ssebowa
1.0.0
Ssebowa هي مكتبة بايثون مفتوحة المصدر توفر نماذج ذكاء اصطناعي توليدية، بما في ذلك:
ssebowa-llm: نموذج لغة كبير (LLM) لإنشاء النص،ssebowa-vllm: نموذج اللغة المرئية (VLLM) للفهم البصري،ssebowa-imagen: نموذج لتوليد الصور وضبطها بدقةSsebowa-vigen: نموذج لتوليد الفيديو.باستخدام Ssebowa، يمكنك بسهولة إنشاء نص وترجمة اللغات وكتابة أنواع مختلفة من المحتوى الإبداعي وإنشاء صور مخصصة والإجابة على أسئلتك بطريقة إعلامية.
للحصول على معلومات استخدام أكثر تفصيلاً، يرجى الرجوع إلى: الوثائق الفنية لـ Ssebowa
قبل تشغيل البرنامج النصي، تأكد من تثبيت المكتبات المطلوبة. يمكنك القيام بذلك عن طريق تنفيذ الأوامر التالية:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .ثم قم بتثبيت Ssebowa
pip install ssebowaإذا كنت تقوم بتشغيل هذه الأوامر في دفتر colab أو jupyter، فيرجى استخدام هذا،
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaيمكنك الآن الوصول إلى النماذج المختلفة عن طريق استيرادها من المكتبة:
Ssebowa-Imagen هو نموذج لتركيب الصور مفتوح المصدر يستخدم مزيجًا من diffusion modeling generative adversarial networks (GANs) لإنشاء صور عالية الجودة من text descriptions ويسمح أيضًا بتحويل صورك القليلة إلى custom model قادر على إنشاء صور مذهلة للموضوع chosen subject . فهو يستفيد من 100 billion dataset من الصور والأوصاف النصية، مما يمكّنه من التقاط الفروق الدقيقة في صور العالم الحقيقي بدقة وترجمة أوصاف النص بشكل فعال إلى تمثيلات مرئية مقنعة.
10-20 high-quality (jpg or png) مثل صورك أو صور صديقك أو منتجك أو حيواناتك الأليفة وما إلى ذلك ووضعها في دليل محدد.16GB or more . (إذا كنت تقوم بضبط SDXL، فستحتاج إلى 24 جيجابايت من VRAM.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()مثل لننشئ "قطة تجلس على رف الكتب"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm هو نموذج لغة مرئي كبير مفتوح المصدر (VLLM) تم تطويره بواسطة Ssebowa AI. إنها أداة قوية يمكن استخدامها لفهم الصور. يحتوي Ssebowa-vllm على 11 مليار معلمة مرئية و7 مليار معلمة لغة، مما يدعم فهم الصورة بدقة 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)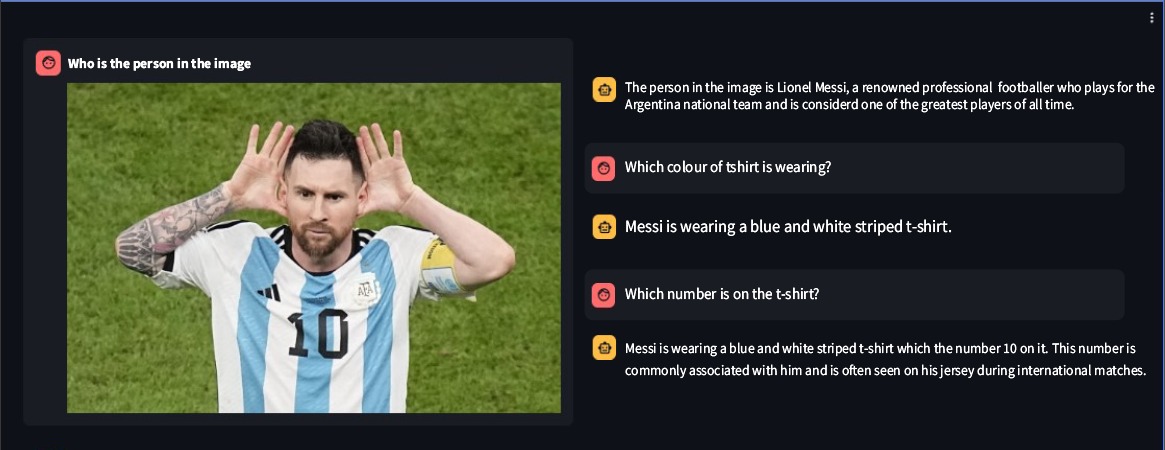
Ssebowa مفتوح للمساهمات! جاري تنفيذ التوجيهات..
تم إصدار Ssebowa بموجب ترخيص Apache 2.0.
إذا كان لديك أي أسئلة أو اقتراحات، فلا تتردد في فتح مشكلة على GitHub أو الاتصال بنا على [email protected]


