EasyDetect
1.0.0

إطار عمل سهل الاستخدام لكشف الهلوسة متعدد الوسائط لـ MLLMs
شكر وتقدير • المعيار • العرض التوضيحي • نظرة عامة • ModelZoo • التثبيت • البدء السريع • الاقتباس
شكر وتقدير
ملخص
الهلوسة المتعددة الوسائط الموحدة
مجموعة البيانات: إحصائيات MHalluBench
الإطار: رسم توضيحي UniHD
ModelZoo
تثبيت
⏩بداية سريعة
الاقتباس
17-05-2024 تم قبول الورقة البحثية الموحدة للكشف عن الهلوسة لنماذج اللغات الكبيرة متعددة الوسائط من قبل المؤتمر الرئيسي ACL 2024.
2024-04-21 نقوم باستبدال جميع النماذج الأساسية في العرض التوضيحي بنماذجنا المدربة، مما يقلل بشكل كبير من وقت الاستدلال.
2024-04-21 قمنا بإصدار نموذج الكشف عن الهلوسة مفتوح المصدر HalDet-LLAVA، والذي يمكن تنزيله في Huggingface وmodelscope وWisemodel.
10-02-2024 قمنا بإصدار العرض التوضيحي لـ EasyDetect .
05-02-2024 نصدر الورقة البحثية: "الكشف الموحد عن الهلوسة لنماذج اللغات الكبيرة متعددة الوسائط" مع معيار MHaluBench الجديد! ونحن في انتظار أي تعليقات أو مناقشات حول هذا الموضوع :)
2023-10-20 تم إطلاق مشروع EasyDetect وهو قيد التطوير.
تمت المساعدة والإلهام في التنفيذ الجزئي لهذا المشروع من خلال مجموعات أدوات الهلوسة ذات الصلة بما في ذلك FactTool وWoodpecker وغيرها. يستفيد هذا المستودع أيضًا من المشروع العام المقدم من mPLUG-Owl، وMiniGPT-4، وLLaVA، وGroundingDINO، وMAERec . نحن نتبع نفس الترخيص للمصادر المفتوحة ونشكرهم على مساهماتهم في المجتمع.
EasyDetect عبارة عن حزمة منهجية تم اقتراحها كإطار عمل سهل الاستخدام للكشف عن الهلوسة لنماذج اللغات الكبيرة متعددة الوسائط (MLLMs) مثل GPT-4V وGemini وLlaVA في تجاربك البحثية.
الشرط الأساسي للكشف الموحد هو التصنيف المتماسك للفئات الرئيسية للهلوسة داخل MLLMs. تبحث ورقتنا بشكل سطحي في تصنيف الهلوسة التالي من منظور موحد:


الشكل 1: يهدف الكشف الموحد عن الهلوسة متعددة الوسائط إلى تحديد واكتشاف الهلوسة المتعارضة للطريقة على مستويات مختلفة مثل الكائن والسمة والنص المشهد، بالإضافة إلى الهلوسة المتضاربة مع الحقائق في كل من صورة إلى نص ونص إلى صورة جيل.
الهلوسة المتضاربة للطريقة. تقوم MLLMs أحيانًا بإنشاء مخرجات تتعارض مع المدخلات من طرق أخرى، مما يؤدي إلى مشكلات مثل الكائنات أو السمات أو نص المشهد غير الصحيح. يتضمن المثال الموجود في الشكل (أ) أعلاه MLLM الذي يصف بشكل غير دقيق زي الرياضي، ويعرض تعارضًا على مستوى السمة بسبب قدرة MLLM المحدودة على تحقيق محاذاة دقيقة للصورة النصية.
