wikisearch
1.0.0
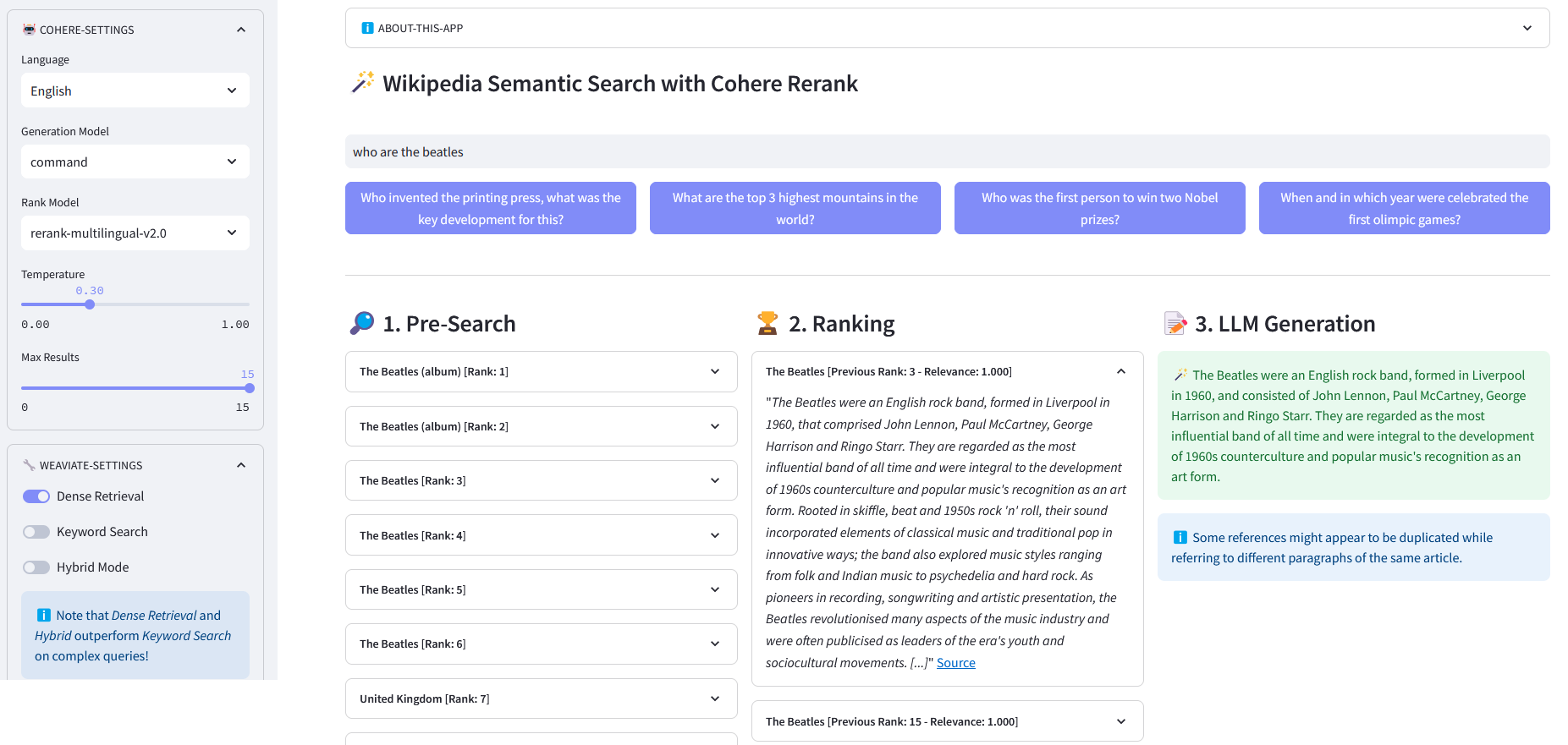
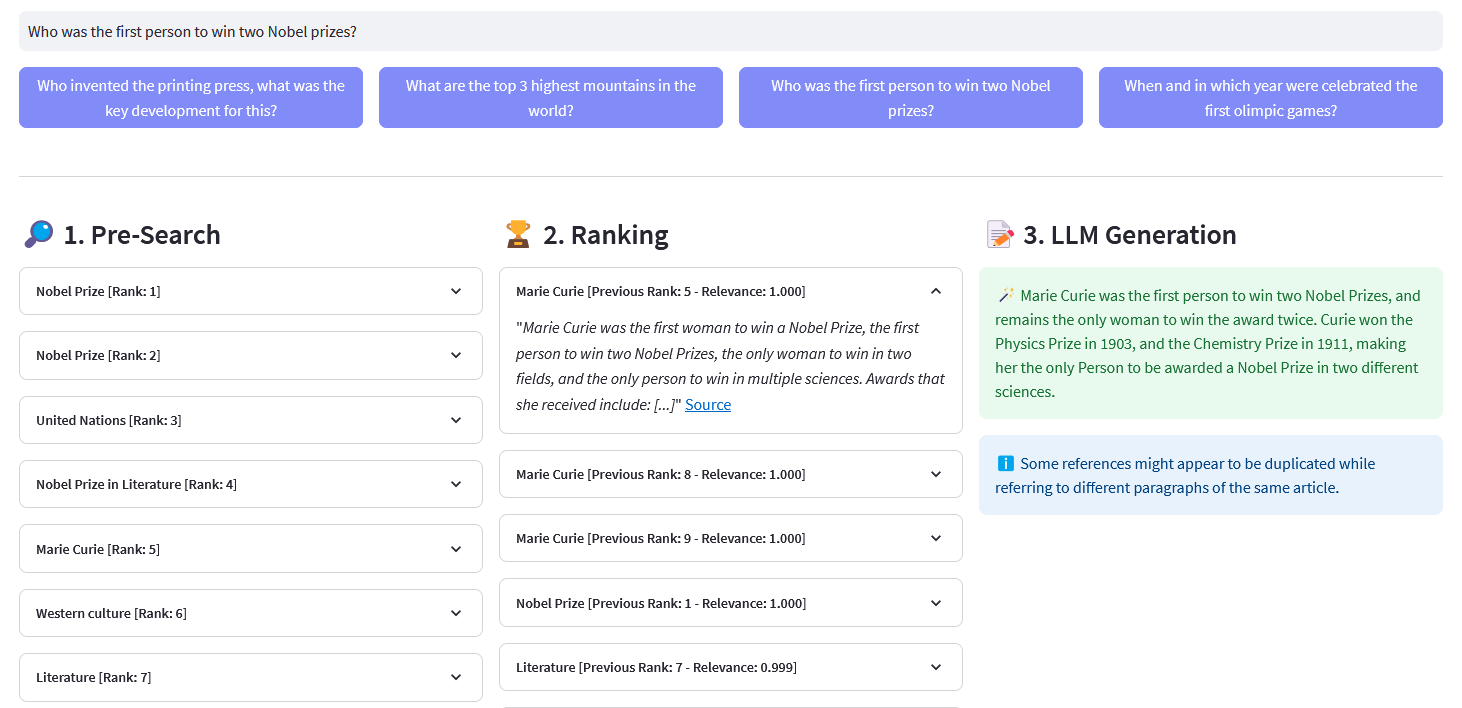
تطبيق Streamlit للبحث الدلالي متعدد اللغات في أكثر من 10 ملايين مستند ويكيبيديا تم توجيهها في عمليات التضمين بواسطة Weaviate. يعتمد هذا التنفيذ على مدونة Cohere ´Using LLMs for Search´ والمفكرة المقابلة لها. فهو يتيح مقارنة أداء البحث عن الكلمات الرئيسية والاسترجاع الكثيف والبحث المختلط للاستعلام عن مجموعة بيانات ويكيبيديا. ويوضح كذلك استخدام Cohere Rerank لتحسين دقة النتائج، وCohere Generate لتوفير استجابة بناءً على النتائج المرتبة المذكورة.
يشير البحث الدلالي إلى خوارزميات البحث التي تأخذ في الاعتبار القصد والمعنى السياقي لعبارات البحث عند توليد النتائج، بدلاً من التركيز فقط على مطابقة الكلمات الرئيسية. فهو يوفر نتائج أكثر دقة وذات صلة من خلال فهم الدلالات أو المعنى وراء الاستعلام.
التضمين عبارة عن ناقل (قائمة) لأرقام الفاصلة العائمة التي تمثل بيانات مثل الكلمات أو الجمل أو المستندات أو الصور أو الصوت. التمثيل الرقمي المذكور يجسد سياق البيانات وتسلسلها الهرمي وتشابهها. يمكن استخدامها للمهام النهائية مثل التصنيف والتجميع والكشف الخارجي والبحث الدلالي.
تم تصميم قواعد بيانات المتجهات، مثل Weaviate، خصيصًا لتحسين إمكانات التخزين والاستعلام عن عمليات التضمين. من الناحية العملية، تستخدم قاعدة بيانات المتجهات مجموعة من الخوارزميات المختلفة التي تشارك جميعها في البحث عن أقرب جار تقريبي (ANN). تعمل هذه الخوارزميات على تحسين البحث من خلال التجزئة أو التكميم أو البحث القائم على الرسم البياني.
