AttackVLM
1.0.0
[صفحة المشروع] | [الشرائح] | [ارشيف] | [مستودع البيانات]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

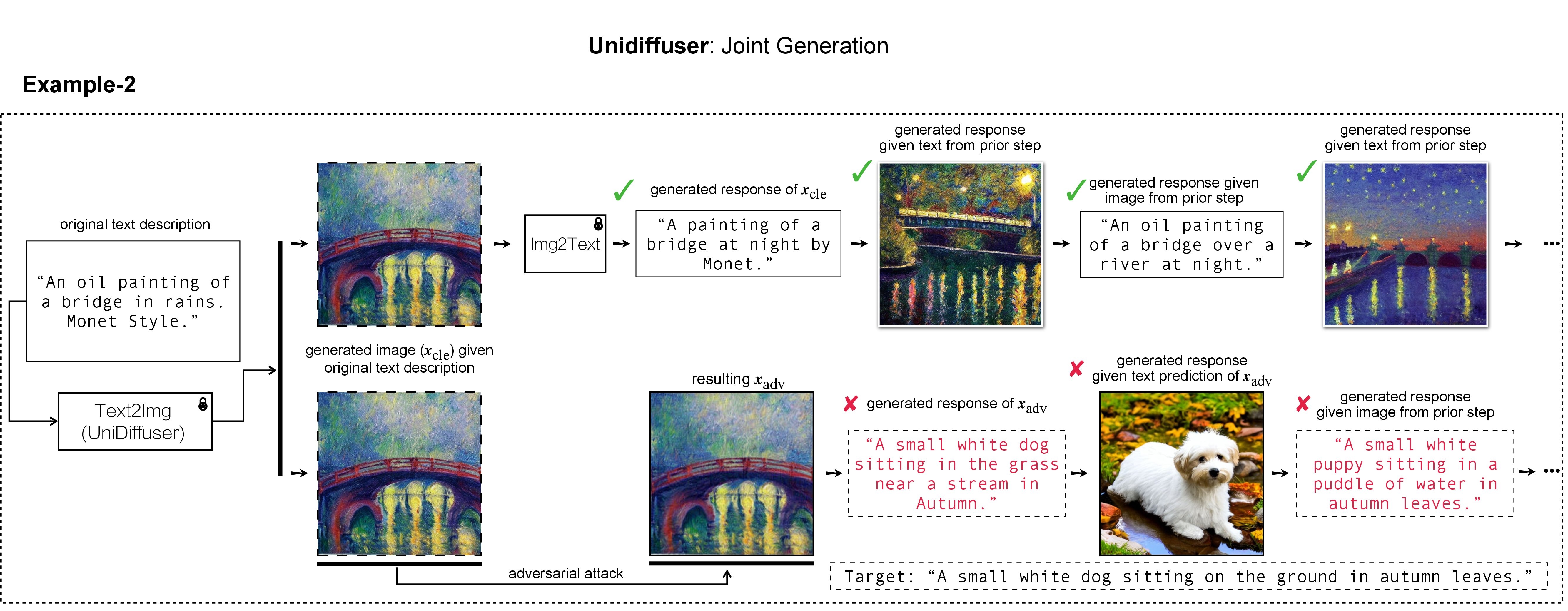
في عملنا، استخدمنا DALL-E وMidjourney وStable Diffusion لتوليد الصورة المستهدفة وعرضها. بالنسبة للتجارب واسعة النطاق، فإننا نطبق "الانتشار المستقر" لتوليد الصور المستهدفة. لتثبيت Stable Diffusion، نبدأ بيئة الشقة الخاصة بنا باتباع نماذج الانتشار الكامنة. يمكن إنشاء بيئة كوندا أساسية مناسبة تسمى ldm وتنشيطها باستخدام:
conda env create -f environment.yaml
conda activate ldm
لاحظ أنه بالنسبة لنماذج الضحايا المختلفة، سنتبع تطبيقاتها الرسمية وبيئات كوندا.
 كما تمت مناقشته في بحثنا، لتحقيق هجوم مستهدف مرن، فإننا نستفيد من نموذج تحويل النص إلى صورة مُدرب مسبقًا لإنشاء صورة مستهدفة مع تسمية توضيحية واحدة باعتبارها النص المستهدف. وبالتالي، بهذه الطريقة يمكنك تحديد التسمية التوضيحية المستهدفة للهجوم بنفسك!
كما تمت مناقشته في بحثنا، لتحقيق هجوم مستهدف مرن، فإننا نستفيد من نموذج تحويل النص إلى صورة مُدرب مسبقًا لإنشاء صورة مستهدفة مع تسمية توضيحية واحدة باعتبارها النص المستهدف. وبالتالي، بهذه الطريقة يمكنك تحديد التسمية التوضيحية المستهدفة للهجوم بنفسك!
