mage ai
0.9.75
امنح فريق البيانات الخاص بك قوى سحرية.
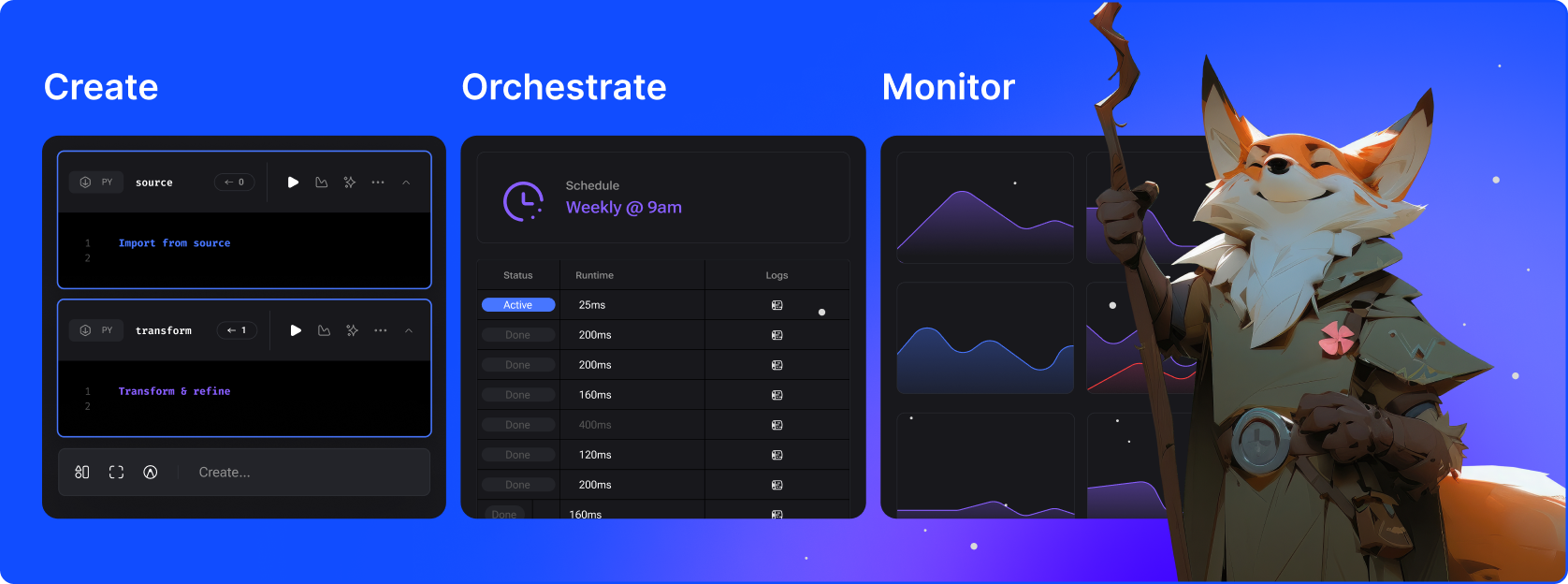
Mage هو إطار مختلط لتحويل البيانات ودمجها. فهو يجمع بين أفضل ما في العالمين: مرونة أجهزة الكمبيوتر المحمولة ودقة التعليمات البرمجية المعيارية.
استخراج ومزامنة البيانات من مصادر الطرف الثالث.
قم بتحويل البيانات باستخدام خطوط الأنابيب في الوقت الفعلي والدُفعات باستخدام Python وSQL وR.
قم بتحميل البيانات إلى مستودع البيانات الخاص بك أو مستودع البيانات الخاص بك باستخدام موصلاتنا المعدة مسبقًا.
قم بتشغيل ومراقبة وتنسيق الآلاف من خطوط الأنابيب دون فقدان النوم.
بالإضافة إلى المئات من الميزات على مستوى المؤسسات وابتكارات البنية التحتية والمفاجآت السحرية.
 للفرق. منصة مُدارة بالكامل لدمج البيانات وتحويلها. للفرق. منصة مُدارة بالكامل لدمج البيانات وتحويلها. |  استضافة ذاتية. نظام لبناء وتشغيل وإدارة خطوط أنابيب البيانات. استضافة ذاتية. نظام لبناء وتشغيل وإدارة خطوط أنابيب البيانات. |
للحصول على وثائق حول البدء، وكيفية التطوير، وكيفية النشر إلى الإنتاج، قم بمراجعة البث المباشر
بوابة وثائق المطور .
الطريقة الموصى بها لتثبيت أحدث إصدار من Mage هي من خلال Docker باستخدام الأمر التالي:
عامل ميناء يسحب mageai/mageai: الأحدث
يمكنك أيضًا تثبيت Mage باستخدام النقطة أو conda، على الرغم من أن هذا قد يسبب مشكلات في التبعية بدون البيئة المناسبة.
نقطة تثبيت mage-ai
conda install -c conda-forge mage-ai
هل تبحث عن المساعدة؟ أسرع طريقة للبدء هي مراجعة وثائقنا هنا.
هل تبحث عن أمثلة سريعة؟ افتح مشروعًا تجريبيًا مباشرة في متصفحك أو راجع أدلةنا.
قم ببناء وتشغيل خط أنابيب للبيانات باستخدام تطبيقنا التجريبي .
تحذير
العرض التجريبي المباشر متاح للجميع، يرجى عدم حفظ أي شيء حساس (مثل كلمات المرور والأسرار وما إلى ذلك).

انقر على الصورة لتشغيل الفيديو
| التنسيق | جدولة وإدارة خطوط أنابيب البيانات مع إمكانية الملاحظة. | |
| دفتر الملاحظات | محرر Python وSQL وR التفاعلي لخطوط أنابيب البيانات الترميزية. | |
| تكامل البيانات | مزامنة البيانات من مصادر الطرف الثالث إلى وجهاتك الداخلية. | |
| تدفق خطوط الأنابيب | استيعاب وتحويل البيانات في الوقت الحقيقي. | |
| dbt | يمكنك إنشاء نماذج dbt وتشغيلها وإدارتها باستخدام Mage. |
نموذج لخط أنابيب بيانات محدد عبر 3 ملفات ➝
تحميل البيانات ➝
@data_loaderdefload_csv_from_file() -> pl.DataFrame:return pl.read_csv('default_repo/titanic.csv')تحويل البيانات ➝
@transformerdef Select_columns_from_df(df: pl.DataFrame, *args) -> pl.DataFrame:return df[['Age', 'Fare', 'Survived']]
تصدير البيانات ➝
@data_exporterdefexport_titanic_data_to_disk(df: pl.DataFrame) -> لا شيء:df.to_csv('default_repo/titanic_transformed.csv')

