JoyVASA
1.0.0
شويانغ كاو 1* غوكسين وانغ 12* شينغ شي 1* جون تشاو 1 يانغ ياو 1
جينتاو فاي 1 مينيو جاو 1
1 شركة JD Health International Inc. 2 جامعة تشجيانغ
حققت الرسوم المتحركة للصورة المبنية على الصوت تطورات كبيرة مع النماذج القائمة على الانتشار، مما أدى إلى تحسين جودة الفيديو ودقة مزامنة الشفاه. ومع ذلك، أدى التعقيد المتزايد لهذه النماذج إلى عدم كفاءة التدريب والاستدلال، فضلاً عن القيود المفروضة على طول الفيديو والاستمرارية بين الإطارات. في هذا البحث، نقترح طريقة JoyVASA، وهي طريقة قائمة على الانتشار لتوليد ديناميكيات الوجه وحركة الرأس في الرسوم المتحركة للوجه المعتمدة على الصوت. على وجه التحديد، في المرحلة الأولى، نقدم إطار تمثيل الوجه المنفصل الذي يفصل تعبيرات الوجه الديناميكية عن تمثيلات الوجه الثابتة ثلاثية الأبعاد. يسمح هذا الفصل للنظام بإنشاء مقاطع فيديو أطول من خلال الجمع بين أي تمثيل ثابت ثلاثي الأبعاد للوجه مع تسلسلات الحركة الديناميكية. ثم، في المرحلة الثانية، يتم تدريب محول الانتشار لتوليد تسلسلات الحركة مباشرة من الإشارات الصوتية، بغض النظر عن هوية الشخصية. أخيرًا، يستخدم المولد الذي تم تدريبه في المرحلة الأولى تمثيل الوجه ثلاثي الأبعاد وتسلسلات الحركة المولدة كمدخلات لتقديم رسوم متحركة عالية الجودة. من خلال تمثيل الوجه المنفصل وعملية توليد الحركة المستقلة عن الهوية، تمتد JoyVASA إلى ما هو أبعد من الصور البشرية لتحريك وجوه الحيوانات بسلاسة. تم تدريب النموذج على مجموعة بيانات مختلطة من البيانات الصينية العامة وبيانات اللغة الإنجليزية العامة، مما يتيح الدعم متعدد اللغات. النتائج التجريبية تثبت فعالية نهجنا. سيركز العمل المستقبلي على تحسين الأداء في الوقت الفعلي وتحسين التحكم في التعبير، وتوسيع نطاق تطبيقات الإطار في الرسوم المتحركة الشخصية.
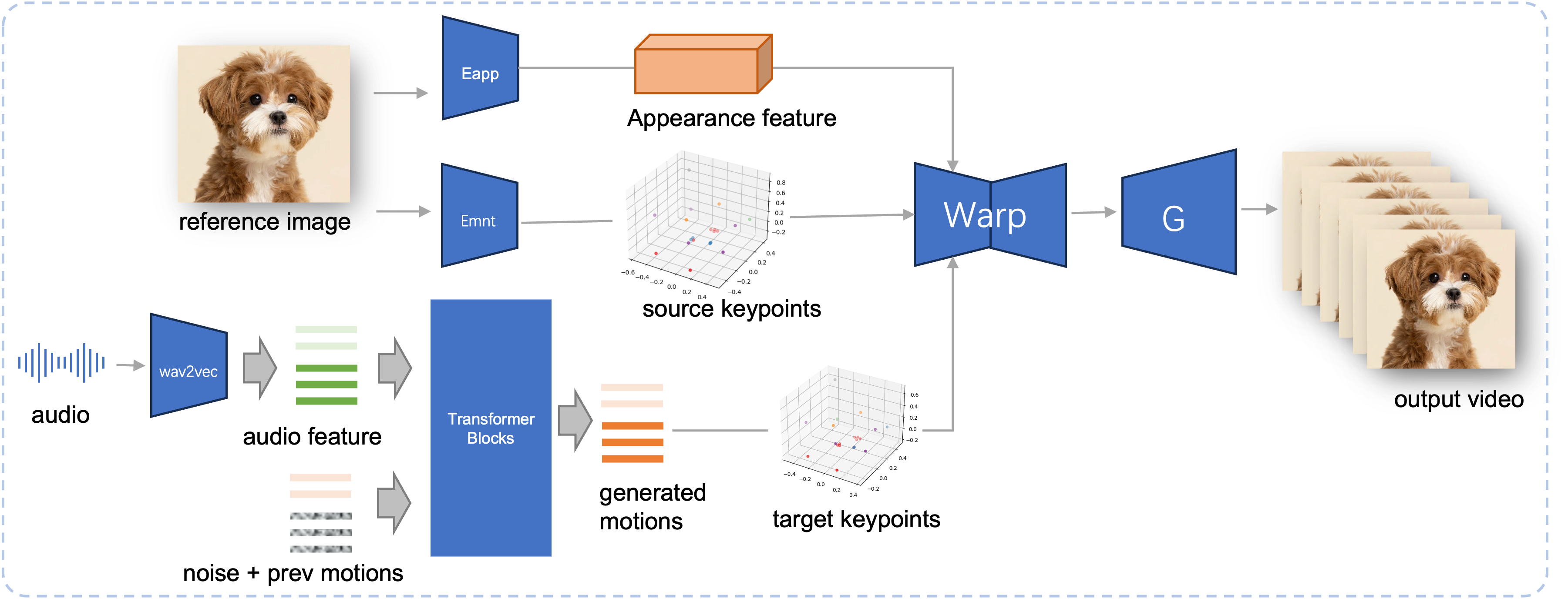
خط أنابيب الاستدلال لـ JoyVASA المقترح. بالنظر إلى صورة مرجعية، نقوم أولاً باستخراج ميزة مظهر الوجه ثلاثي الأبعاد باستخدام أداة تشفير المظهر في LivePortrait، وكذلك سلسلة من نقاط المفاتيح ثلاثية الأبعاد التي تم تعلمها باستخدام أداة تشفير الحركة. بالنسبة لإدخال الكلام، يتم استخراج ميزات الصوت مبدئيًا باستخدام برنامج التشفير wav2vec2. يتم بعد ذلك أخذ عينات من تسلسلات الحركة المعتمدة على الصوت باستخدام نموذج نشر تم تدريبه في المرحلة الثانية بطريقة النافذة المنزلقة. باستخدام نقاط المفاتيح ثلاثية الأبعاد للصورة المرجعية، وتسلسلات حركة الهدف التي تم أخذ عينات منها، يتم حساب نقاط المفاتيح المستهدفة. أخيرًا، يتم تشويه ميزة مظهر الوجه ثلاثي الأبعاد بناءً على نقاط المفاتيح المصدر والهدف ويتم تقديمها بواسطة مولد لإنتاج فيديو الإخراج النهائي.
متطلبات النظام:
أوبونتو:
تم الاختبار على Ubuntu 20.04 وCuda 11.3
