xTuring
0.1.8


يوفر xTuring ضبطًا سريعًا وفعالًا وبسيطًا لبرامج LLM مفتوحة المصدر، مثل Mistral وLLaMA وGPT-J والمزيد. من خلال توفير واجهة سهلة الاستخدام لضبط LLMs على البيانات والتطبيقات الخاصة بك، يجعل xTuring من السهل إنشاء وتعديل والتحكم في LLMs. يمكن إجراء العملية بأكملها داخل جهاز الكمبيوتر الخاص بك أو في السحابة الخاصة بك، مما يضمن خصوصية البيانات وأمنها.
مع xTuring يمكنك،
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))يمكنك العثور على مجلد البيانات هنا.
يسعدنا أن نعلن عن أحدث التحسينات لمكتبتنا xTuring :
LLaMA 2 - يمكنك استخدام نموذج LLaMA 2 وضبطه بدقة في تكوينات مختلفة: جاهز للاستخدام وجاهز للاستخدام بدقة INT8 وضبط LoRA الدقيق وضبط LoRA الدقيق بدقة INT8 و LoRA الدقيق الضبط بدقة INT4 باستخدام غلاف GenericModel و/أو يمكنك استخدام فئة Llama2 من xturing.models لاختبار النموذج وضبطه. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation - يمكنك الآن تقييم أي Causal Language Model في أي مجموعة بيانات. المقاييس المعتمدة حاليا هي perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 - يمكنك الآن استخدام وضبط أي LLM باستخدام INT4 Precision باستخدام GenericLoraKbitModel . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )يوصى باستكشاف المثال العملي Llama LoRA INT4 لفهم تطبيقه.
