coverup
ved performance using tool function

بقلم خوان ألتماير بيزورنو وإيمري بيرجر في مختبر البلازما التابع لجامعة ماساتشوستس أمهيرست.
يقوم CoverUp تلقائيًا بإنشاء اختبارات تضمن اختبار المزيد من التعليمات البرمجية الخاصة بك (أي أنه يزيد من تغطية التعليمات البرمجية الخاصة به). يمكن لـ CoverUp أيضًا إنشاء مجموعة اختبار من البداية إذا لم يكن لديك واحدة بعد. تعتمد الاختبارات الجديدة على التعليمات البرمجية الخاصة بك، مما يجعلها مفيدة لاختبار الانحدار.
تم تصميم CoverUp للعمل بشكل وثيق مع إطار اختبار pytest. لإنشاء اختبارات، يقوم أولاً بقياس تغطية جناحك باستخدام SlipCover. ثم يقوم بعد ذلك بتحديد أجزاء من التعليمات البرمجية التي تحتاج إلى مزيد من الاختبار (أي التعليمات البرمجية التي تم كشفها). بعد ذلك، يشارك CoverUp في محادثة مع LLM، ويطالب بإجراء الاختبارات، ويتحقق من النتائج للتأكد من تشغيلها ويزيد التغطية (مرة أخرى باستخدام SlipCover)، ويعيد المطالبة بإجراء التعديلات حسب الضرورة. وأخيرًا، يتحقق CoverUp اختياريًا من تكامل الاختبارات الجديدة بشكل جيد، ويحاول حل أي مشكلات يجدها.
للحصول على التفاصيل الفنية والتقييم الكامل، راجع ورقة arXiv الخاصة بنا، CoverUp: إنشاء اختبار قائم على التغطية الموجهة LLM (PDF).
يتوفر CoverUp من PyPI، لذا يمكنك التثبيت ببساطة باستخدام
$ python3 -m pip install coverup يمكن استخدام CoverUp مع نماذج OpenAI أو Anthropic أو AWS Bedrock؛ يتطلب تحديد تفاصيل الوصول كمتغيرات بيئة Shell: OPENAI_API_KEY أو ANTHROPIC_API_KEY أو AWS_ACCESS_KEY_ID / AWS_SECRET_ACCESS_KEY / AWS_REGION_NAME ، على التوالي.
على سبيل المثال، بالنسبة لـ OpenAI، يمكنك إنشاء حساب، والتأكد من أن لديه رصيد إيجابي، ثم إنشاء مفتاح API، وتخزين "المفتاح السري" الخاص به (عادةً سلسلة تبدأ بـ sk- ) في متغير بيئة يسمى OPENAI_API_KEY :
$ export OPENAI_API_KEY= < ...your-api-key... > إذا كانت الوحدة الخاصة بك تحمل اسم mymod ، وكانت مصادرها موجودة ضمن src والاختبارات ضمن tests ، فيمكنك تشغيل CoverUp باسم
$ coverup --source-dir src/mymod --tests-dir tests يقوم CoverUp بعد ذلك بإنشاء اختبارات باسم test_coverup_N.py ، حيث N هو رقم، ضمن دليل tests .
هنا لدينا CoverUp لإنشاء اختبارات إضافية للحزمة الشهيرة Flask:
$ coverup --package src/flask --tests tests
Measuring coverage... 90.9%
Prompting gpt-4o-2024-05-13 for tests to increase coverage...
(in the following, G=good, F=failed, U=useless and R=retry)
100%|███████████████████████████████████████| 92/92 [01:01<00:00, 1.50it/s, G=55, F=122, U=20, R=0, cost=~$4.19]
Measuring coverage... 94.4%
$
في ما يزيد قليلاً عن دقيقة واحدة، يعمل CoverUp على زيادة تغطية اختبار Flask من 90.9% إلى 94.4%.
أثناء تقييم كل اختبار تم إنشاؤه حديثًا، يقوم CoverUp بتنفيذه عدة مرات في محاولة لاكتشاف أي اختبارات غير مستقرة؛ التي يمكن ضبطها باستخدام خيارات --repeat-tests و --no-repeat-tests . إذا اكتشف CoverUp أن الاختبار الذي تم إنشاؤه حديثًا غير مستقر، فإنه يطالب LLM بالتصحيح.
يضيف CoverUp فقط الاختبارات إلى المجموعة التي، عند تشغيلها بمفردها، تنجح في زيادة التغطية. لكن من الممكن أن تؤدي الاختبارات إلى "تلويث" الدولة، وتغييرها بشكل يؤدي إلى فشل الاختبارات الأخرى. افتراضيًا، يستخدم CoverUp المكوّن الإضافي pytest-cleanslate لعزل الاختبارات، والتغلب على أي تلوث اختباري (في الذاكرة)؛ والتي يمكن تعطيلها عن طريق تمرير خيار --no-isolate-tests . يمكن أيضًا أن يُطلب من CoverUp البحث عن وحدة أو وظيفة اختبار التلوث وتعطيلها ( --disable-polluting ) أو ببساطة تعطيل أي اختبارات فاشلة (``--disable-failing`).
