mae
1.0.0
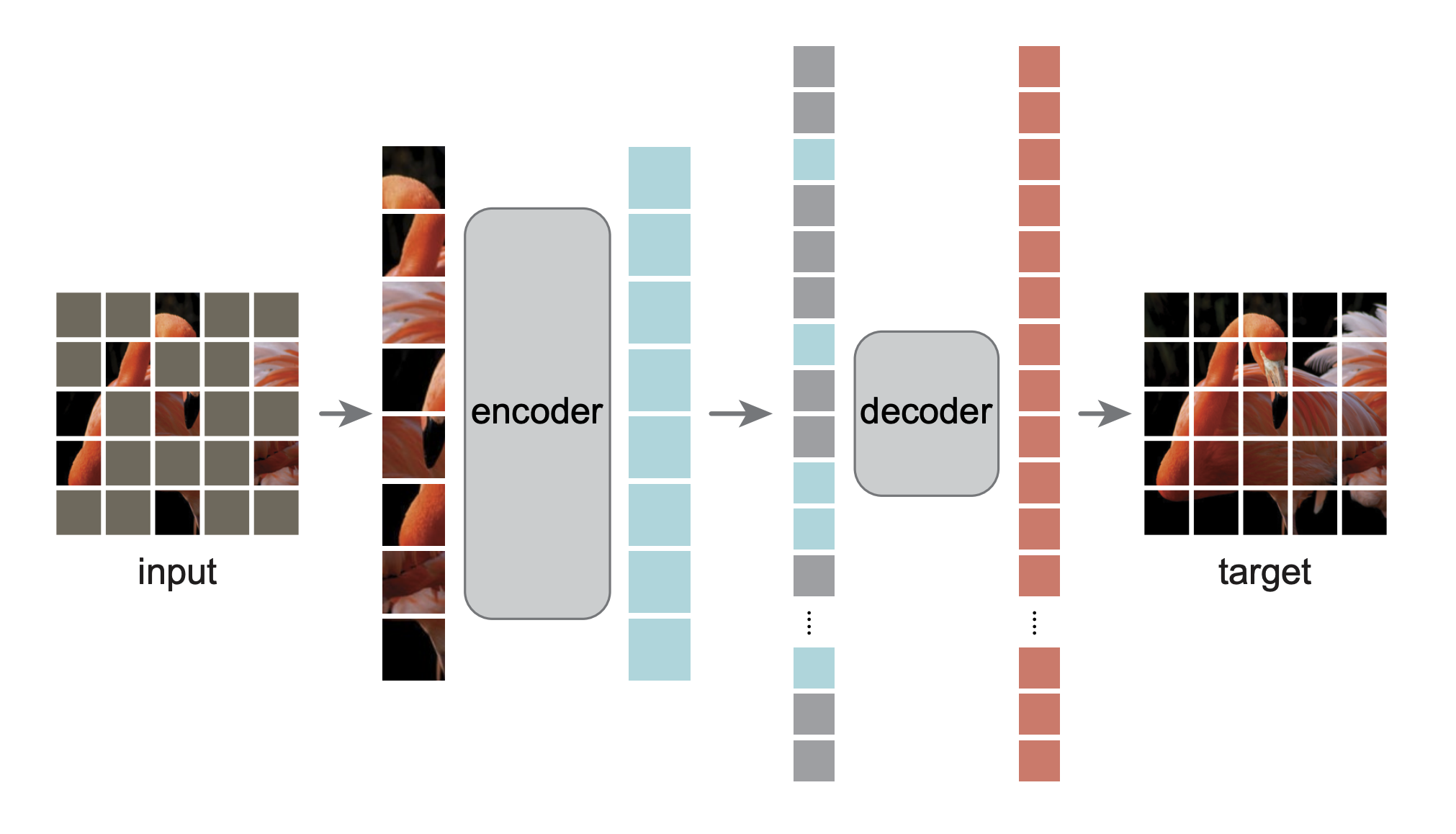
هذا هو إعادة تنفيذ PyTorch/GPU للورقة التي تمثل أجهزة التشفير التلقائي المقنعة متعلمين رؤية قابلين للتطوير:
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
تم التنفيذ الأصلي في TensorFlow+TPU. تتم إعادة التنفيذ هذه في PyTorch+GPU.
هذا الريبو هو تعديل على DeiT repo. التثبيت والتحضير يتبعان هذا الريبو.
يعتمد هذا الريبو على timm==0.3.2 ، والذي يلزم إصلاحه للعمل مع PyTorch 1.8.1+.