وحدات معالجة الرسومات التي تم اختبارها: A100
ويندوز:
تم اختباره على Windows 11 وCUDA 12.1
وحدات معالجة الرسومات التي تم اختبارها: وحدة معالجة الرسومات RTX 4060 للكمبيوتر المحمول بسعة 8 جيجابايت VRAM
خلق البيئة:
# 1. إنشاء البيئة الأساسيةconda create -n Joyvasa python=3.10 -y كوندا تفعيل Joyvasa # 2. تثبيت Requirementspip install -r require.txt# 3. تثبيت ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. تثبيت MultiScaleDeformableAttentioncd src/utils/dependeency/XPose/models/UniPose/ops python setup.py build installcd - # يساوي cd ../../../../../../../
تأكد من تثبيت git-lfs وتنزيل كافة نقاط التحقق التالية إلى pretrained_weights :
تثبيت بوابة lfs استنساخ بوابة https://huggingface.co/jdh-algo/JoyVASA
نحن ندعم نوعين من أجهزة تشفير الصوت، بما في ذلك wav2vec2-base وhubert-chinese.
قم بتشغيل الأوامر التالية لتنزيل أوزان Hubert-Chinese المُدربة مسبقًا:
تثبيت بوابة lfs استنساخ بوابة https://huggingface.co/TencentGameMate/chinese-hubert-base
للحصول على الأوزان المدربة مسبقًا ذات قاعدة wav2vec2، قم بتشغيل الأوامر التالية:
تثبيت بوابة lfs استنساخ بوابة https://huggingface.co/facebook/wav2vec2-base-960h
ملحوظة
سيتم دعم نموذج توليد الحركة المزود بتشفير wav2vec2 لاحقًا.
# !pip install -U "huggingface_hub[cli]"huggingface-cli تنزيل KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
بالرجوع إلى Liveportrait لمزيد من طرق التنزيل.
pretrained_weights يجب أن يبدو دليل pretrained_weights النهائي كما يلي:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonملحوظة
يجب إعادة تسمية المجلد TencentGameMate:chinese-hubert-base في Windows باسم chinese-hubert-base .
الحيوان:
python inference.py -r الأصول/examples/imgs/joyvasa_001.png -a الأصول/examples/audios/joyvasa_001.wav --animation_mode Animal --cfg_scale 2.0
بشر:
python inference.py -r الأصول/examples/imgs/joyvasa_003.png -a الأصول/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
يمكنك تغيير cfg_scale للحصول على نتائج ذات تعبيرات وأوضاع مختلفة.
ملحوظة
قد يؤدي عدم تطابق وضع الرسوم المتحركة والصورة المرجعية إلى نتائج غير صحيحة.
استخدم الأمر التالي لبدء عرض الويب:
بيثون app.py
سيتم إنشاء العرض التوضيحي على http://127.0.0.1:7862.
إذا وجدت عملنا مفيدًا، فيرجى التفكير في الاستشهاد بنا:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}نود أن نشكر المساهمين في مستودعات LivePortrait، وOpen Facevid2vid، وInsightFace، وX-Pose، وDiffPoseTalk، وHallo، وwav2vec 2.0، وChinese Speech Pretrain، وQ-Align، وSyncnet، وVBench، على أبحاثهم المفتوحة وعملهم الاستثنائي.


