة SD موجودة بالفعل؛ ربما أرسلها إليك شخص ما أو تريد إعادة إنشاء واحدة قمت بإنشائها:
stable-diffusion-webuioutputstxt2img-images<date>انتبه إلى أن بعض المواقع تقوم بإزالة البيانات التعريفية بتنسيق PNG عند تحميل الصور (على سبيل المثال، 4chan)، لذا ابحث عن عناوين URL للصور الكاملة أو استخدم المواقع التي تحتفظ بالبيانات الوصفية لـ SD، مثل CivitAI أو AIbooru.
حصلت على بعض الأخطاء بين الحين والآخر. غالبًا ما يتم إصلاح أخطاء نفاد الذاكرة (VRAM) عن طريق خفض القيم في بعض المعلمات. في بعض الأحيان يتم استعادة الوجوه والتعيينات. إعدادات الإصلاح يمكن أن تسبب هذا. في الملف stable-diffusion-webuiwebui-user.bat ، في السطر set COMMANDLINE_ARGS= ، يمكنك وضع بعض العلامات التي تعمل على إصلاح الأخطاء الشائعة.
--disable-nan-check--no-half--medvram أو --lowvram لأجهزة كمبيوتر البطاطستنبع إحدى المشكلات الشائعة حقًا من وجود إصدار Python أو إصدار Torch غير صحيح. سوف تحصل على أخطاء مثل "لا يمكن تثبيت Torch" أو "لا يمكن لـ Torch العثور على GPU". أبسط الإصلاح هو:
Python ومجلدات Python/Scripts )venv الموجود في مجلد stable-diffusion-webui الخاص بكstable-diffusion-webuiwebui-user.bat واتركه يعيد بناء venv بشكل صحيحيمكن العثور على كافة وسائط سطر الأوامر هنا.
يمكن لبعض الإضافات أن تجعل استخدام WebUI أفضل. احصل على رابط Github، وانتقل إلى علامة التبويب "الامتدادات"، وقم بالتثبيت من URL؛ اختياريًا، في علامة تبويب الامتدادات، انقر فوق متاح، ثم قم بتحميل من ويمكنك تصفح الامتدادات محليًا، وهذا يعكس الامتدادات Github wiki.
إذن، لديك الآن بعض النماذج وLoRAs والمطالبات... كيف يمكنك اختبارها لمعرفة ما هو الأفضل؟ أسفل جزء الشبكات الإضافية، توجد القائمة المنسدلة للبرنامج النصي. هنا، انقر فوق مؤامرة X/Y/Z. في النوع X، حدد اسم نقطة التفتيش؛ في قيم X، انقر فوق الزر الموجود على اليمين للصق كافة النماذج الخاصة بك. في النوع Y، جرب مقياس VAE، أو ربما البذور، أو مقياس CFG. مهما كانت السمة التي تختارها، الصق (أو أدخل) القيم التي تريد رسمها بيانيًا. على سبيل المثال، إذا كان لديك 5 نماذج و5 VAEs، فسوف تقوم بإنشاء شبكة مكونة من 25 صورة، مقارنة كيفية إخراج كل نموذج مع كل VAE. هذا متعدد الاستخدامات ويمكن أن يساعدك في تحديد ما يجب استخدامه. فقط احذر أنه إذا كانت محاور X أو Y الخاصة بك عبارة عن نماذج لـ VAEs، فيجب تحميل النموذج أو أوزان VAE لكل مجموعة، لذلك قد يستغرق الأمر بعض الوقت.
يمكن العثور على مورد جيد حقًا لمقارنات SD هنا (NSFW). هناك الكثير من الروابط للمتابعة. يمكنك البدء في تكوين فهم لكيفية تأثير النماذج المختلفة وVAEs وLoRAs وقيم المعلمات وما إلى ذلك على توليد الصور.