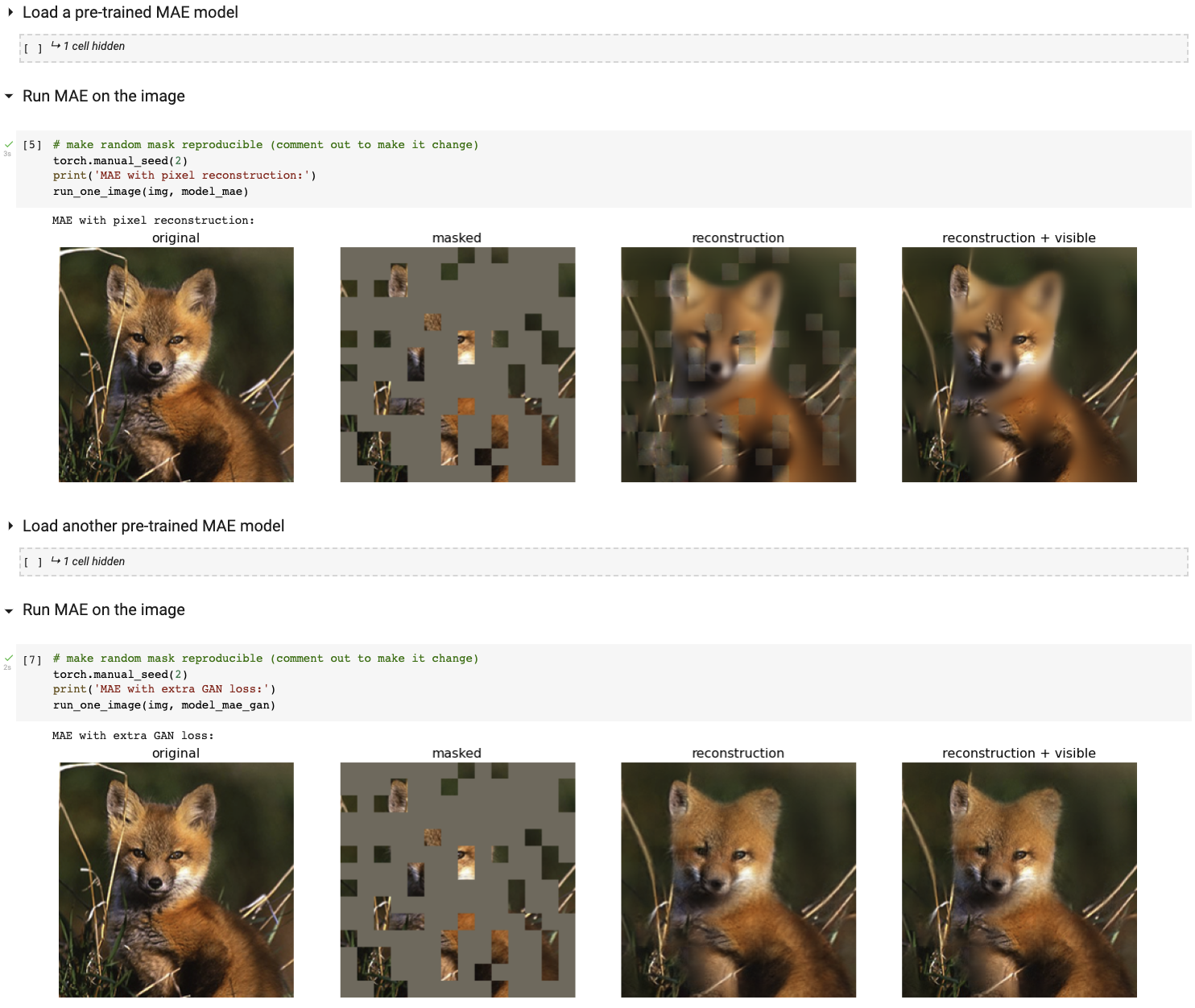
قم بتشغيل عرض التصور التفاعلي الخاص بنا باستخدام دفتر Colab (لا حاجة إلى وحدة معالجة الرسومات):
يوفر الجدول التالي نقاط التفتيش المدربة مسبقًا المستخدمة في الورق، والتي تم تحويلها من TF/TPU إلى PT/GPU:
| قاعدة ViT | ViT-Large | ViT-ضخم | |
|---|---|---|---|
| نقطة تفتيش مدربة مسبقا | تحميل | تحميل | تحميل |
| MD5 | 8cad7c | b8b06e | 9bdbb0 |
توجد تعليمات الضبط الدقيق في FINETUNE.md.
من خلال ضبط هذه النماذج المدربة مسبقًا، نحتل المرتبة الأولى في مهام التصنيف هذه (المفصلة في الورقة):
| فيتامين ب | فيتامين-L | فيتامين-H | فيتامين-H 448 | السابق الأفضل | |
|---|---|---|---|---|---|
| ImageNet-1K (لا توجد بيانات خارجية) | 83.6 | 85.9 | 86.9 | 87.8 | 87.1 |
| فيما يلي تقييم لنفس أوزان النموذج (تم ضبطها بدقة في ImageNet-1K الأصلي): | |||||
| ImageNet-Corruption (معدل الخطأ) | 51.7 | 41.8 | 33.8 | 36.8 | 42.5 |
| ImageNet-العدائية | 35.9 | 57.1 | 68.2 | 76.7 | 35.8 |
| ImageNet-التسليم | 48.3 | 59.9 | 64.4 | 66.5 | 48.7 |
| إيماجينت-سكيتش | 34.5 | 45.3 | 49.6 | 50.9 | 36.0 |
| فيما يلي نقل التعلم عن طريق ضبط MAE المدرب مسبقًا على مجموعة البيانات المستهدفة: | |||||
| علماء الطبيعة 2017 | 70.5 | 75.7 | 79.3 | 83.4 | 75.4 |
| علماء الطبيعة 2018 | 75.4 | 80.1 | 83.0 | 86.8 | 81.2 |
| علماء الطبيعة 2019 | 80.5 | 83.4 | 85.7 | 88.3 | 84.1 |
| الأماكن205 | 63.9 | 65.8 | 65.9 | 66.8 | 66.0 |
| الأماكن365 | 57.9 | 59.4 | 59.8 | 60.3 | 58.0 |
تعليمات ما قبل التدريب موجودة في PRETRAIN.md.
هذا المشروع تحت رخصة CC-BY-NC 4.0. راجع الترخيص للحصول على التفاصيل.


