customer support chatbot
1.0.0
Chatbot هو برنامج كمبيوتر يجري محادثة بطريقة تشبه الإنسان. يطبق هذا المشروع برنامج chatbot الذي يحاول الإجابة على أسئلة المستخدمين بصفته وكيل دعم العملاء. تم تنفيذ برامج الدردشة التالية لدعم العملاء: AppleSupport، وAmazonHelp، وUber_Support، وDelta، وSpotifyCares. تم تدريب Chatbots على المحادثات المتاحة للجمهور بين دعم العملاء والمستخدمين على تويتر.
يتم تنفيذ Chatbot كتسلسل لتسلسل نموذج التعلم العميق مع الاهتمام. يعتمد المشروع في الغالب على Bahdanau et al. 2014، لونج وآخرون. 2015. وفينيالس وآخرون، 2015..
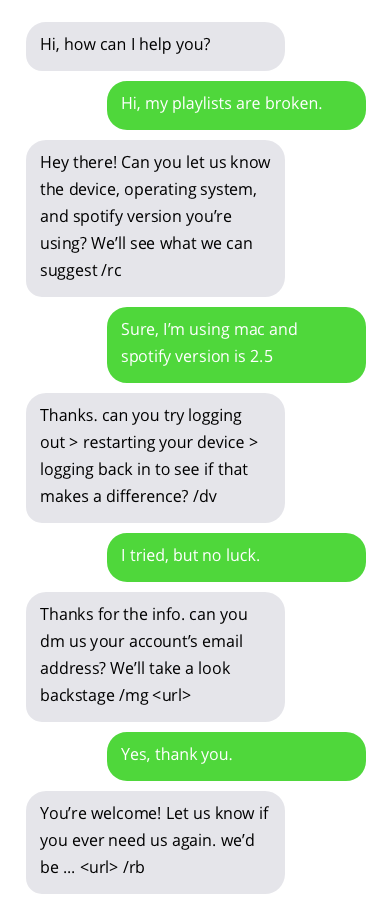
نماذج من المحادثات مع روبوتات الدردشة لدعم العملاء. المحادثات مع برامج الدردشة الآلية ليست مثالية ولكنها تظهر نتائج واعدة. إجابات Chatbot موجودة في فقاعات رمادية.
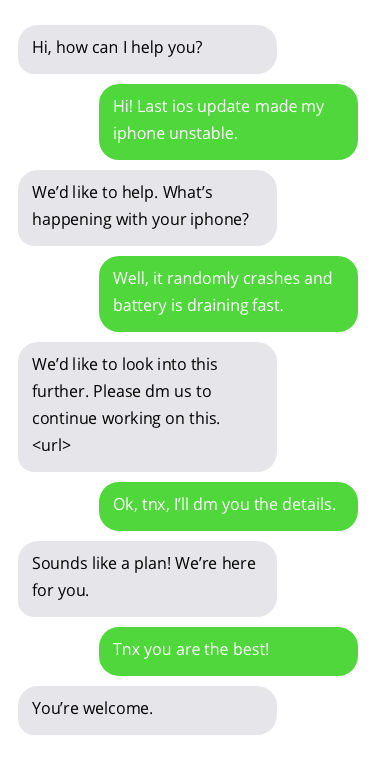
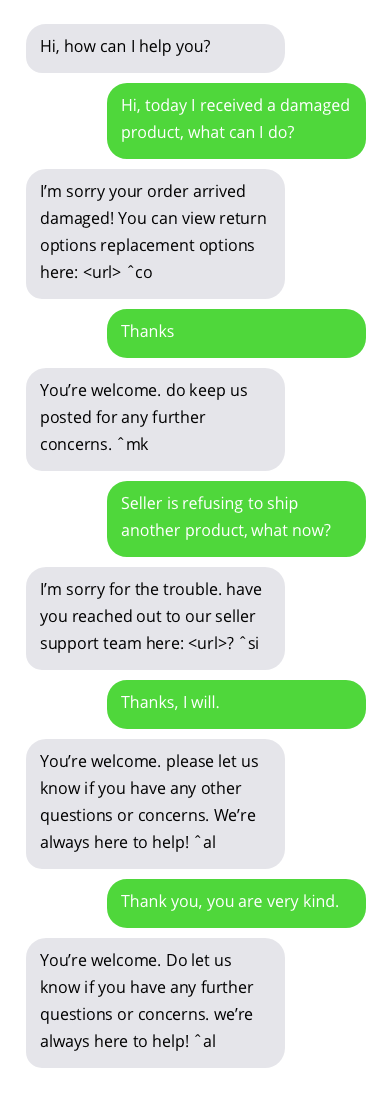
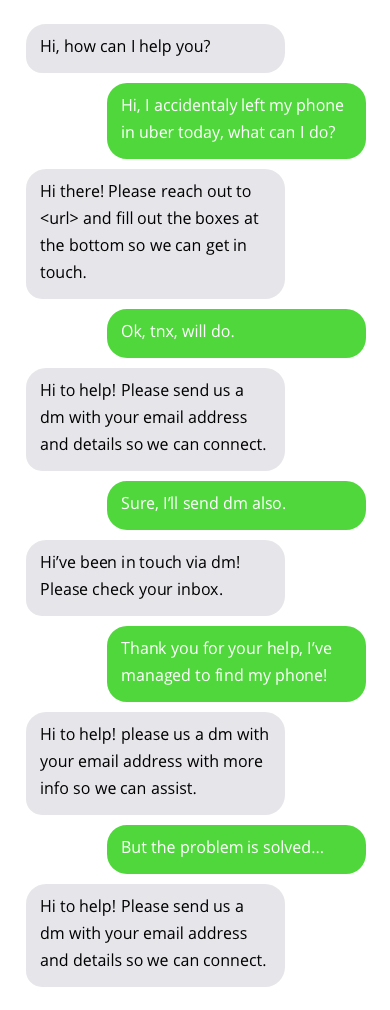
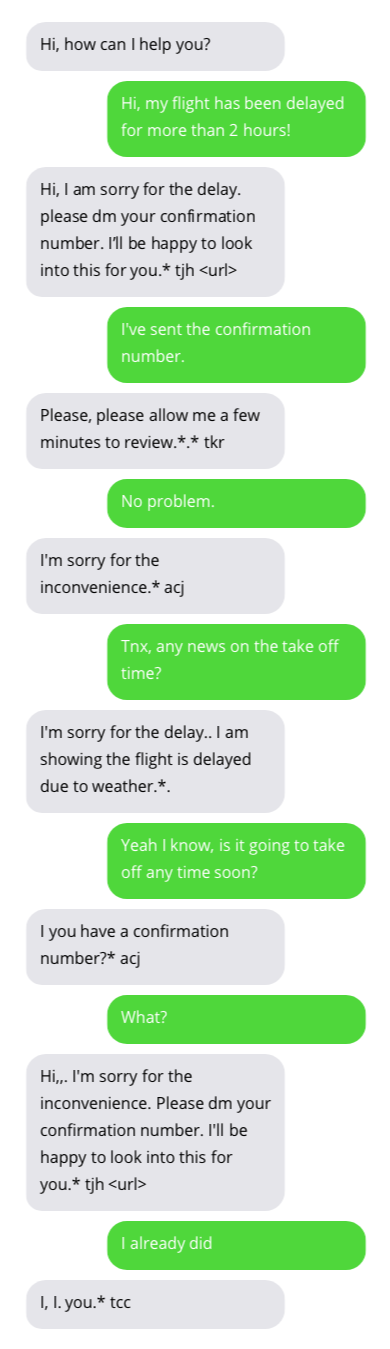
يمكن العثور على مجموعة البيانات المستخدمة لتدريب chatbot هنا. تم إنشاء مجموعة البيانات هذه من خلال جمع المحادثات المتاحة للعامة بين دعم العملاء والمستخدمين على تويتر. شكرا جزيلا لمؤلف مجموعة البيانات!
