Transformer in generating dialogue
1.0.0
الكود عبارة عن تطبيق لـ Paper Attention وهو كل ما تحتاجه للعمل في مهام إنشاء الحوار مثل: Chatbot و Text Generation وما إلى ذلك.
شكرا لكل الأصدقاء الذين أثاروا المشاكل وساعدوا في حلها. مساهمتك مهمة جدًا لتحسين هذا المشروع. نظرًا للدعم المحدود لـ "وضع الرسم البياني الثابت" في البرمجة، قررنا نقل الميزات إلى الإصدار 2.0.0-beta1. ومع ذلك، إذا كنت قلقًا بشأن المشكلات الناجمة عن بناء عامل الإرساء وإنشاء الخدمة مع مشكلات الإصدار، فلا نزال نحتفظ بإصدار قديم من التعليمات البرمجية المكتوبة بواسطة الوضع حريصًا باستخدام إصدار Tensorflow 1.12.x للإشارة.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
كما نعلم جميعًا، يمكن استخدام نظام الترجمة في تنفيذ نموذج المحادثة فقط عن طريق استبدال جملتين مختلفتين بالأسئلة والأجوبة. بعد كل شيء، نموذج المحادثة الأساسي المسمى "تسلسل إلى تسلسل" تم تطويره من نظام الترجمة. فلماذا لا نعمل على تحسين كفاءة نموذج المحادثة في توليد الحوارات؟
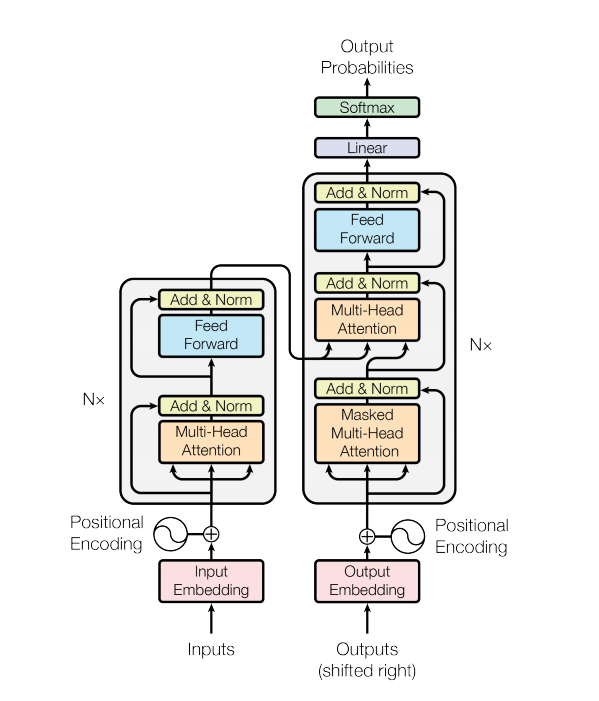
مع تطوير النماذج المستندة إلى BERT، يتم تحديث المزيد والمزيد من مهام البرمجة اللغوية العصبية (nlp) باستمرار. ومع ذلك، فإن نموذج اللغة غير موجود في مهام BERT مفتوحة المصدر. ليس هناك شك في أنه لا يزال أمامنا طريق طويل لنقطعه على هذا الطريق.
يتعامل نموذج المحول مع المدخلات ذات الحجم المتغير باستخدام مجموعات من طبقات الاهتمام الذاتي بدلاً من شبكات RNN أو شبكات CNN. تتمتع هذه البنية العامة بعدد من المزايا والعلامات الخاصة. والآن لنخرجهم:
في الإصدار الأحدث من الكود الخاص بنا ، نكمل التفاصيل الموضحة ورقيًا.
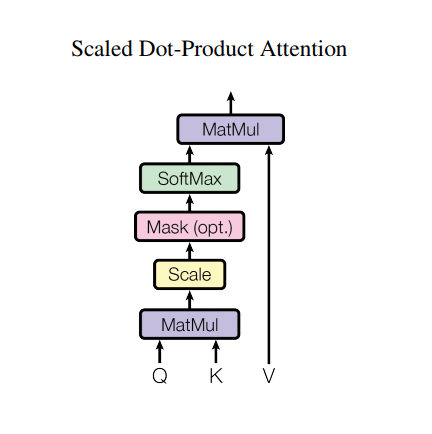
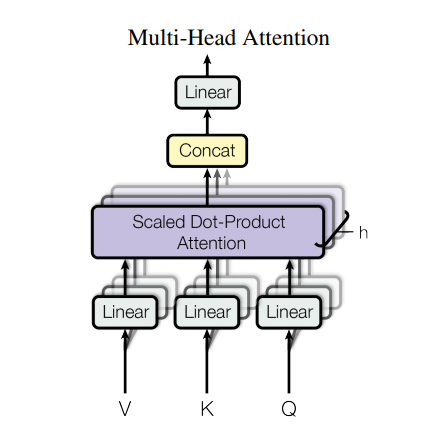
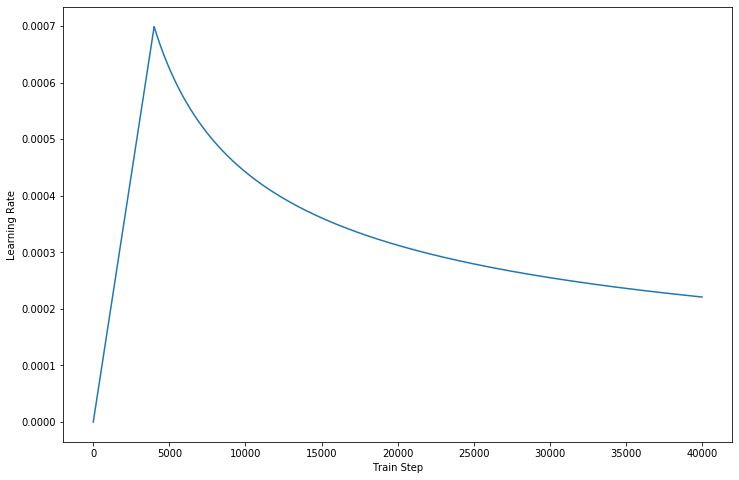
ومع ذلك، فإن مثل هذه البنية القوية لا تزال لديها بعض السلبيات:
data/ المجلد.params.py إذا أردت ذلك.make_dic.py لإنشاء ملفات المفردات إلى مجلد جديد يسمى dictionary .train.py لبناء النموذج. سيتم تخزين نقطة التفتيش في مجلد checkpoint بينما يمكن العثور على ملفات أحداث Tensorflow في logdir .eval.py لتقييم النتيجة باستخدام بيانات الاختبار. سيتم تخزين النتيجة في مجلد Results .GPU لتسريع معالجة التدريب، فيرجى إعداد جهازك في الكود. (يدعم التدريب متعدد العمال) - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
إذا حاولت استخدام AutoGraph لتسريع عملية التدريب الخاصة بك، فيرجى التأكد من أن مجموعات البيانات مبطنة بطول ثابت. بسبب أنه سيتم تفعيل عملية إعادة بناء الرسم البياني أثناء التدريب، مما قد يؤثر على الأداء. يضمن الكود الخاص بنا أداء الإصدار 2.0 فقط، ويمكن للإصدارات الأقل محاولة الرجوع إليه.
شكرا للمحول و Tensorflow