هلوسة تتعارض مع الحقائق. قد تتعارض مخرجات MLLMs مع المعرفة الواقعية الراسخة. يمكن لنماذج تحويل الصورة إلى نص أن تولد روايات تبتعد عن المحتوى الفعلي من خلال دمج حقائق غير ذات صلة، في حين أن نماذج تحويل النص إلى صورة قد تنتج صورًا تفشل في عكس المعرفة الواقعية الواردة في المطالبات النصية. تؤكد هذه التناقضات على كفاح MLLMs للحفاظ على الاتساق الواقعي، مما يمثل تحديًا كبيرًا في هذا المجال.
يتطلب الكشف الموحد عن الهلوسة متعددة الوسائط التحقق من كل زوج من صور النص a={v, x} ، حيث يشير v إما إلى الإدخال المرئي المقدم إلى MLLM، أو الإخراج المرئي الذي تم تصنيعه بواسطته. في المقابل، يشير x إلى الاستجابة النصية التي تم إنشاؤها بواسطة MLLM استنادًا إلى v أو استعلام المستخدم النصي لتجميع v . ضمن هذه المهمة، قد تحتوي كل x على مطالبات متعددة، يُشار إليها بـ a لتحديد ما إذا كان "هلوسة" أو "غير هلوسة"، وتوفير الأساس المنطقي لأحكامهم بناءً على التعريف المقدم للهلوسة. يشير اكتشاف الهلوسة النصية من LLMs إلى حالة فرعية في هذا الإعداد، حيث تكون v فارغة.
لتعزيز مسار البحث هذا، نقدم معيار التقييم التلوي MHaluBench، والذي يشمل المحتوى من إنشاء صورة إلى نص ومن نص إلى صورة، بهدف إجراء تقييم صارم للتقدم المحرز في أجهزة كشف الهلوسة متعددة الوسائط. يتم توفير المزيد من التفاصيل الإحصائية حول MHaluBench في الأشكال أدناه.
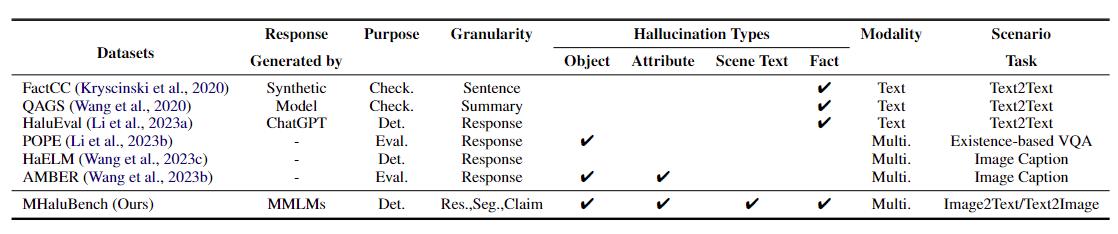
الجدول 1: مقارنة بين المعايير فيما يتعلق بالتحقق من الحقائق أو تقييم الهلوسة. "يفحص." يشير إلى التحقق من الاتساق الفعلي، "Eval". يدل على تقييم الهلوسة الناتجة عن LLMs مختلفة، ويستند استجابتها على LLMs مختلفة تحت الاختبار، في حين أن "Det." يجسد تقييم قدرة الكاشف في تحديد الهلوسة.
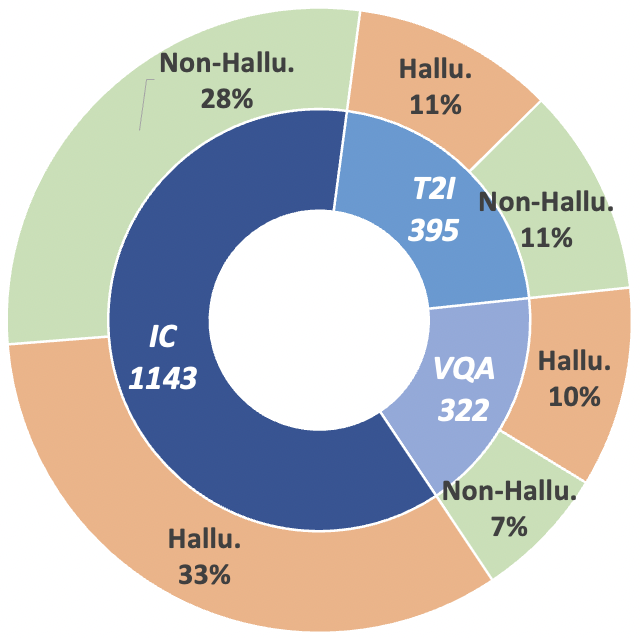
الشكل 2: إحصائيات البيانات على مستوى المطالبة لـ MHaluBench. يشير "IC" إلى التسمية التوضيحية للصورة ويشير "T2I" إلى تركيب النص إلى الصورة، على التوالي.