يمكنك تجربة chatbot باستخدام نماذج مدربة مسبقًا أو عن طريق تدريب chatbot الخاص بك.
pip3 install -r requirements.txt
python3 -m spacy download enقم بتشغيل الأوامر التالية في جذر هذا المستودع لتنزيل برامج الدردشة الآلية لخدمة العملاء المدربة مسبقًا.
wget https://www.dropbox.com/s/ibm49gx1gefpqju/pretrained-models.zip
unzip pretrained-models.zip
rm pretrained-models.zip
sudo chmod +x predict.py يمكنك الآن "التحدث" مع روبوتات الدردشة الخاصة بخدمة العملاء باستخدام البرنامج النصي predict.py . تتوفر روبوتات الدردشة التالية لخدمة العملاء: apple,amazon,uber,delta,spotify . يوضح المثال التالي كيفية تشغيل برنامج chatbot لخدمة عملاء apple :
./predict.py -cs appleيمكنك اختيار تدريب chatbot بنفسك. قم بتشغيل الأوامر التالية لتنزيل وتنسيق مجموعة بيانات Twitter المستخدمة في هذا المشروع:
wget https://www.dropbox.com/s/nmnlcncn7jtb7i9/twcs.zip
unzip twcs.zip
mkdir data
mv twcs.csv data
rm twcs.zip
python3 datasets/twitter_customer_support/format.py # this runs for couple of hours
sudo chmod +x train.pyتحذير سيتم تشغيل هذه الكتلة لبضع ساعات!
يمكنك الآن استخدام train.py لتدريب برنامج chatbot.
