LLaMA_MPS
1.0.0
قم بتشغيل استدلال LLaMA (و Stanford-Alpaca) على وحدات معالجة الرسومات Apple Silicon.
كما ترون، على عكس LLMs الأخرى، LLaMA ليس متحيزًا بأي شكل من الأشكال؟
1. استنساخ هذا الريبو
git clone https://github.com/jankais3r/LLaMA_MPS
2. تثبيت تبعيات بايثون
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. قم بتنزيل أوزان النماذج ووضعها في مجلد يسمى models (على سبيل المثال، LLaMA_MPS/models/7B )
4. (اختياري) إعادة تحميل أوزان النموذج (13B/30B/65B)
نظرًا لأننا نقوم بتشغيل الاستدلال على وحدة معالجة رسومات واحدة، فنحن بحاجة إلى دمج أوزان النماذج الأكبر حجمًا في ملف واحد.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. قم بتشغيل الاستدلال
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
ستتيح لك الخطوات المذكورة أعلاه تشغيل الاستدلال على نموذج LLaMA الأولي في وضع "الإكمال التلقائي".
إذا كنت ترغب في تجربة وضع "التعليمات والاستجابة" المشابه لـ ChatGPT باستخدام أوزان Stanford Alpaca المضبوطة بدقة، فتابع الإعداد بالخطوات التالية:
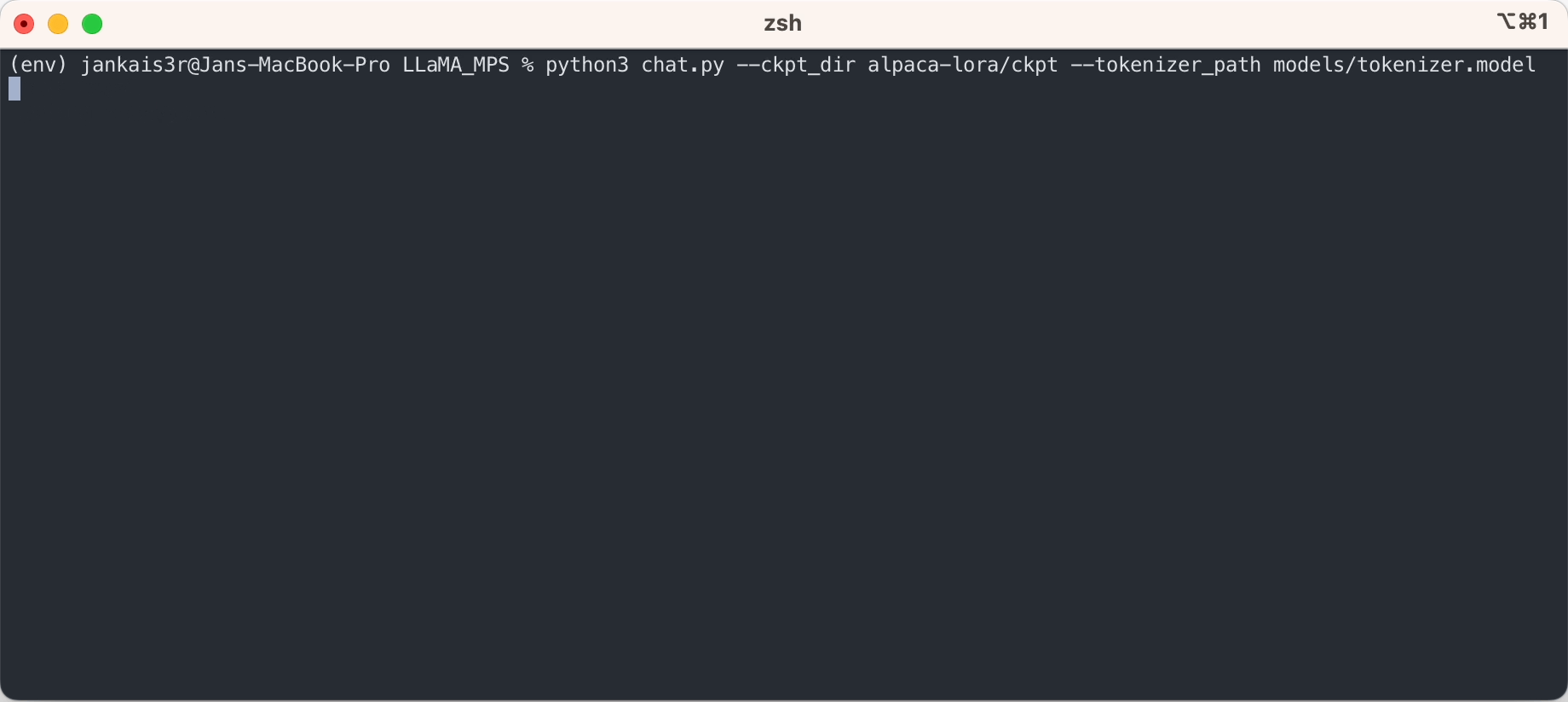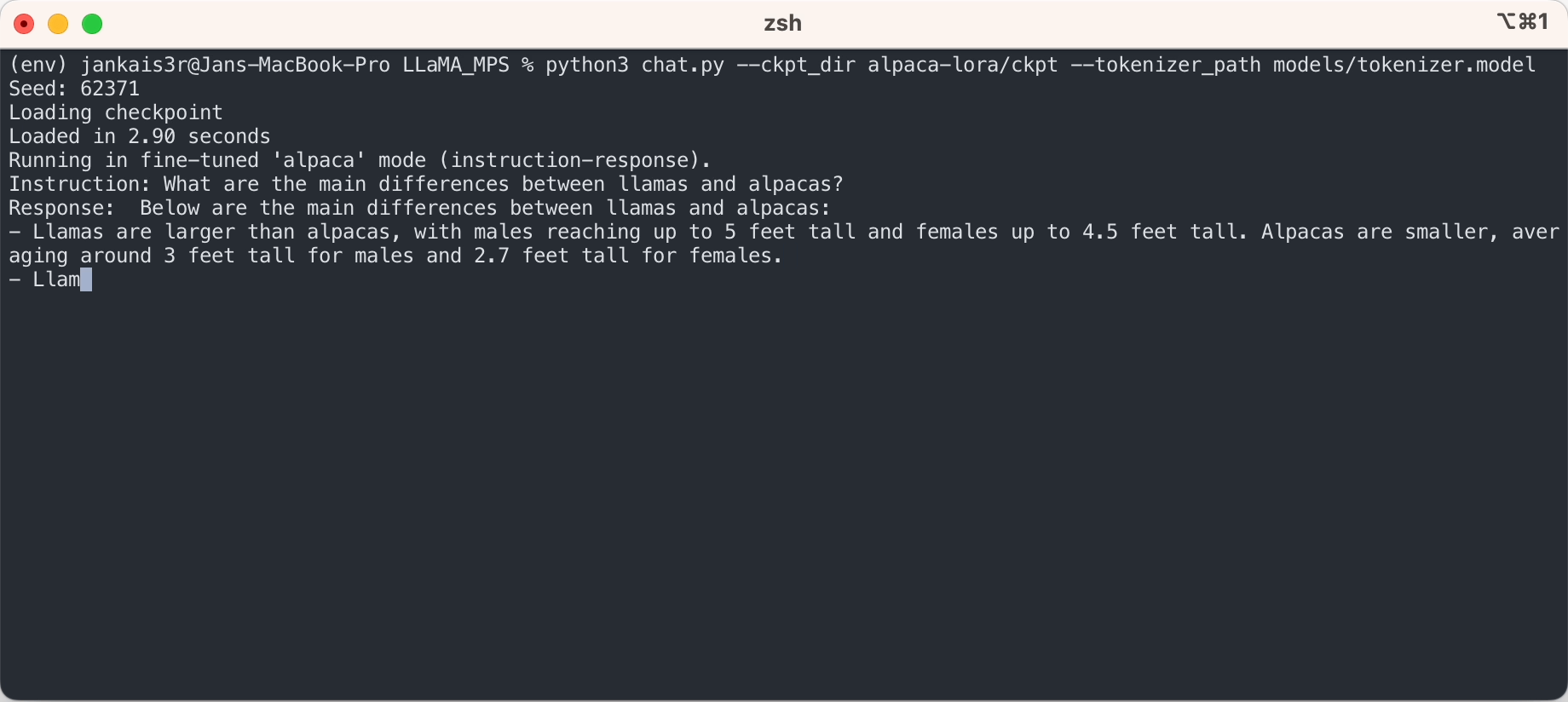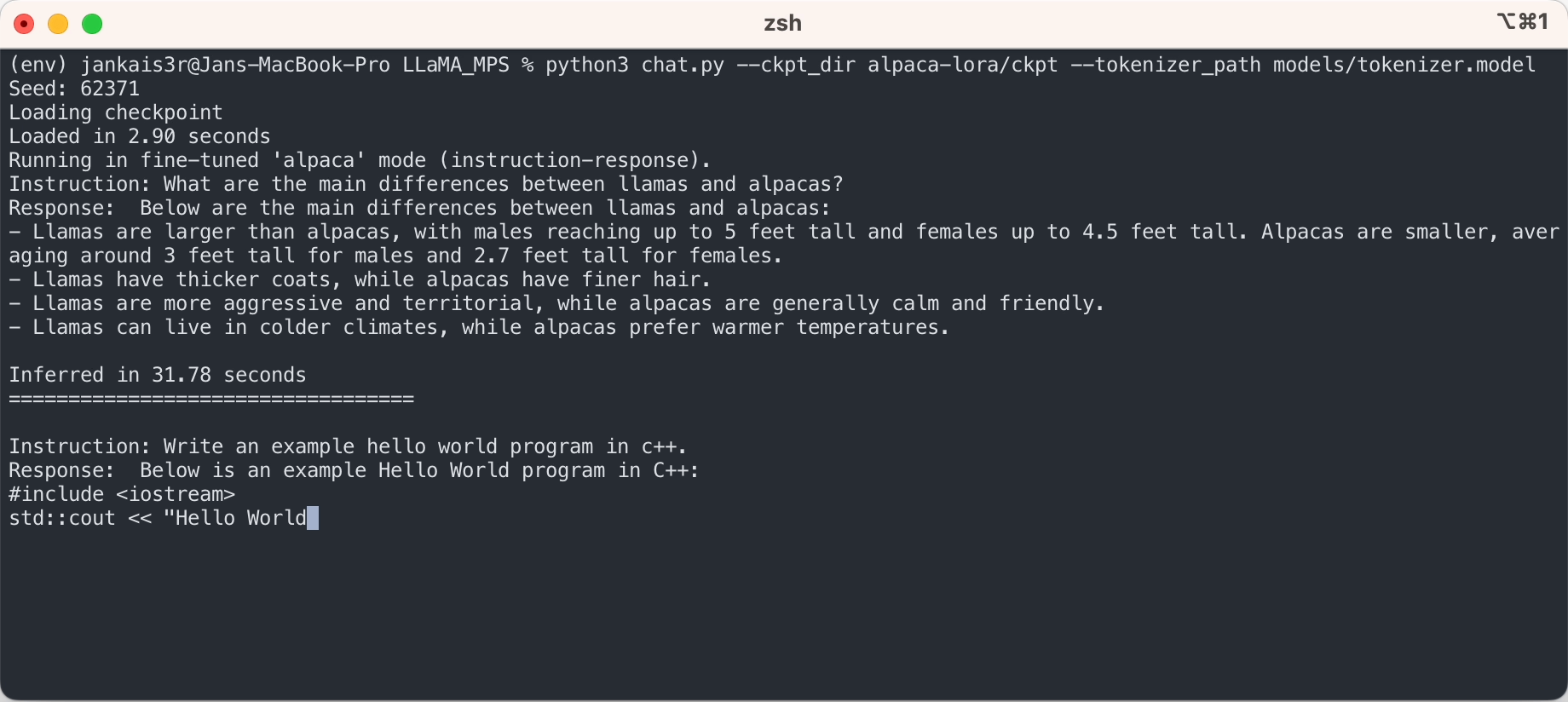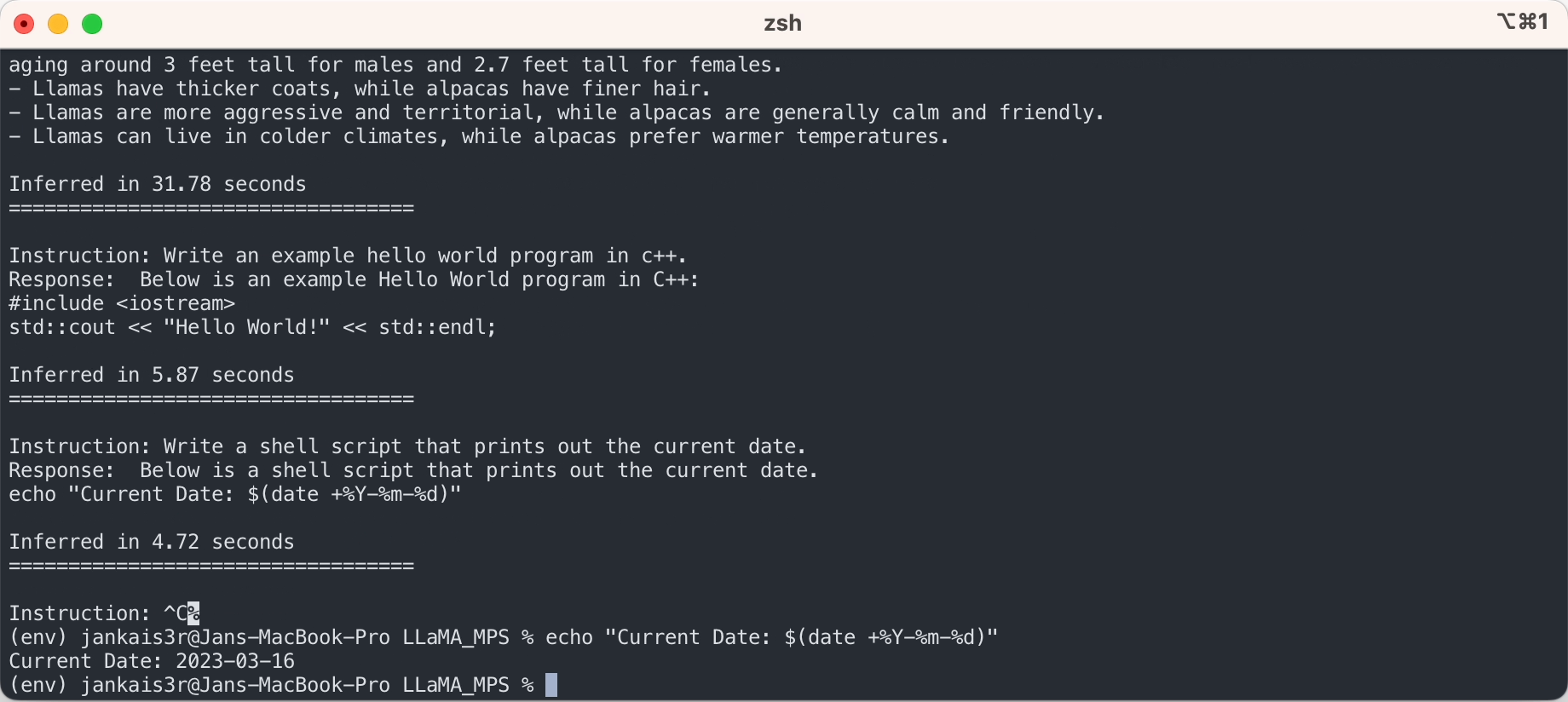
3. قم بتنزيل الأوزان المضبوطة بدقة (متوفرة لـ 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. قم بتشغيل الاستدلال
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| نموذج | بدء الذاكرة أثناء الاستدلال | ذروة الذاكرة أثناء تحويل نقطة التفتيش | ذروة الذاكرة أثناء إعادة التوزيع |
|---|---|---|---|
| 7 ب | 16 جيجابايت | 14 جيجابايت | لا يوجد |
| 13 ب | 32 جيجابايت | 37 جيجابايت | 45 جيجابايت |