البحث المسبق : البحث المسبق في تضمينات ويكيبيديا باستخدام مطابقة الكلمات الرئيسية أو الاسترجاع الكثيف أو البحث المختلط :
مطابقة الكلمات الرئيسية: تبحث عن الكائنات التي تحتوي على مصطلحات البحث في خصائصها. يتم تسجيل النتائج وفقًا لوظيفة BM25F:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" تنفيذ كلمة رئيسية البحث (استرجاع متفرق) في مقالات ويكيبيديا باستخدام التضمينات المخزنة في Weaviate المعلمات: - الاستعلام (str): استعلام البحث -. lang (str، اختياري): لغة المقالات الافتراضية هي 'en' - top_n (int، اختياري): عدد أهم النتائج المراد عرضها هو 10. العوائد: - قائمة: قائمة أهم المقالات بناءً على تسجيل BM25F """logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal",valueString": lang}response = (self.weaviate.query.get("مقالات"، self.WIKIPEDIA_PROPERTIES)
.with_bm25(الاستعلام=الاستعلام)
.with_where(where_filter)
.with_limit(top_n)
.يفعل()
)return Response["data"] ["احصل على"] ["مقالات"]الاسترجاع الكثيف: ابحث عن الكائنات الأكثر تشابهًا مع النص الخام (غير المتجه):
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" تنفيذ دلالية البحث (الاسترجاع المكثف) في مقالات ويكيبيديا باستخدام التضمينات المخزنة في Weaviate المعلمات: - الاستعلام (str): استعلام البحث -. lang (str، اختياري): لغة المقالات الافتراضية هي 'en' - top_n (int، اختياري): عدد أهم النتائج المراد عرضها هو 10. العوائد: - قائمة: قائمة أهم المقالات بناءً على التشابه الدلالي """logging.info("with_neartext()")nearText = {"concepts": [query]
}where_filter = {"path": ["lang"]،"operator": "Equal"، "valueString": lang}response = (self.weaviate.query.get("Articles"، self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(where_filter)
.with_limit(top_n)
.يفعل()
)return Response['data']['Get']['مقالات']البحث المختلط: ينتج نتائج بناءً على مجموعة مرجحة من النتائج من البحث عن كلمة رئيسية (bm25) والبحث المتجهي.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" تنفيذ عملية هجينة ابحث في مقالات ويكيبيديا باستخدام التضمينات المخزنة في Weaviate المعلمات: - query (str): استعلام البحث - lang (str، اختياري): لغة المقالات الافتراضية هي 'en' - top_n (int، اختياري): عدد أهم النتائج المراد عرضها هو 10. الإرجاعات: - القائمة: قائمة أهم المقالات استنادًا إلى التسجيل المختلط """". "with_hybrid()")where_filter = {"path": ["lang"]،"operator": "Equal"، "valueString": lang}response = (self.weaviate.query.get("Articles"، self.WIKIPEDIA_PROPERTIES)
.with_hybrid(الاستعلام=الاستعلام)
.with_where(where_filter)
.with_limit(top_n)
.يفعل()
)return Response["data"] ["احصل على"] ["مقالات"]إعادة الترتيب : تعمل أداة Cohere Rerank على إعادة تنظيم البحث المسبق عن طريق تعيين درجة الصلة بكل نتيجة بحث مسبق في ضوء استعلام المستخدم. بالمقارنة مع البحث الدلالي القائم على التضمين، فإنه يعطي نتائج بحث أفضل - خاصة بالنسبة للاستعلامات المعقدة والخاصة بالمجال.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query, document,top_n=10, model='rerank-english-v2.0') -> dict:""" إعادة ترتيب قائمة الاستجابات باستخدام واجهة برمجة تطبيقات إعادة الترتيب الخاصة بـ Cohere. المعلمات: - الاستعلام (str): استعلام البحث. - المستندات (القائمة): قائمة المستندات المراد إعادة ترتيبها. - top_n (int، اختياري): عدد النتائج التي تم إعادة ترتيبها بشكل افتراضي هو 10. - النموذج: النموذج الذي سيتم استخدامه لإعادة الترتيب هو "rerank-english-v2.0". dict: المستندات المعاد ترتيبها من واجهة برمجة تطبيقات Cohere """return self.cohere.rerank(query=query, document=documents, top_n=top_n, model=model)
المصدر: كوهير
إنشاء الإجابات : يقوم Cohere Generate بتأليف رد بناءً على النتائج المرتبة.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, thermo=0.2, model="command", lang="english") -> list:prompt = f""" استخدم المعلومات المقدمة أدناه للإجابة على الأسئلة في النهاية. / قم بتضمين بعض الحقائق الغريبة أو ذات الصلة المستخرجة من السياق. / قم بإنشاء الإجابة بلغة query.إذا لم تتمكن من تحديد لغة الاستعلام، استخدم {lang}. / إذا لم تكن إجابة السؤال موجودة في المعلومات المقدمة، فقم بإنشاء "الإجابة ليست في السياق". } --- السؤال: {query} """return self.cohere.generate(prompt=prompt,num_ Generations=1,max_tokens=1000,temperature=temperature,model=model,
)استنساخ المستودع:
[email protected]:dcarpintero/wikisearch.git
إنشاء وتفعيل بيئة افتراضية:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
تثبيت التبعيات:
pip install -r requirements.txt
إطلاق تطبيق الويب
streamlit run ./app.py
تم نشر تطبيق الويب التجريبي على Streamlit Cloud وهو متاح على https://wikisearch.streamlit.app/
إعادة ترتيب كوهير
سحابة مضاءة
أرشيفات التضمين: الملايين من مقالات ويكيبيديا المضمنة في العديد من اللغات
استخدام LLMs للبحث مع الاسترجاع الكثيف وإعادة الترتيب
قواعد بيانات المتجهات
بحث Weaviate المتجهات
بحث Weaviate BM25
Weaviate البحث الهجين