يتم استخدام train.py لتدريب برنامج الدردشة الآلي seq2seq.
usage: train.py [-h] [--max-epochs MAX_EPOCHS] [--gradient-clip GRADIENT_CLIP]
[--batch-size BATCH_SIZE] [--learning-rate LEARNING_RATE]
[--train-embeddings] [--save-path SAVE_PATH]
[--save-every-epoch]
[--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}]
[--teacher-forcing-ratio TEACHER_FORCING_RATIO] [--cuda]
[--multi-gpu]
[--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d} | --embedding-size EMBEDDING_SIZE]
[--encoder-rnn-cell {LSTM,GRU}]
[--encoder-hidden-size ENCODER_HIDDEN_SIZE]
[--encoder-num-layers ENCODER_NUM_LAYERS]
[--encoder-rnn-dropout ENCODER_RNN_DROPOUT]
[--encoder-bidirectional] [--decoder-type {bahdanau,luong}]
[--decoder-rnn-cell {LSTM,GRU}]
[--decoder-hidden-size DECODER_HIDDEN_SIZE]
[--decoder-num-layers DECODER_NUM_LAYERS]
[--decoder-rnn-dropout DECODER_RNN_DROPOUT]
[--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE]
[--luong-input-feed]
[--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}]
[--attention-type {none,global,local-m,local-p}]
[--attention-score {dot,general,concat}]
[--half-window-size HALF_WINDOW_SIZE]
[--local-p-hidden-size LOCAL_P_HIDDEN_SIZE]
[--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE]
Script for training seq2seq chatbot.
optional arguments:
-h, --help show this help message and exit
--max-epochs MAX_EPOCHS
Max number of epochs models will be trained.
--gradient-clip GRADIENT_CLIP
Gradient clip value.
--batch-size BATCH_SIZE
Batch size.
--learning-rate LEARNING_RATE
Initial learning rate.
--train-embeddings Should gradients be propagated to word embeddings.
--save-path SAVE_PATH
Folder where models (and other configs) will be saved
during training.
--save-every-epoch Save model every epoch regardless of validation loss.
--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}
Dataset for training model.
--teacher-forcing-ratio TEACHER_FORCING_RATIO
Teacher forcing ratio used in seq2seq models. [0-1]
--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d}
Pre-trained embeddings type.
--embedding-size EMBEDDING_SIZE
Dimensionality of word embeddings.
GPU:
GPU related settings.
--cuda Use cuda if available.
--multi-gpu Use multiple GPUs if available.
Encoder:
Encoder hyperparameters.
--encoder-rnn-cell {LSTM,GRU}
Encoder RNN cell type.
--encoder-hidden-size ENCODER_HIDDEN_SIZE
Encoder RNN hidden size.
--encoder-num-layers ENCODER_NUM_LAYERS
Encoder RNN number of layers.
--encoder-rnn-dropout ENCODER_RNN_DROPOUT
Encoder RNN dropout probability.
--encoder-bidirectional
Use bidirectional encoder.
Decoder:
Decoder hyperparameters.
--decoder-type {bahdanau,luong}
Type of the decoder.
--decoder-rnn-cell {LSTM,GRU}
Decoder RNN cell type.
--decoder-hidden-size DECODER_HIDDEN_SIZE
Decoder RNN hidden size.
--decoder-num-layers DECODER_NUM_LAYERS
Decoder RNN number of layers.
--decoder-rnn-dropout DECODER_RNN_DROPOUT
Decoder RNN dropout probability.
--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE
Luong decoder attention hidden projection size
--luong-input-feed Whether Luong decoder should use input feeding
approach.
--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}
Decoder initial RNN hidden state initialization.
Attention:
Attention hyperparameters.
--attention-type {none,global,local-m,local-p}
Attention type.
--attention-score {dot,general,concat}
Attention score function type.
--half-window-size HALF_WINDOW_SIZE
D parameter from Luong et al. paper. Used only for
local attention.
--local-p-hidden-size LOCAL_P_HIDDEN_SIZE
Local-p attention hidden size (used when predicting
window position).
--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE
Attention layer hidden size. Used only with concat
score function.
يُستخدم predict.py "للتحدث" مع seq2seq chatbot.
usage: predict.py [-h] [-cs {apple,amazon,uber,delta,spotify}] [-p MODEL_PATH]
[-e EPOCH] [--sampling-strategy {greedy,random,beam_search}]
[--max-seq-len MAX_SEQ_LEN] [--cuda]
Script for "talking" with pre-trained chatbot.
optional arguments:
-h, --help show this help message and exit
-cs {apple,amazon,uber,delta,spotify}, --customer-service {apple,amazon,uber,delta,spotify}
-p MODEL_PATH, --model-path MODEL_PATH
Path to directory with model args, vocabulary and pre-
trained pytorch models.
-e EPOCH, --epoch EPOCH
Model from this epoch will be loaded.
--sampling-strategy {greedy,random,beam_search}
Strategy for sampling output sequence.
--max-seq-len MAX_SEQ_LEN
Maximum length for output sequence.
--cuda Use cuda if available.