للحصول على رؤية موسعة، فكر في فحص مثال عمل GenericModel المتوفر في المستودع.

$ xturing chat -m " <path-to-model-folder> "
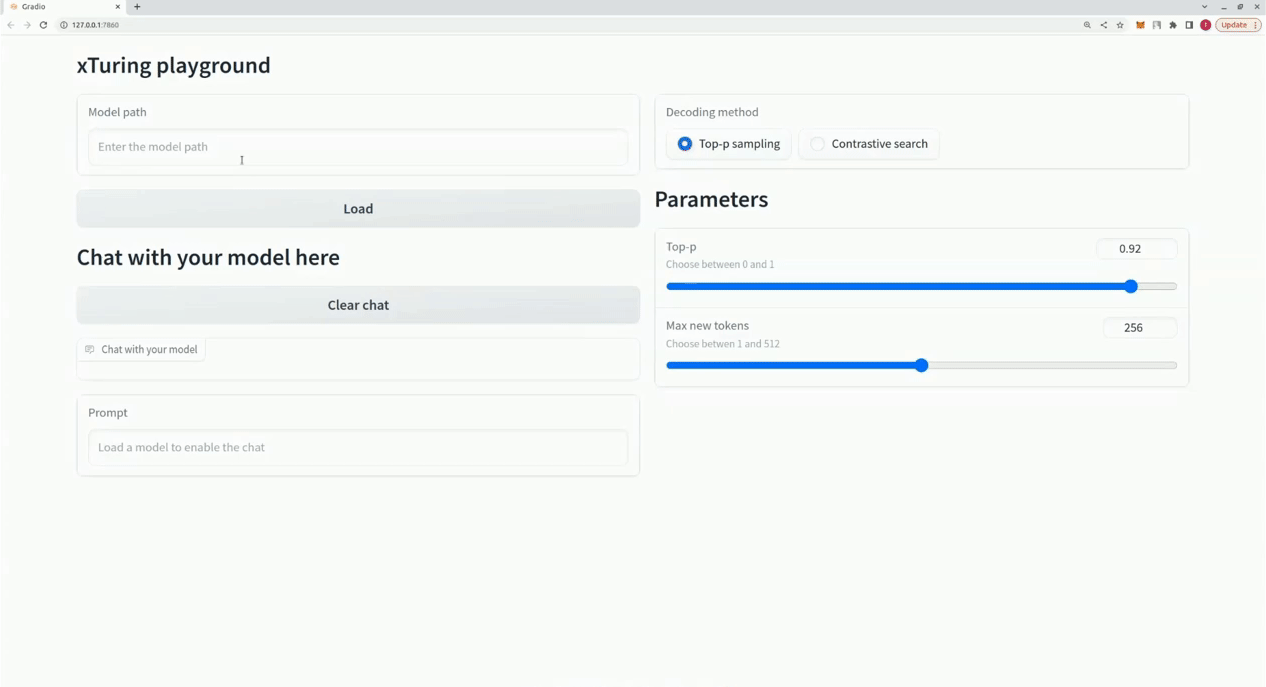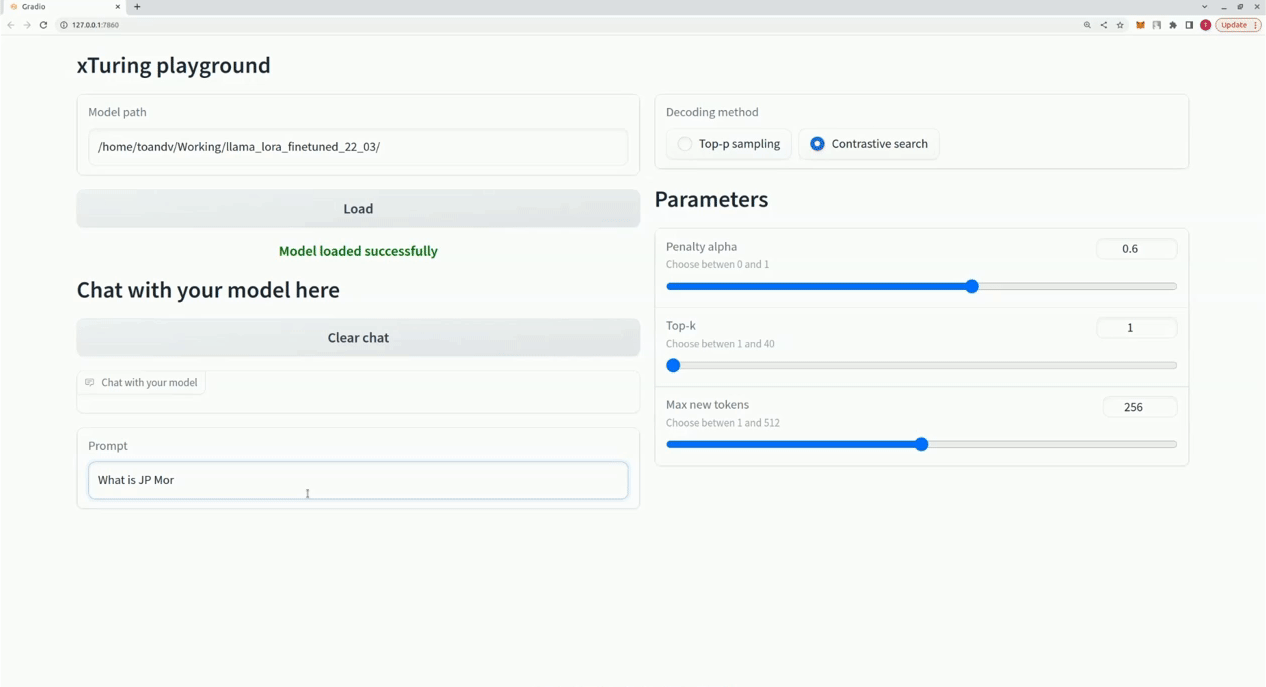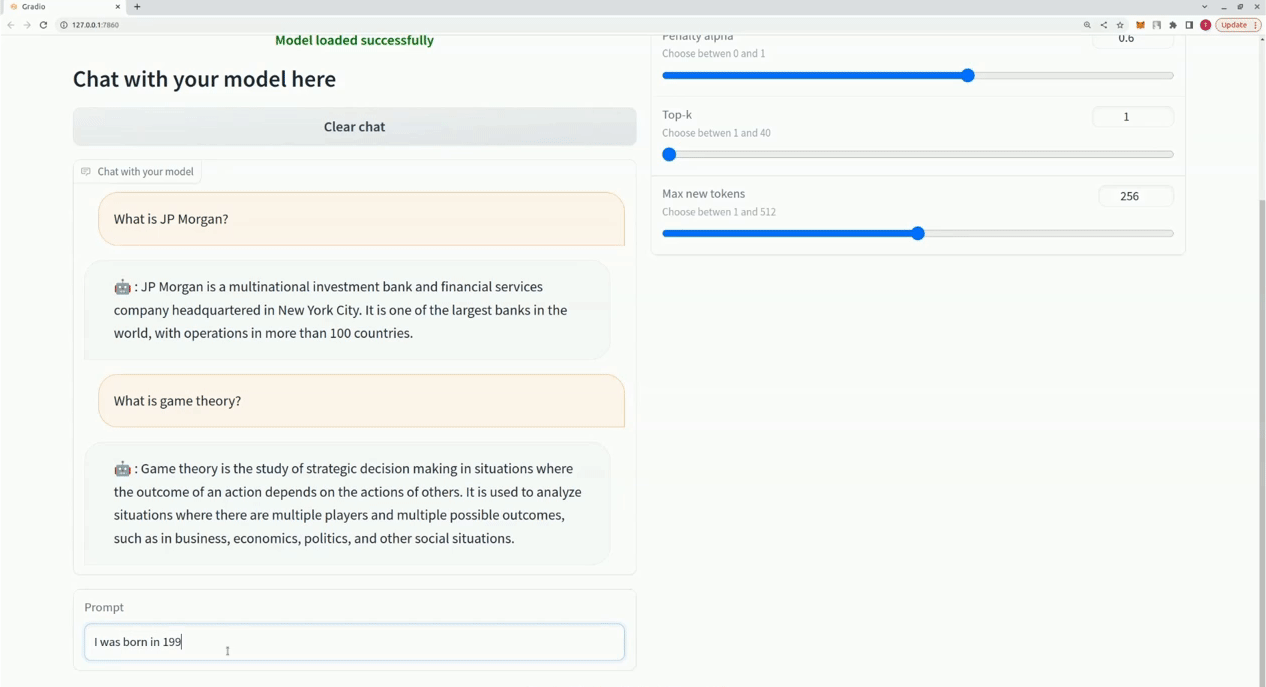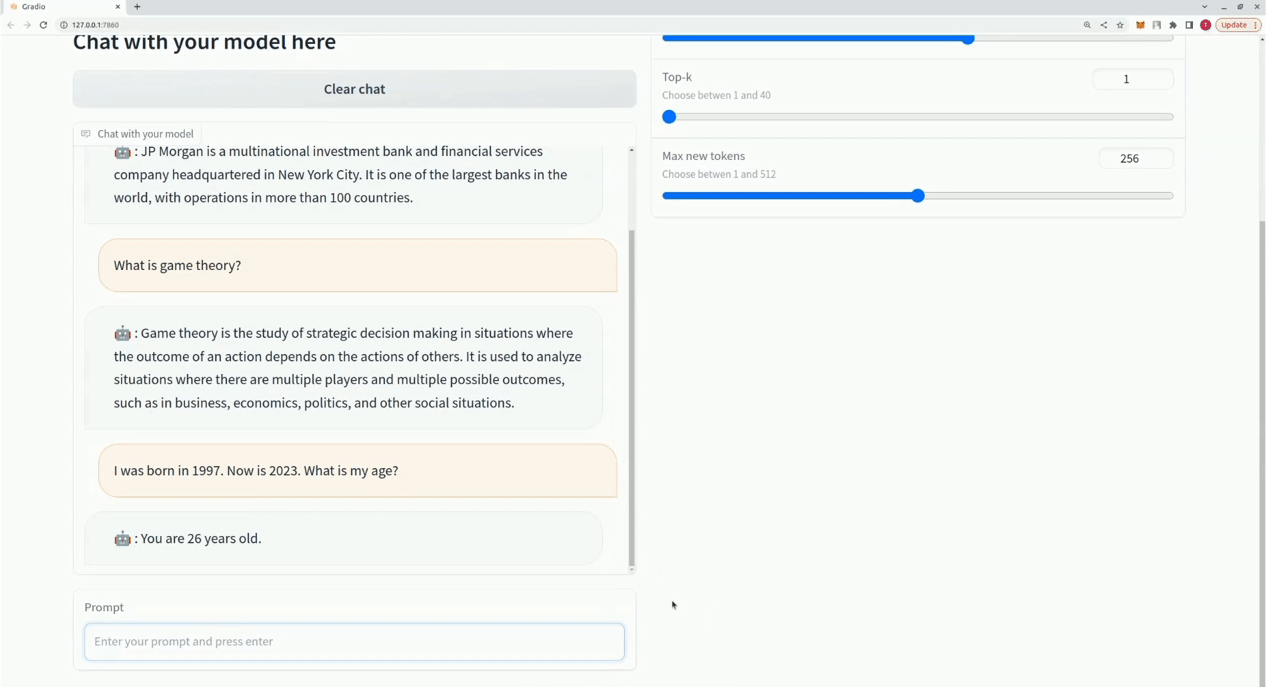
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI فيما يلي مقارنة لأداء تقنيات الضبط المختلفة في نموذج LLaMA 7B. نحن نستخدم مجموعة بيانات Alpaca للضبط الدقيق. تحتوي مجموعة البيانات على تعليمات 52K.
