LipGER
Initial Release
هذا هو التنفيذ الرسمي لمقالنا LipGER: تصحيح الأخطاء التوليدي المكيف بصريًا للتعرف القوي على الكلام تلقائيًا في InterSpeech 2024 والذي تم اختياره للعرض الشفهي .
يمكنك تنزيل بيانات LipHyp من هنا!
pip install -r requirements.txt
قم أولاً بإعداد نقاط التفتيش باستخدام:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfلرؤية كافة نقاط التفتيش المتاحة، قم بتشغيل:
python scripts/download.py | grep Llama-2لمزيد من التفاصيل، يمكنك أيضًا الرجوع إلى هذا الرابط، حيث يمكنك أيضًا إعداد نقاط فحص أخرى لنماذج أخرى. على وجه التحديد، نستخدم TinyLlama في تجاربنا.
نقطة التفتيش متاحة هنا. بعد التحميل قم بتغيير مسار نقطة التفتيش هنا.
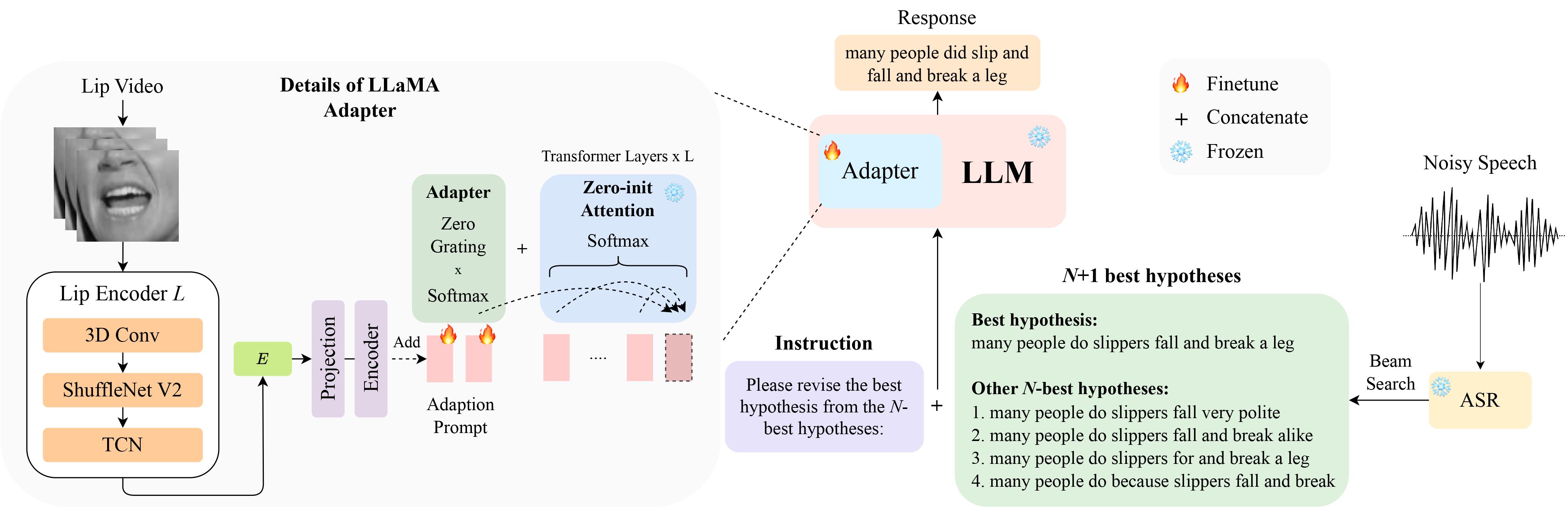
تتوقع شركة LipGER أن يكون كل ملف التدريب والقيمة والاختبار بتنسيق Sample_data.json. يبدو مثيل في الملف كما يلي:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
تحتاج إلى تمرير ملفات الكلام من خلال نموذج ASR مُدرب قادر على إنشاء فرضيات N-best. نحن نقدم طريقتين في هذا الريبو لمساعدتك في تحقيق ذلك. لا تتردد في استخدام أساليب أخرى.
pip install whisper ثم قمت بتشغيل nhyps.py من مجلد data ، فيجب أن تكون جيدًا! لاحظ أنه بالنسبة لكلتا الطريقتين، فإن الأولى في القائمة هي أفضل فرضية والأخرى هي فرضيات N-best (يتم تمريرها كحقل قائمة nhyps_base لـ JSON وتستخدم لإنشاء موجه في الخطوات التالية).
بالإضافة إلى ذلك، تستخدم الأساليب المتوفرة الكلام فقط كمدخل. من أجل توليد أفضل فرضيات N السمعية والبصرية، استخدمنا Auto-AVSR. إذا كنت بحاجة إلى مساعدة بشأن الكود، يرجى إثارة مشكلة!
بافتراض أن لديك مقاطع فيديو مقابلة لجميع ملفات الكلام الخاصة بك، اتبع هذه الخطوات لاقتصاص عائد الاستثمار الفموي من مقاطع الفيديو.
python crop_mouth_script.py
python covert_lip.py
سيؤدي هذا إلى تحويل عائد استثمار mp4 إلى hdf5، وسيغير الكود مسار عائد استثمار mp4 إلى عائد استثمار hdf5 في نفس ملف json. يمكنك الاختيار من بين كاشفات "mediapipe" و"retinaface" عن طريق تغيير "الكاشف" بشكل افتراضي.yaml
بعد حصولك على فرضيات N-best، قم بإنشاء ملف JSON بالتنسيق المطلوب. لا نوفر كودًا محددًا لهذا الجزء، حيث قد يختلف إعداد البيانات من شخص لآخر، ولكن يجب أن يكون الكود بسيطًا. مرة أخرى، اطرح مشكلة إذا كانت لديك أي شكوك!
لا تستخدم نصوص تدريب LipGER صيغة JSON للتدريب أو التقييم. تحتاج إلى تحويلها إلى ملف pt. يمكنك تشغيل Convert_to_pt.py لتحقيق ذلك! قم بتغيير model_name وفقًا لرغبتك في السطر 27 وأضف المسار إلى JSON الخاص بك في السطر 58.
لضبط LipGER، فقط قم بتشغيل:
sh finetune.sh
حيث تحتاج إلى تعيين قيم data يدويًا (مع اسم مجموعة البيانات)، --train_path و-- --val_path (مع المسارات المطلقة للتدريب وملفات .pt الصالحة).
للاستدلال، قم أولاً بتغيير المسارات المعنية في lipger.py ( exp_path و checkpoint_dir )، ثم قم بتشغيل (باستخدام وسيطة مسار بيانات الاختبار المناسبة):
sh infer.sh
كود قص عائد استثمار الفم مستوحى من Visual_Speech_Recognition_for_Multiple_Languages.
كودنا الخاص بـ LipGER مستوحى من RobustGER. يرجى الاستشهاد بأوراقهم أيضًا إذا وجدت ورقتنا أو الكود الخاص بنا مفيدًا.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