لقد اعتمدت موجه اختبار من هنا واستخدمت خزان LoRA لإنشاء شبكة X/Y هذه. يمكنك أن ترى كيف تعمل النماذج المختلفة وأخذ العينات مع بعضها البعض. ومن هذا الاختبار يمكننا تقييم ما يلي:

المعلمات الدقيقة المستخدمة (لا تشمل النموذج أو جهاز أخذ العينات) لكل صورة من صور الخزانات مذكورة أدناه (مرة أخرى، مأخوذة من هنا):
يوجد في هذا القسم الأشياء الأكثر تقدمًا التي يمكنك القيام بها بمجرد أن تكتسب معرفة جيدة باستخدام النماذج وLoRAs وVAEs والمطالبات والمعلمات والبرمجة النصية والامتدادات في علامة التبويب txt2image في واجهة WebUI.
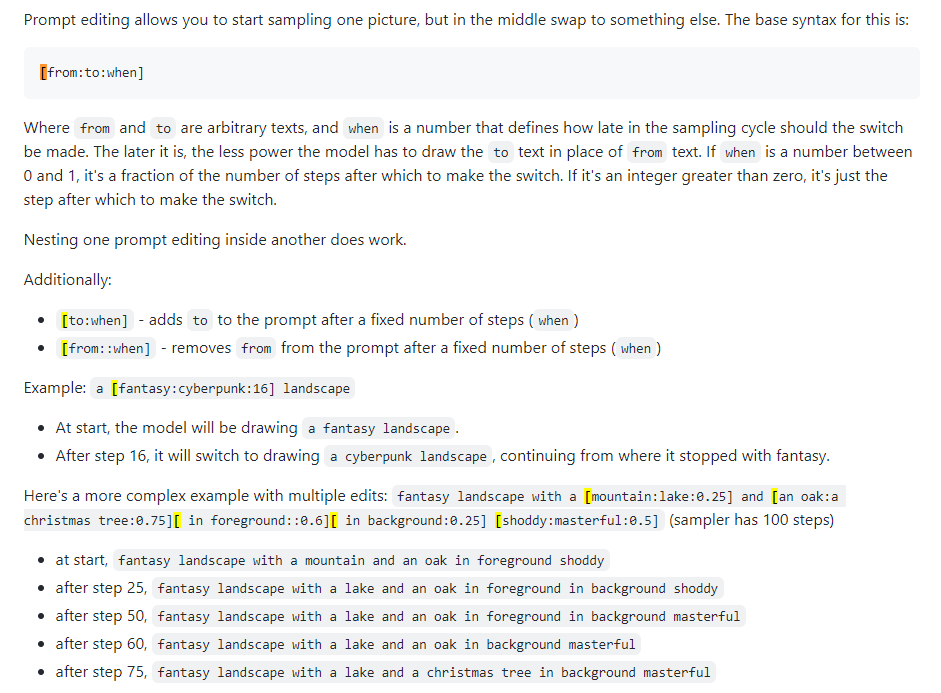
يُعرف أيضًا باسم المزج السريع. يتيح لك التحرير الفوري مطالبة النموذج بتغيير موجهه في خطوات محددة. الصورة أدناه مأخوذة من منشور 4chan وتصف هذه التقنية. على سبيل المثال، كما هو مذكور في هذا الدليل، يمكن استخدام التحرير الفوري لمزج الوجوه.
Xformers، أو طبقات الانتباه المتقاطع. هناك طريقة لتسريع إنشاء الصور (يتم قياسها بالثواني/التكرار، أو s/it) على وحدات معالجة الرسومات Nvidia، مما يقلل من استخدام VRAM ولكنه يسبب عدم الحتمية. ضع في اعتبارك هذا فقط إذا كان لديك وحدة معالجة رسومات قوية؛ واقعيا أنت بحاجة إلى كوادرو.
لا يستخدم كثيرًا، نوع من علامة التبويب المربكة. يمكن استخدامها لإنشاء صور معينة في الرسومات، كما هو الحال في Huggingface Image to Image SD Playground. تحتوي علامة التبويب هذه على علامة تبويب فرعية، وهي inpainting، وهي موضوع القسم التالي وهي إحدى الإمكانيات المهمة جدًا لواجهة WebUI. بينما يمكنك استخدام هذا القسم لإنشاء صور معدلة بالنظر إلى الصورة التي قمت بإنشائها بالفعل (الإخراج إلى stable-diffusion-webuioutputsimg2img-images ) ، فإن الوظيفة متقطعة بالنسبة لي... يبدو أنها تستخدم قدرًا هائلاً من الذاكرة و بالكاد أستطيع الحصول عليه للعمل. انتقل إلى القسم التالي أدناه.