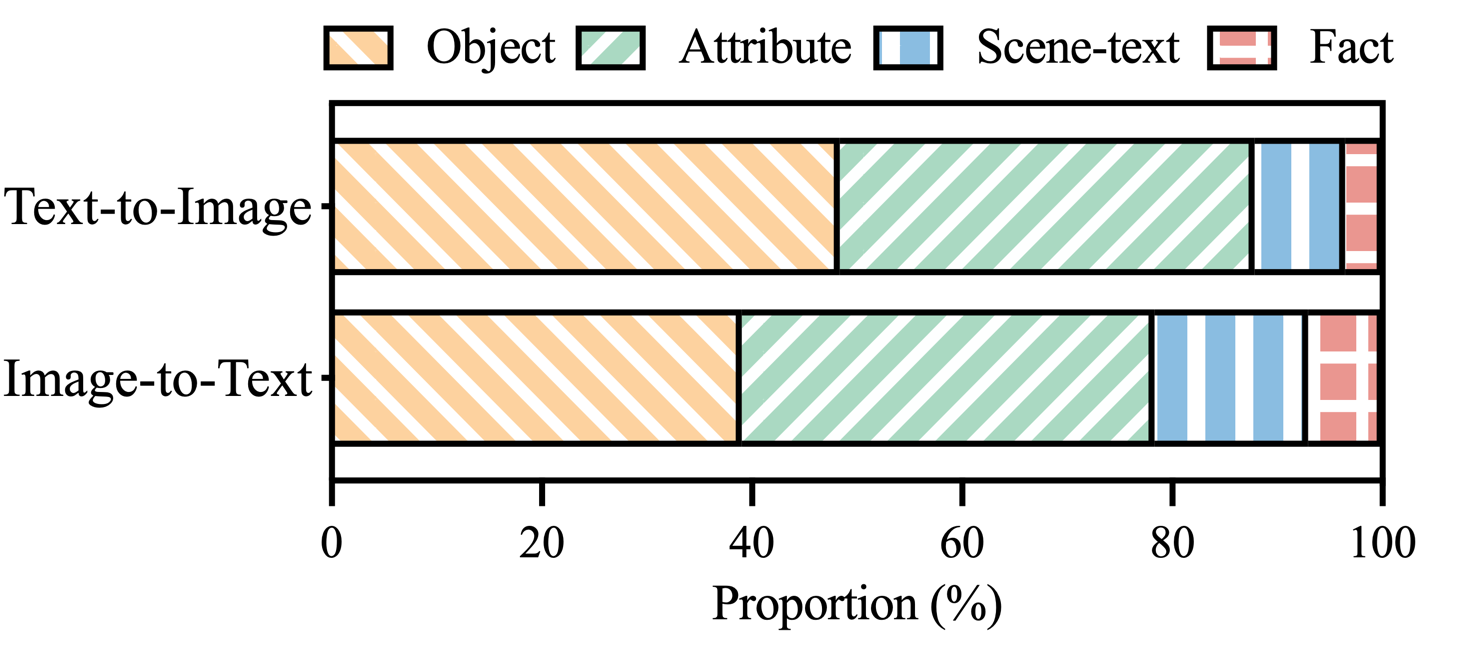
الشكل 3: توزيع فئات الهلوسة ضمن مطالبات MHaluBench التي تحمل علامات الهلوسة.