| 30 ب | 66 جيجابايت | 76 جيجابايت | 125 جيجابايت |
| 65 ب | ؟؟ غيغابايت | ؟؟ غيغابايت | ؟؟ غيغابايت |
الحد الأدنى من المواصفات لكل طراز (بطيئة بسبب التبديل):
المواصفات الموصى بها لكل نموذج:
- max_batch_size
إذا كانت لديك ذاكرة احتياطية (على سبيل المثال، عند تشغيل الطراز 13B على جهاز Mac بسعة 64 جيجابايت)، فيمكنك زيادة حجم الدفعة باستخدام الوسيطة --max_batch_size=32 . القيمة الافتراضية هي 1 .
- max_seq_len
لزيادة/تقليل الحد الأقصى لطول النص الذي تم إنشاؤه، استخدم الوسيطة --max_seq_len=256 . القيمة الافتراضية هي 512 .
- استخدام_التكرار_عقوبة
يعاقب البرنامج النصي النموذجي النموذج لإنشاء محتوى متكرر. من المفترض أن يؤدي هذا إلى مخرجات ذات جودة أعلى، لكنه يبطئ الاستدلال قليلاً. قم بتشغيل البرنامج النصي باستخدام --use_repetition_penalty=False لتعطيل خوارزمية العقوبة.
أفضل بديل لـ LLaMA_MPS لمستخدمي Apple Silicon هو llama.cpp، وهو إعادة تنفيذ C/C++ يقوم بتشغيل الاستدلال فقط على جزء وحدة المعالجة المركزية في SoC. نظرًا لأن كود C المترجم أسرع بكثير من Python، فيمكنه في الواقع التغلب على تنفيذ MPS هذا في السرعة، ولكن على حساب كفاءة طاقة وحرارة أسوأ بكثير.
راجع المقارنة أدناه عند تحديد التطبيق الذي يناسب حالة الاستخدام الخاصة بك بشكل أفضل.
| تطبيق | إجمالي وقت التشغيل - 256 رمزًا | الرموز/الرموز | ذروة استخدام الذاكرة | ذروة درجة حرارة شركة نفط الجنوب | ذروة استهلاك الطاقة لشركة نفط الجنوب | الرموز لكل 1 واط |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75 ثانية | 3.41 | 30 جيجابايت | 79 درجة مئوية | 10 واط | 1,228.80 |
| llama.cpp (13B fp16) | 70 ثانية | 3.66 | 25 جيجابايت | 106 درجة مئوية | 35 واط | 376.16 |