هذا هو المكان الذي تكمن فيه القوة لمنشئ المحتوى أو أي شخص مهتم بتشويه الصورة. الإخراج في stable-diffusion-webuioutputsimg2img-images .
تعد عملية الطلاء الخارجي عملية دلالية معقدة إلى حد ما. يتيح لك Outpainting التقاط صورة وتوسيعها عدة مرات كما تريد، مما يؤدي بشكل أساسي إلى زيادة حدودها. تم وصف العملية هنا. يمكنك توسيع الصورة بمقدار 64 بكسل فقط في المرة الواحدة. هناك أداتان لواجهة المستخدم لهذا (يمكنني العثور عليهما):
علامة التبويب WebUI هذه مخصصة للترقية. إذا حصلت على صورة أعجبتك حقًا، فيمكنك ترقيتها هنا في نهاية سير عملك. يتم تخزين الصور التي تمت ترقيتها في stable-diffusion-webuioutputsextras-images . بعض مشكلات الذاكرة المرتبطة بالترقية باستخدام أدوات ترقية أكثر قوة أثناء الإنشاء في علامة التبويب txt2img (على سبيل المثال، 4x+ تلك) لا تحدث هنا لأنك لا تقوم بإنشاء صور جديدة، بل تقوم فقط بترقية الصور الثابتة.
أفضل طريقة لفهم ما تفعله شبكة ControlNet هي قول "inpainting on steroids". يمكنك إعطائها صورة إدخال (تم إنشاؤها بواسطة SD أم لا) ويمكنها تعديل كل شيء. من الممكن أيضًا استخدام ControlNets في الأوضاع. يمكنك إعطاء وضع مرجعي لشخص ما وإنشاء صور مقابلة بناءً على مطالبتك النموذجية. هنا بداية جيدة لفهم ControlNets.
stable-diffusion-webuiextensionssd-webui-controlnetmodels

كل هذا جيد وجيد، لكن في بعض الأحيان تحتاج إلى نماذج أو LoRAs أفضل لحالات الاستخدام الاحترافي. نظرًا لأن معظم محتوى SD مخصص حرفيًا لإنتاج النساء أو المواد الإباحية، فقد تحتاج نماذج محددة وLoRAs إلى التدريب.
راجع القسم الخاص بـ DreamBooth.
المهام
تتيح لك علامة تبويب دمج نقاط التفتيش في WebUI دمج نموذجين معًا، مثل خلط صلصتين في وعاء، حيث يكون الناتج عبارة عن صلصة جديدة عبارة عن مزيج منهما.
المهام
تدريب LoRA ليس بالضرورة أمرًا صعبًا، فهو مجرد مسألة جمع بيانات كافية.
هذه خطوة مهمة إذا كان عليك العمل بعيدًا عن جهازك. يبلغ سعر Google Colab Pro 10 دولارات شهريًا ويمنحك 89 جيجابايت من ذاكرة الوصول العشوائي (RAM) وإمكانية الوصول إلى وحدات معالجة الرسومات الجيدة، حتى تتمكن من الناحية الفنية من تشغيل المطالبات من هاتفك وجعلها تعمل لصالحك على خادم في تمبكتو. إذا كنت لا تمانع في تحمل بعض التكلفة الإضافية، فإن Google Colab Pro+ يكلف 50 دولارًا شهريًا وهو أفضل.
gdrive/MyDrive/sd/stable-diffusion-webui ومن هذا المجلد الأساسي يمكنك استخدام نفس عناصر بنية المجلد التي كنت تفعلها في المجلد المحلي واجهة مستخدم الويبإن Google Colab مجاني دائمًا ويمكنك استخدامه إلى الأبد، ولكنه قد يكون بطيئًا بعض الشيء. تمنحك الترقية إلى Colab Pro مقابل 10 دولارات شهريًا مزيدًا من القوة. لكن Colab Pro+ مقابل 50 دولارًا شهريًا هو المكان الذي توجد فيه المتعة حقًا. يتيح لك Pro+ تشغيل التعليمات البرمجية الخاصة بك لمدة 24 ساعة حتى بعد إغلاق علامة التبويب.