الأجهزة:
4xA100 وحدة معالجة الرسومات 40 جيجابايت، وذاكرة الوصول العشوائي لوحدة المعالجة المركزية 335 جيجابايت
معلمات الضبط الدقيق:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| لاما-7ب | DeepSpeed + تفريغ وحدة المعالجة المركزية | لورا + ديب سبيد | LoRA + DeepSpeed + تفريغ وحدة المعالجة المركزية |
|---|---|---|---|
| GPU | 33.5 جيجابايت | 23.7 جيجابايت | 21.9 جيجابايت |
| وحدة المعالجة المركزية | 190 جيجابايت | 10.2 جيجابايت | 14.9 جيجابايت |
| الوقت / العصر | 21 ساعة | 20 دقيقة | 20 دقيقة |
ساهم في ذلك من خلال إرسال نتائج أدائك على وحدات معالجة الرسومات الأخرى عن طريق إنشاء مشكلة تتعلق بمواصفات أجهزتك واستهلاك الذاكرة والوقت لكل فترة.
لقد قمنا بالفعل بضبط بعض النماذج التي يمكنك استخدامها كقاعدة لك أو البدء في اللعب بها. إليك كيفية تحميلها:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| نموذج | dataset | طريق |
|---|---|---|
| ديستيلGPT-2 لورا | الألبكة | x/distilgpt2_lora_finetuned_alpaca |
| لاما لورا | الألبكة | x/llama_lora_finetuned_alpaca |
فيما يلي قائمة بجميع النماذج المدعومة عبر فئة BaseModel من xTuring والمفاتيح المقابلة لها لتحميلها.
| نموذج | مفتاح |
|---|---|
| يزدهر | يزدهر |
| المخ | المخ |
| ديسيل جي بي تي-2 | ditilgpt2 |
| فالكون-7ب | الصقر |
| جلاكتيكا | galactica |
| جي بي تي-ي | com.gptj |
| جي بي تي-2 | gpt2 |
| اللاما | اللاما |
| لاما2 | اللاما2 |
| أوبت-1.3ب | اختيار |
ما ورد أعلاه هو المتغيرات الأساسية لـ LLMs. فيما يلي القوالب للحصول على إصدارات LoRA و INT8 و INT8 + LoRA و INT4 + LoRA .
| إصدار | نموذج |
|---|---|
| لورا | <model_key>_lora |
| إنت8 | <model_key>_int8 |
| INT8 + لورا | <model_key>_lora_int8 |
** من أجل تحميل إصدار INT4+LoRA لأي نموذج، ستحتاج إلى الاستفادة من فئة GenericLoraKbitModel من xturing.models . وفيما يلي كيفية استخدامه:
model = GenericLoraKbitModel ( '<model_path>' ) يمكن استبدال model_path بالدليل المحلي الخاص بك أو بأي نموذج مكتبة HuggingFace مثل facebook/opt-1.3b .
LLaMA و GPT-J و GPT-2 و OPT و Cerebras-GPT و Galactica و Bloom Generic model Falcon-7B إذا كانت لديك أي أسئلة، يمكنك إنشاء مشكلة في هذا المستودع.
يمكنك أيضًا الانضمام إلى خادم Discord الخاص بنا وبدء مناقشة في قناة #xturing .
تم ترخيص هذا المشروع بموجب ترخيص Apache 2.0 - راجع ملف الترخيص للحصول على التفاصيل.
باعتبارنا مشروعًا مفتوح المصدر في مجال سريع التطور، فإننا نرحب بالمساهمات من جميع الأنواع، بما في ذلك الميزات الجديدة والوثائق الأفضل. يرجى قراءة دليل المساهمة الخاص بنا لمعرفة كيف يمكنك المشاركة.