في مواجهة التحديات الرئيسية في اكتشاف الهلوسة، نقدم إطارًا موحدًا في الشكل 4 يتعامل بشكل منهجي مع تحديد الهلوسة متعدد الوسائط لكل من مهام تحويل الصورة إلى نص والنص إلى صورة. يستفيد إطار عملنا من نقاط القوة الخاصة بالمجال لمختلف الأدوات لجمع أدلة متعددة الوسائط بكفاءة لتأكيد الهلوسة.
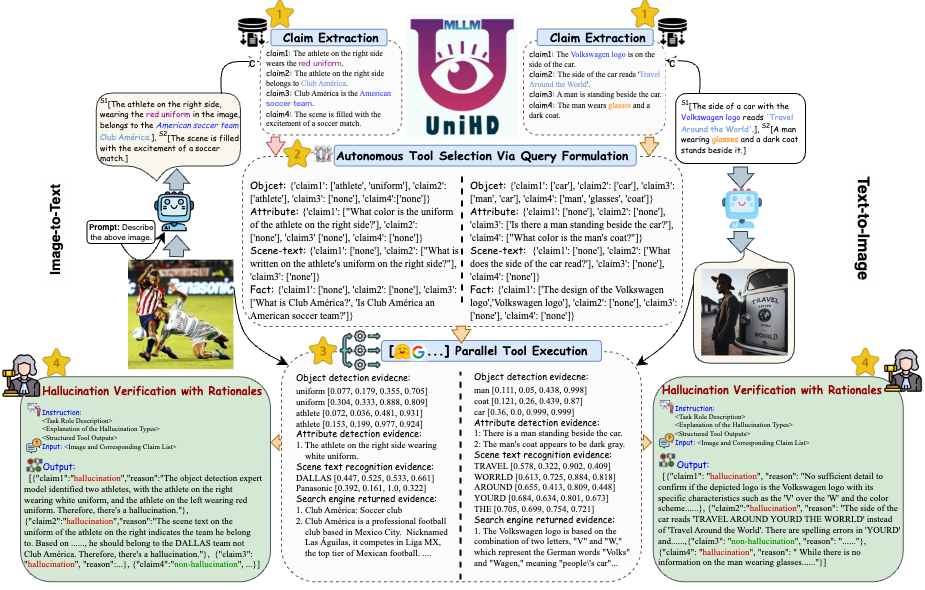
الشكل 4: الرسم التوضيحي المحدد لـ UniHD للكشف الموحد عن الهلوسة المتعددة الوسائط.
يمكنك تنزيل إصدارين من HalDet-LLaVA و7b و13b على ثلاث منصات: HuggingFace وModelScope وWiseModel.
| HuggingFace | ModelScope | نموذج حكيم |
|---|---|---|
| هالديت-لافا-7ب | هالديت-لافا-7ب | هالديت-لافا-7ب |
| هالديت-لافا-13ب | هالديت-لافا-13ب | هالديت-لافا-13ب |
نتائج مستوى المطالبة على مجموعة بيانات التحقق من الصحة
الفحص الذاتي (GPT-4V) يعني استخدام GPT-4V مع 0 أو 2 حالة
UniHD(GPT-4V/GPT-4o) يعني استخدام GPT-4V/GPT-4o مع اللقطات الثنائية ومعلومات الأداة
تعني HalDet (LLAVA) استخدام LLAVA-v1.5 المدرب على مجموعات بيانات القطارات الخاصة بنا
| نوع المهمة | نموذج | لجنة التنسيق الإدارية | المتوسط المسبق | أذكر المتوسط | ماك.F1 |
| صورة إلى نص | فحص ذاتي 0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| فحص ذاتي 2طلقة (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| هالديت (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| هالديت (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| يوني اتش دي (GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| يوني اتش دي (GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| تحويل النص إلى صورة | فحص ذاتي 0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| فحص ذاتي 2طلقة (GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| هالديت (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| هالديت (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| يوني اتش دي (GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| يوني اتش دي (GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
لعرض معلومات أكثر تفصيلاً حول HalDet-LLaVA ومجموعة بيانات القطار، يرجى الرجوع إلى الملف التمهيدي.