لتقييم الاختبارات التي تم إنشاؤها بواسطة LLM، يجب على CoverUp تنفيذها. للحصول على أفضل أمان وتقليل مخاطر تلف نظامك، نوصي بتشغيل CoverUp مع Docker.
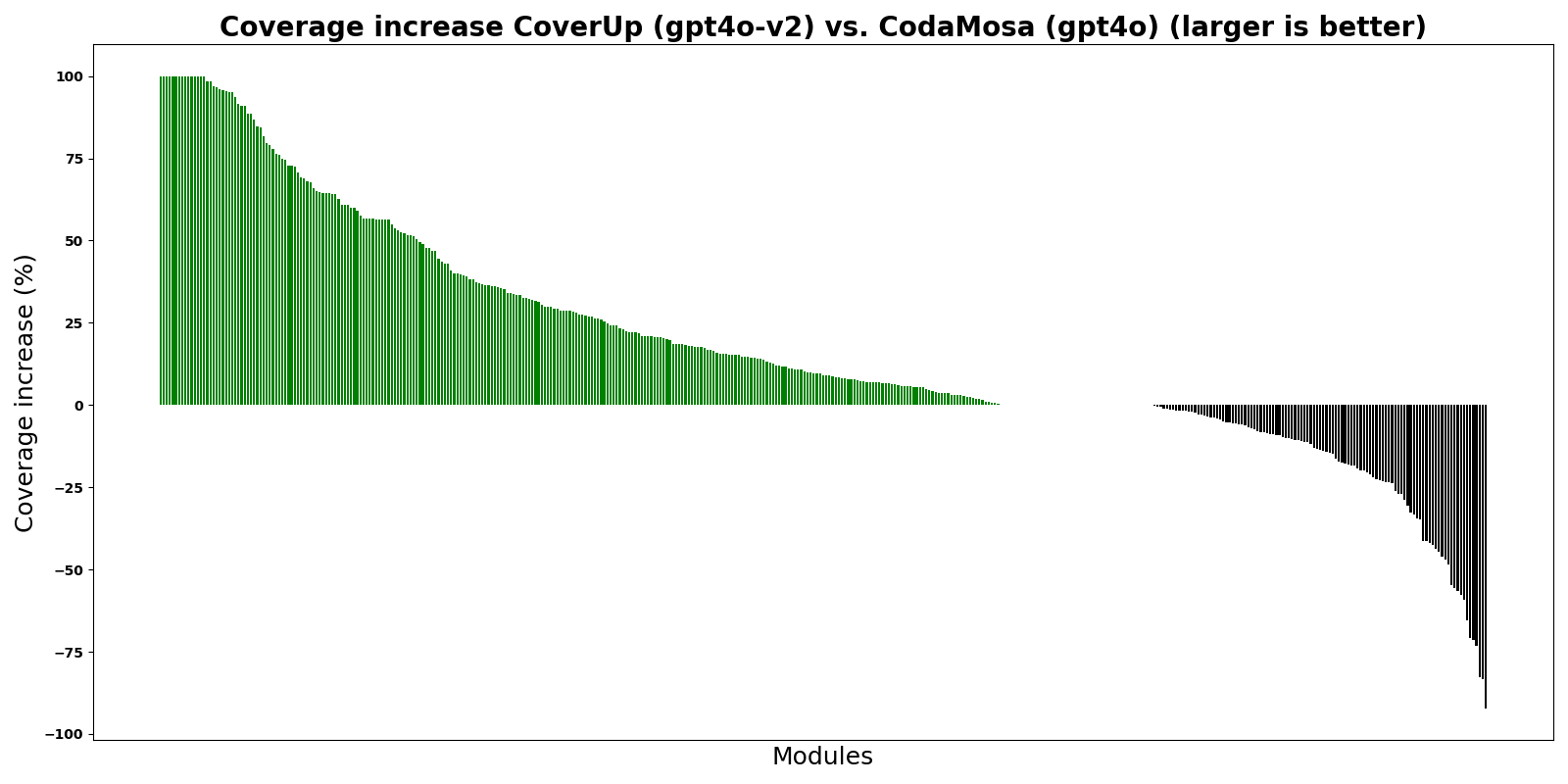
يُظهر الرسم البياني CoverUp مقارنةً بـ CodaMosa، وهو مولد اختبار متطور قائم على البحث يعتمد على مولد اختبار Pynguin. بالنسبة لهذه التجربة، أنشأ كل من CoverUp وCodaMosa اختبارات "من الصفر"، أي تجاهل أي مجموعة اختبارات موجودة. تُظهر الأشرطة الفرق في نسبة التغطية بين CoverUp وCodaMosa لوحدات Python المختلفة؛ تشير الأشرطة الخضراء، أعلى من 0، إلى أن CoverUp حقق تغطية أعلى.
كما يظهر الرسم البياني، يحقق CoverUp تغطية أعلى من CodaMosa لمعظم الوحدات.
هذا هو الإصدار المبكر من CoverUp. يرجى الاستمتاع به، والعفو عن أي اضطرابات ونحن نعمل على تحسينه. نرحب بتقارير الأخطاء وتقارير الخبرة وطلبات الميزات (يُرجى فتح مشكلة).