نحن نستخدم Stable Diffusion أو DALL-E أو Midjourney كمولدات لتحويل النص إلى صورة في تجاربنا. هنا، نستخدم Stable Diffusion للتوضيح (شكرًا للمصادر المفتوحة!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
بعد ذلك، قم بإعداد التسميات التوضيحية المستهدفة الكاملة من MS-COCO، أو قم بتنزيل نسختنا المعالجة والمنظفة:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
وانقله إلى ./stable-diffusion/ . في التجارب، يمكن للمرء أن يأخذ عينة عشوائية من مجموعة فرعية من التسميات التوضيحية لـ COCO (على سبيل المثال، 10 ، 100 ، 1K ، 10K ، 50K ) للهجوم الخصم. على سبيل المثال، لنفترض أننا أخذنا عينات عشوائية من التسميات التوضيحية لـ 10K COCO كنص مستهدف لدينا وقمنا بتخزينها في الملف التالي:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
يمكن الحصول على الصور المستهدفة h_ξ(c_tar) عبر Stable Diffusion من خلال قراءة المطالبة النصية من التسميات التوضيحية لعينات COCO، مع البرنامج النصي أدناه و txt2img_coco.py (يُرجى نقل txt2img_coco.py إلى ./stable-diffusion/ ، لاحظ أن المعلمات التشعبية يمكن أن تكون تعديل حسب تفضيلاتك):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
حيث يتم توفير ckpt بواسطة Stable Diffusion v1 ويمكن تنزيله هنا: sd-v1-4-full-ema.ckpt.
يمكن العثور على تفاصيل التنفيذ الإضافية لإنشاء تحويل النص إلى صورة بواسطة Stable Diffusion هنا.
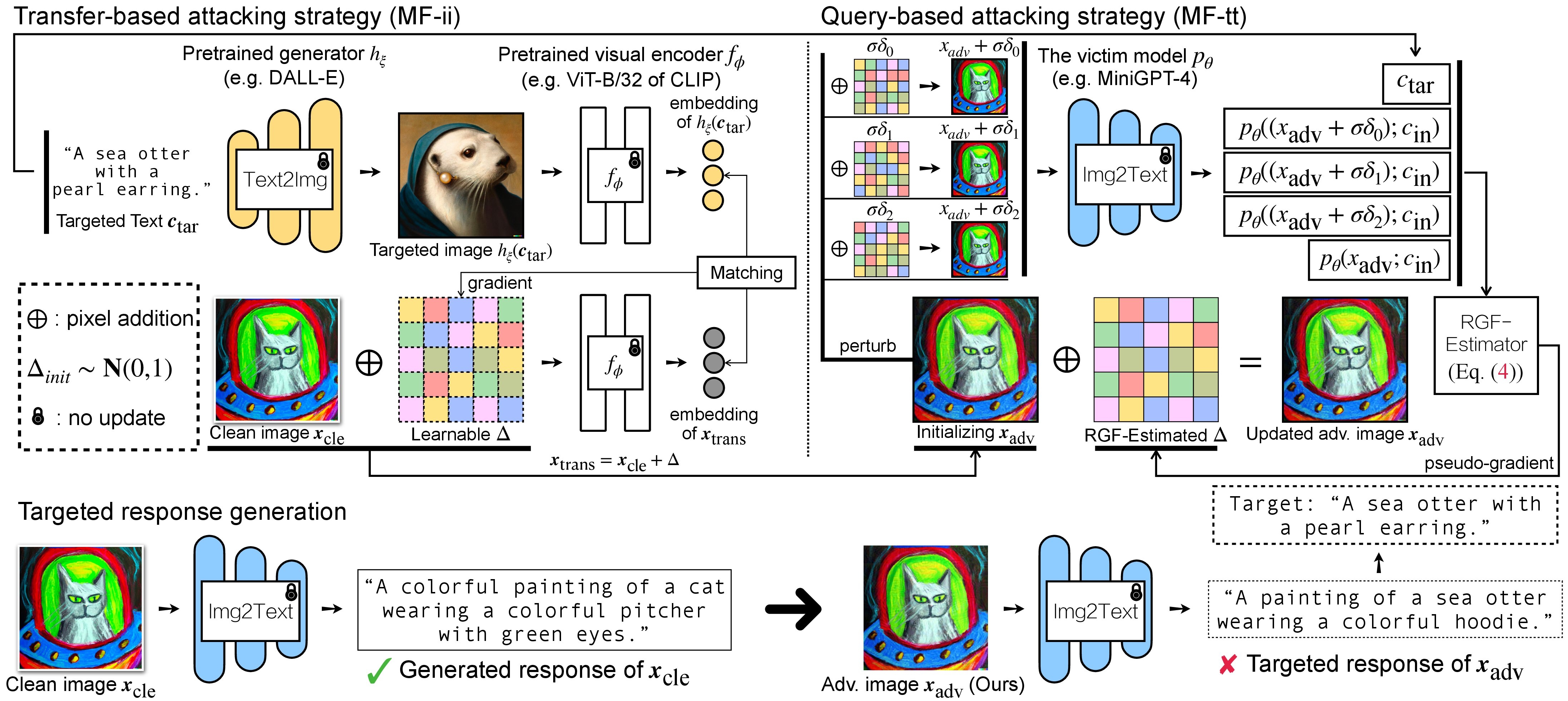
هناك خطوتان للهجوم العدائي لـ VLMs: (1) استراتيجية الهجوم القائمة على النقل و(2) استراتيجية الهجوم القائمة على الاستعلام باستخدام (1) كتهيئة. بالنسبة لنماذج BLIP/BLIP-2/Img2Prompt، يرجى الرجوع إلى ./LAVIS_tool . هنا، نستخدم Unidiffuser على سبيل المثال.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
بعد ذلك، قم بإنشاء بيئة conda مناسبة باسم unidiffuser باتباع الخطوات الواردة هنا، وقم بإعداد أوزان النموذج المقابلة (نستخدم uvit_v1.pth كوزن U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
سيتم تخزين صور adv المصممة x_trans في dir of white-box transfer images المحددة في --output . بعد ذلك، نقوم بتحويل الصورة إلى نص وتخزين الاستجابة الناتجة لـ x_trans. ويمكن تحقيق ذلك عن طريق:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
حيث سيتم تخزين الاستجابات التي تم إنشاؤها في dir of white-box transfer captions بتنسيق .txt . سوف نستخدمها لتقدير التدرج الزائف عبر مقدر RGF.