التثبيت للتنمية المحلية:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
تركيب الأدوات (GroundingDINO وMAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
نحن نقدم نموذجًا للتعليمات البرمجية للمستخدمين للبدء سريعًا في استخدام EasyDetect.
يمكن للمستخدمين بسهولة تكوين معلمات EasyDetect في ملف yaml أو استخدام المعلمات الافتراضية بسرعة في ملف التكوين الذي نقدمه. مسار ملف التكوين هو EasyDetect/pipeline/config/config.yaml
openai: api_key: أدخل مفتاح openai api الخاص بك
base_url: أدخل base_url، الافتراضي هو لا شيء
درجة الحرارة: 0.2
max_tokens: 1024الأداة:
الكشف: groundingdino_config: مسار GroundingDINO_SwinT_OGC.pymodel_path: مسار groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: مسار dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: مسار dbnetpp.pthmaerec_config: مسار maerec_b_union14m.pymaerec_path: مسار maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: مسار ملفات التخزين المؤقت لحفظ الصور المؤقتةBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: أدخل مفاتيح serper api الخاصة بكnippet_cnt: 10prompts:claim_generate: Pipeline/prompts/claim_generate.yaml
query_generate: خط الأنابيب/المطالبات/query_generate.yaml
تحقق: خط الأنابيب/المطالبات/verify.yamlرمز المثال
from Pipeline.run_pipeline import *pipeline = Pipeline()text = "يسمى المقهى الموجود في الصورة "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response,claim_list = Pipeline .run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
يرجى الإشارة إلى مستودعنا إذا كنت تستخدم EasyDetect في عملك.
@article{chen23factchd، المؤلف = {Xiang Chen وDuanzheng Song وHonghao Gui وChengxi Wang وNingyu Zhang وJiang Yong وFei Huang وChengfei Lv and Dan Zhang وHuajun Chen}، العنوان = {FactCHD: قياس الأداء للكشف عن الهلوسة المتعارضة مع الحقائق }، مجلة = {CoRR}، المجلد = {abs/2310.12086}، السنة = {2023}، URL = {https://doi.org/10.48550/arXiv.2310.12086}، doi = {10.48550/ARXIV.2310.12086}، eprinttype = {arXiv}، eprint = {2310.12086}، biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}، bibsource = {dblp ببليوغرافيا علوم الكمبيوتر، https://dblp.org}}@inproceedings{chen-etal-2024- الهلوسة الموحدة، العنوان = "الكشف الموحد عن الهلوسة لنماذج اللغات الكبيرة متعددة الوسائط"، المؤلف = "تشن، شيانغ ووانغ، وتشنشي، وشوي، وييدا وتشانغ، ونينغيو ويانغ، وشياويان ولي، وتشيانغ وشين، ويوي وليانغ، ولي وغو، وجينجي وتشن، وهواجون"، محرر = "كو، لون وي ومارتينز، أندريه and Srikumar, Vivek"، عنوان الكتاب = "وقائع الاجتماع السنوي الثاني والستين لجمعية اللغويات الحاسوبية (المجلد 1: طويل الأوراق)"، الشهر = أغسطس، العام = "2024"، العنوان = "بانكوك، تايلاند"، الناشر = "جمعية اللغويات الحاسوبية"، URL = "https://aclanthology.org/2024.acl-long.178" الصفحات = "3235--3252"،
}سنقدم صيانة طويلة الأمد لإصلاح الأخطاء وحل المشكلات وتلبية الطلبات الجديدة. لذلك إذا كان لديك أي مشاكل، يرجى طرح القضايا علينا.