TODO لقد تلقيت خطأً غريبًا يؤدي إلى انقطاع الاتصال باشتراكي الاحترافي عندما أقوم بتعيين وقت التشغيل الخاص بي -> إعدادات دفتر الملاحظات من نوع وقت التشغيل على فئة Premium GPU وذاكرة الوصول العشوائي العالية. ذلك لأن xFormers لم يتم تصميمه بدعم CUDA. يمكن حل هذه المشكلة باستخدام وحدات TPU بدلاً من ذلك أو تعطيل xFormers ولكن ليس لدي الصبر لذلك في الوقت الحالي. جرب قضايا كولاب.
MJ جيد حقًا للفنانين. إنها ليست قابلة للتوسعة أو قوية على الإطلاق مثل SD في WebUI (NSFW مستحيل)، ولكن يمكنك إنشاء بعض الأشياء الرائعة جدًا. يمكنك استخدامه مجانًا في MJ Discord (قم بالتسجيل على موقعهم) لعدد قليل من المطالبات أو دفع 8 دولارات شهريًا للخطة الأساسية، وبعد ذلك يمكنك استخدامه في خادمك الخاص. جميع أوامر Discord يمكن العثور عليها هنا وهنا. الهيكل الفوري لـ MJ هو:
/imagine <optional image prompt> <prompt> --parameters
هذه مخصصة لـ MJ V4، ومعظمها نفس الشيء بالنسبة لـ MJ 5. جميع الطرازات موصوفة هنا.
المهام
Dreamstudio (وليس Dreambooth) هي المنصة الرئيسية من شركة AI الاستقرار. موقعهم عبارة عن منصة ، Dreambooth Studio ، يمكنك من خلالها إنشاء صور. إنه نوع من الإقرار بين Midjourney و Webui من حيث الوظائف المفتوحة. يبدو أن Dreambooth Studio تم تصميمه على قمة منصة Invoke.ai ، والتي يمكنك تثبيتها وتشغيلها محليًا مثل Webui.
المهام
الحشد المستقر هو جهد مجتمعي لجعل الانتشار المستقر مجانيًا للجميع. إنه يعمل بشكل أساسي مثل التجزئة أو البيتكوين ، حيث يساهم الجميع في بعض قدرات GPU الخاصة بهم لإنشاء محتوى SD. يمكن الوصول إلى تطبيق Horde هنا.
المهام
كان Dreambooth (وليس Dreamstudio) هو تطبيق Google لتقنية صقل النموذج المستقر. باختصار: يمكنك استخدامه لتدريب النماذج مع صورك الخاصة. يمكنك استخدامه مباشرة من هنا أو هنا. إنه أكثر تعقيدًا من مجرد تنزيل النماذج والنقر في Webui ، حيث تعمل بالفعل على تدريب وتسلسل نموذج جديد. تلخص بعض مقاطع الفيديو كيفية القيام بذلك:
وبعض الأدلة الجيدة:
Google Colab لـ Dreambooth:
هناك أيضًا مدرب نموذج يسمى EveryDream. يمكن العثور على مقارنة كاملة بين Dreambooth و EveryDream هنا.
المهام
من الممكن اعتبارًا من مارس 2023 لاستخدام نشر مستقر لإنشاء مقاطع فيديو. حاليًا (أبريل 2023) ، تعد الوظيفة مبسطة إلى حد ما ، حيث يتم إنشاء مقاطع الفيديو من صور مماثلة ، إطارًا تلو الآخر ، مما يمنح مقاطع الفيديو نوعًا من مظهر "Flipbook". هناك امتدادان أساسيان لـ webui يمكنك استخدامه:
الأشياء التي لا أعرفها كثيرًا ولكن أحتاج إلى النظر فيها
هناك عملية يمكنك متابعتها للحصول على نتائج جيدة مرارًا وتكرارًا ... سيتم تحسين ذلك بمرور الوقت.
تكامل chatgpt؟
رسم خارجي
دال 2
deforum https://deforum.github.io/