MF-ii + MF-tt (على سبيل المثال، 8 بكسل) bash _train_trans_and_query_fixed_budget.sh
من ناحية أخرى، إذا كنت تريد إجراء هجوم قائم على النقل+الاستعلام بميزانية اضطراب منفصلة ، فإننا نقدم أيضًا نصًا برمجيًا:
bash _train_trans_and_query_more_budget.sh
هنا، نستخدم wandb لرصد المتوسط المتحرك لدرجة CLIP ديناميكيًا (على سبيل المثال، RN50، ViT-B/32، ViT-L/14، وما إلى ذلك) لتقييم التشابه بين (أ) الاستجابة المتولدة (للترانس/ الاستعلام عن الصور) و (ب) النص المستهدف المحدد مسبقًا c_tar .
مثال موضح على النحو التالي، حيث يشير الخط المنقط إلى المتوسط المتحرك لدرجة CLIP (للتعليقات التوضيحية للصور) بعد الاستعلام: 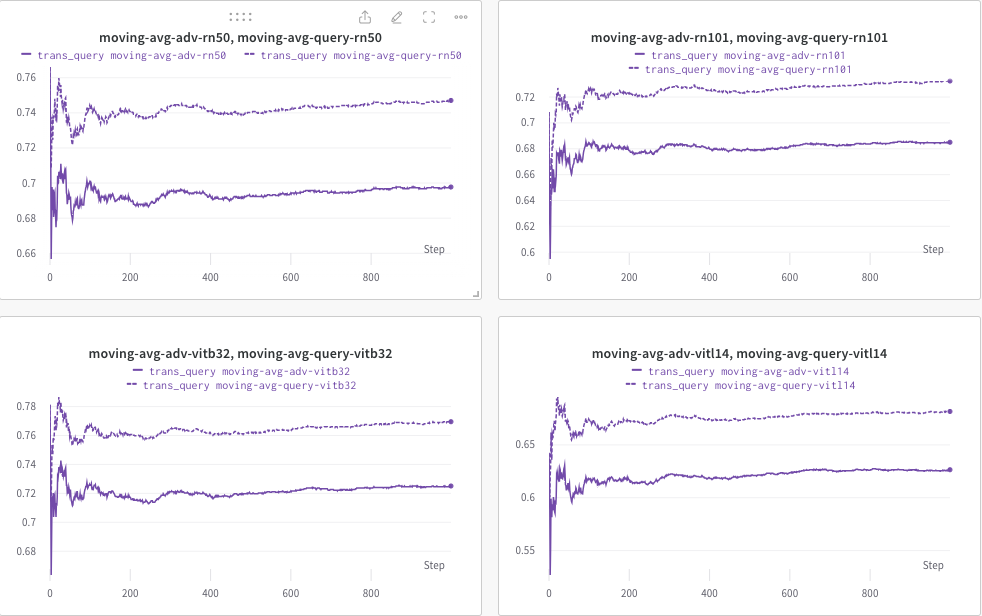
وفي الوقت نفسه، سيتم تخزين التسمية التوضيحية للصورة بعد الاستعلام ويمكن تحديد الدليل بواسطة --output .
إذا وجدت هذا المشروع مفيدًا في بحثك، فيرجى التفكير في الاستشهاد بمقالتنا:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
وفي الوقت نفسه، بحث ذو صلة يهدف إلى تضمين العلامة المائية في نماذج الانتشار (متعددة الوسائط):
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
نحن نقدر التنفيذ الأساسي الرائع لـ MiniGPT-4 وLLaVA وUnidiffuser وLAVIS وCLIP. نشكر أيضًاMetaAI على توفير مصادر مفتوحة لنقاط فحص LLaMA الخاصة بهم. نشكر SiSi على تقديم بعض الصور الممتعة والممتعة التي تم إنشاؤها بواسطة @Midjourney في بحثنا.


